U.S. Pat. No. 8,214,306
COMPUTER GAME WITH INTUITIVE LEARNING CAPABILITY
AssigneeIntuition Intelligence, Inc.
Issue DateDecember 5, 2008
Illustrative Figure
Abstract
A computer game and a method of providing learning capability thereto are provided. The computer game has an objective of matching a skill level of the computer game with a skill level of a game player. A move performed by the game player is identified, one of a plurality of game moves is selected based on a game move probability distribution comprising a plurality of probability values corresponding to the plurality of game moves, an outcome of the selected game move relative to the identified player move is determined, the game move probability distribution is updated based on the outcome, and one or more of the game move selection, the outcome determination, and the game move probability distribution update is modified based on the objective.
Description
DETAILED DESCRIPTION OF THE PREFERRED EMBODIMENTS Generalized Single-User Program (Single Processor Action-Single User Action) Referring toFIG. 1, a single-user learning program100developed in accordance with the present inventions can be generally implemented to provide intuitive learning capability to any variety of processing devices, e.g., computers, microprocessors, microcontrollers, embedded systems, network processors, and data processing systems. In this embodiment, a single user105interacts with the program100by receiving a processor action αifrom a processor action set α within the program100, selecting a user action λxfrom a user action set λ based on the received processor action αi, and transmitting the selected user action λxto the program100. It should be noted that in alternative embodiments, the user105need not receive the processor action αito select a user action λx, the selected user action λxneed not be based on the received processor action αi, and/or the processor action αimay be selected in response to the selected user action λx. The significance is that a processor action αiand a user action λxare selected. The program100is capable of learning based on the measured performance of the selected processor action αirelative to a selected user action λx, which, for the purposes of this specification, can be measured as an outcome value β. It should be noted that although an outcome value β is described as being mathematically determined or generated for purposes of understanding the operation of the equations set forth herein, an outcome value β need not actually be determined or generated for practical purposes. Rather, it is only important that the outcome of the processor action αirelative to the user action λxbe known. In alternative embodiments, the program100is capable of learning based on the measured performance of a selected processor action αiand/or selected user action λxrelative to other criteria. As will be described in further detail below, program100directs ...
DETAILED DESCRIPTION OF THE PREFERRED EMBODIMENTS
Generalized Single-User Program (Single Processor Action-Single User Action)
Referring toFIG. 1, a single-user learning program100developed in accordance with the present inventions can be generally implemented to provide intuitive learning capability to any variety of processing devices, e.g., computers, microprocessors, microcontrollers, embedded systems, network processors, and data processing systems. In this embodiment, a single user105interacts with the program100by receiving a processor action αifrom a processor action set α within the program100, selecting a user action λxfrom a user action set λ based on the received processor action αi, and transmitting the selected user action λxto the program100. It should be noted that in alternative embodiments, the user105need not receive the processor action αito select a user action λx, the selected user action λxneed not be based on the received processor action αi, and/or the processor action αimay be selected in response to the selected user action λx. The significance is that a processor action αiand a user action λxare selected.
The program100is capable of learning based on the measured performance of the selected processor action αirelative to a selected user action λx, which, for the purposes of this specification, can be measured as an outcome value β. It should be noted that although an outcome value β is described as being mathematically determined or generated for purposes of understanding the operation of the equations set forth herein, an outcome value β need not actually be determined or generated for practical purposes. Rather, it is only important that the outcome of the processor action αirelative to the user action λxbe known. In alternative embodiments, the program100is capable of learning based on the measured performance of a selected processor action αiand/or selected user action λxrelative to other criteria. As will be described in further detail below, program100directs its learning capability by dynamically modifying the model that it uses to learn based on a performance index φ to achieve one or more objectives.
To this end, the program100generally includes a probabilistic learning module110and an intuition module115. The probabilistic learning module110includes a probability update module120, an action selection module125, and an outcome evaluation module130. Briefly, the probability update module120uses learning automata theory as its learning mechanism with the probabilistic learning module110configured to generate and update an action probability distribution p based on the outcome value β. The action selection module125is configured to pseudo-randomly select the processor action αibased on the probability values contained within the action probability distribution p internally generated and updated in the probability update module120. The outcome evaluation module130is configured to determine and generate the outcome value β based on the relationship between the selected processor action αiand user action λx. The intuition module115modifies the probabilistic learning module110(e.g., selecting or modifying parameters of algorithms used in learning module110) based on one or more generated performance indexes φ to achieve one or more objectives. A performance index φ can be generated directly from the outcome value β or from something dependent on the outcome value β, e.g., the action probability distribution p, in which case the performance index φ may be a function of the action probability distribution p, or the action probability distribution p may be used as the performance index φ. A performance index φ can be cumulative (e.g., it can be tracked and updated over a series of outcome values β or instantaneous (e.g., a new performance index φ can be generated for each outcome value β).
Modification of the probabilistic learning module110can be accomplished by modifying the functionalities of (1) the probability update module120(e.g., by selecting from a plurality of algorithms used by the probability update module120, modifying one or more parameters within an algorithm used by the probability update module120, transforming, adding and subtracting probability values to and from, or otherwise modifying the action probability distribution p); (2) the action selection module125(e.g., limiting or expanding selection of the action α corresponding to a subset of probability values contained within the action probability distribution p); and/or (3) the outcome evaluation module130(e.g., modifying the nature of the outcome value β or otherwise the algorithms used to determine the outcome value β).
Having now briefly discussed the components of the program100, we will now describe the functionality of the program100in more detail. Beginning with the probability update module120, the action probability distribution p that it generates can be represented by the following equation:
p(k)=[p1(k),p2(k),p3(k) . . .pn(k)], [1]where piis the action probability value assigned to a specific processor action αi; n is the number of processor actions αiwithin the processor action set α, and k is the incremental time at which the action probability distribution was updated.
Preferably, the action probability distribution p at every time k should satisfy the following requirement:
∑i=1npi(k)=1,0≤pi(k)≤1.[2]
Thus, the internal sum of the action probability distribution p, i.e., the action probability values pifor all processor actions αiwithin the processor action set α is always equal “1,” as dictated by the definition of probability. It should be noted that the number n of processor actions αineed not be fixed, but can be dynamically increased or decreased during operation of the program100.
The probability update module120uses a stochastic learning automaton, which is an automaton that operates in a random environment and updates its action probabilities in accordance with inputs received from the environment so as to improve its performance in some specified sense. A learning automaton can be characterized in that any given state of the action probability distribution p determines the state of the next action probability distribution p. For example, the probability update module120operates on the action probability distribution p(k) to determine the next action probability distribution p(k+1), i.e., the next action probability distribution p(k+1) is a function of the current action probability distribution p(k). Advantageously, updating of the action probability distribution p using a learning automaton is based on a frequency of the processor actions αiand/or user actions λx, as well as the time ordering of these actions. This can be contrasted with purely operating on a frequency of processor actions αior user actions λx, and updating the action probability distribution p(k) based thereon. Although the present inventions, in their broadest aspects, should not be so limited, it has been found that the use of a learning automaton provides for a more dynamic, accurate, and flexible means of teaching the probabilistic learning module110.
In this scenario, the probability update module120uses a single learning automaton with a single input to a single-teacher environment (with the user105as the teacher), and thus, a single-input, single-output (SISO) model is assumed.
To this end, the probability update module120is configured to update the action probability distribution p based on the law of reinforcement, the basic idea of which is to reward a favorable action and/or to penalize an unfavorable action. A specific processor action αiis rewarded by increasing the corresponding current probability value pi(k) and decreasing all other current probability values pj(k), while a specific processor action αiis penalized by decreasing the corresponding current probability value pi(k) and increasing all other current probability values pj(k). Whether the selected processor action αiis rewarded or punished will be based on the outcome value β generated by the outcome evaluation module130. For the purposes of this specification, an action probability distribution p is updated by changing the probability values piwithin the action probability distribution p, and does not contemplate adding or subtracting probability values pi.
To this end, the probability update module120uses a learning methodology to update the action probability distribution p, which can mathematically be defined as:
p(k+1)=T[p(k),αi(k),β(k)], [3]where p(k+1) is the updated action probability distribution, T is the reinforcement scheme, p(k) is the current action probability distribution, αi(k) is the previous processor action, β(k) is latest outcome value, and k is the incremental time at which the action probability distribution was updated.
Alternatively, instead of using the immediately previous processor action αi(k), any set of previous processor action, e.g., α(k−1), α(k−2), αk−3), etc., can be used for lag learning, and/or a set of future processor action, e.g., α(k+1), α(k+2), α(k+3), etc., can be used for lead learning. In the case of lead learning, a future processor action is selected and used to determine the updated action probability distribution p(k+1).
The types of learning methodologies that can be utilized by the probability update module120are numerous, and depend on the particular application. For example, the nature of the outcome value β can be divided into three types: (1) P-type, wherein the outcome value β can be equal to “1” indicating success of the processor action αi, and “0” indicating failure of the processor action αi; (2) Q-type, wherein the outcome value β can be one of a finite number of values between “0” and “1” indicating a relative success or failure of the processor action αi; or (3) S-Type, wherein the outcome value β can be a continuous value in the interval [0,1] also indicating a relative success or failure of the processor action αi.
The outcome value β, can indicate other types of events besides successful and unsuccessful events. The time dependence of the reward and penalty probabilities of the actions α can also vary. For example, they can be stationary if the probability of success for a processor action αidoes not depend on the index k, and non-stationary if the probability of success for the processor action αidepends on the index k. Additionally, the equations used to update the action probability distribution p can be linear or non-linear. Also, a processor action αican be rewarded only, penalized only, or a combination thereof. The convergence of the learning methodology can be of any type, including ergodic, absolutely expedient, ε-optimal, or optimal. The learning methodology can also be a discretized, estimator, pursuit, hierarchical, pruning, growing or any combination thereof.
Of special importance is the estimator learning methodology, which can advantageously make use of estimator tables and algorithms should it be desired to reduce the processing otherwise requiring for updating the action probability distribution for every processor action αithat is received. For example, an estimator table may keep track of the number of successes and failures for each processor action αireceived, and then the action probability distribution p can then be periodically updated based on the estimator table by, e.g., performing transformations on the estimator table. Estimator tables are especially useful when multiple users are involved, as will be described with respect to the multi-user embodiments described later.
In the preferred embodiment, a reward function gjand a penalization function hjis used to accordingly update the current action probability distribution p(k). For example, a general updating scheme applicable to P-type, Q-type and S-type methodologies can be given by the following SISO equations:
pj(k+1)=pj(k)-β(k)gj(p(k))+(1-β(k))hj(p(k)),ifα(k)≠αi[4]pi(k+1)=pi(k)+β(k)∑j=1j≠ingj(p(k))-(1-β(k))∑j=1j≠inhj(p(k)),ifα(k)=αi[5]where i is an index for a processor action αi, selected to be rewarded or penalized, and j is an index for the remaining processor actions αi.
Assuming a P-type methodology, equations [4] and [5] can be broken down into the following equations:
pi(k+1)=pi(k)+∑j=1j≠ingj(p(k));and[6]pj(k+1)=pj(k)-gj(p(k)),whenβ(k)=1andαiisselected[7]pi(k+1)=pi(k)-∑j=1j≠inhj(p(k));and[8]
pj(k+1)=pj(k)+hj(p(k)), when β(k)=0 and αiis selected [9]
Preferably, the reward function gjand penalty function hjare continuous and nonnegative for purposes of mathematical convenience and to maintain the reward and penalty nature of the updating scheme. Also, the reward function gjand penalty function hjare preferably constrained by the following equations to ensure that all of the components of p(k+1) remain in the (0,1) interval when p(k) is in the (0,1) interval:
0<gi(p)<pj;0<∑j≠in(pj+hj(p))<1
for all pjε(0,1) and all j=1, 2, . . . n.
The updating scheme can be of the reward-penalty type, in which case, both gjand hjare non-zero. Thus, in the case of a P-type methodology, the first two updating equations [6] and [7] will be used to reward the processor action αi, e.g., when successful, and the last two updating equations [8] and [9] will be used to penalize processor action αi, e.g., when unsuccessful. Alternatively, the updating scheme is of the reward-inaction type, in which case, gjis nonzero and hjis zero. Thus, the first two general updating equations [6] and [7] will be used to reward the processor action αi, e.g., when successful, whereas the last two general updating equations [8] and [9] will not be used to penalize processor action αi, e.g., when unsuccessful. More alternatively, the updating scheme is of the penalty-inaction type, in which case, gjis zero and hjis nonzero. Thus, the first two general updating equations [6] and [7] will not be used to reward the processor action αi, e.g., when successful, whereas the last two general updating equations [8] and [9] will be used to penalize processor action αi, e.g., when unsuccessful. The updating scheme can even be of the reward-reward type (in which case, the processor action αiis rewarded more, e.g., when it is more successful than when it is not) or penalty-penalty type (in which case, the processor action αiis penalized more, e.g., when it is less successful than when it is).
It should be noted that with respect to the probability distribution p as a whole, any typical updating scheme will have both a reward aspect and a penalty aspect to the extent that a particular processor action αithat is rewarded will penalize the remaining processor actions αi, and any particular processor action αithat penalized will reward the remaining processor actions αi. This is because any increase in a probability value piwill relatively decrease the remaining probability values pi, and any decrease in a probability value piwill relatively increase the remaining probability values pi. For the purposes of this specification, however, a particular processor action αiis only rewarded if its corresponding probability value piis increased in response to an outcome value β associated with it, and a processor action αiis only penalized if its corresponding probability value piis decreased in response to an outcome value β associated with it.
The nature of the updating scheme is also based on the functions gjand hjthemselves. For example, the functions gjand hjcan be linear, in which case, e.g., they can be characterized by the following equations:
gj(p(k))=apj(k),0<a<1;and[10]hj(p(k))=bn-1-bpj(k),0<b<1[11]
where α is the reward parameter, and b is the penalty parameter.
The functions gjand hjcan alternatively be absolutely expedient, in which case, e.g., they can be characterized by the following equations:
g1(p)p1=g2(p)p2=…=gn(p)pn;[12]h1(p)p1=h2(p)p2=…=hn(p)pn[13]
The functions gjand hjcan alternatively be non-linear, in which case, e.g., they can be characterized by the following equations:
gj(p(k))=pj(k)-F(pj(k));[14]hj(p(k))=pi(k)-F(pi(k))n-1[15]
and F(x)=axm, m=2, 3, . . . .
It should be noted that equations [4] and [5] are not the only general equations that can be used to update the current action probability distribution p(k) using a reward function gjand a penalization function hj. For example, another general updating scheme applicable to P-type, Q-type and S-type methodologies can be given by the following SISO equations:
pj(k+1)=pj(k)−β(k)cjgi(p(k))+(1−β(k)djhi(p(k)), if α(k)≠αi[16]
pi(k+1)=pi(k)+β(k)gi(p(k))−(1−β(k))hi(p(k)), if α(k)=αi[17]where c and d are constant or variable distribution multipliers that adhere to the following constraints:
∑j=1i≠jncjgi(p(k))=gi(p(k));∑j=1i≠jndjhi(p(k))=hi(p(k))
In other words, the multipliers c and d are used to determine what proportions of the amount that is added to or subtracted from the probability value piis redistributed to the remaining probability values pj.
Assuming a P-type methodology, equations [16] and [17] can be broken down into the following equations:
pi(k+1)=pi(k)+gi(p(k)); and [18]
pi(k+1)=pj(k)−cjgi(p(k)), when β(k)=1 and αiis selected [19]
pi(k+1)=pi(k)−hi(p(k)); and [20]
pj(k+1)=pj(k)+djhi(p(k)), when β(k)=0and αiis selected [21]
It can be appreciated that equations [4]-[5] and [16]-[17] are fundamentally similar to the extent that the amount that is added to or subtracted from the probability value piis subtracted from or added to the remaining probability values pj. The fundamental difference is that, in equations [4]-[5], the amount that is added to or subtracted from the probability value piis based on the amounts that are subtracted from or added to the remaining probability values pj(i.e., the amounts added to or subtracted from the remaining probability values pjare calculated first), whereas in equations [16]-[17], the amounts that are added to or subtracted from the remaining probability values pjare based on the amount that is subtracted from or added to the probability value pi(i.e., the amount added to or subtracted from the probability value piis calculated first). It should also be noted that equations [4]-[5] and [16]-[17] can be combined to create new learning methodologies. For example, the reward portions of equations [4]-[5] can be used when an action αiis to be rewarded, and the penalty portions of equations [16]-[17] can be used when an action αiis to be penalized.
Previously, the reward and penalty functions gjand hiand multipliers cjand djhave been described as being one-dimensional with respect to the current action αithat is being rewarded or penalized. That is, the reward and penalty functions gjand hjand multipliers cjand djare the same given any action αi. It should be noted, however, that multi-dimensional reward and penalty functions gijand hijand multipliers cijand dijcan be used.
In this case, the single dimensional reward and penalty functions gjand hjof equations [6]-[9] can be replaced with the two-dimensional reward and penalty functions gijand hij, resulting in the following equations:
pi(k+1)=pi(k)+∑j=1j≠ingij(p(k));and[6a]pj(k+1)=pj(k)-gij(p(k)),whenβ(k)=1andαiisselected[7a]pi(k+1)=pi(k)-∑j=1j≠inhij(p(k));and[8a]pj(k+1)=pj(k)+hij(p(k)),whenβ(k)=0andαiisselected[9a]
The single dimensional multipliers cjand djof equations [19] and [21] can be replaced with the two-dimensional multipliers cijand dij, resulting in the following equations:
pj(k+1)=pj(k)−cijgi(p(k)), when β(k)=1 and αiis selected [19a]
pj(k+1)=pj(k)+dijhi(p(k)), when β(k)=0and αiis selected [21a]
Thus, it can be appreciated, that equations [19a] and [21a] can be expanded into many different learning methodologies based on the particular action αithat has been selected.
Further details on learning methodologies are disclosed in “Learning Automata An Introduction,” Chapter 4, Narendra, Kumpati, Prentice Hall (1989) and “Learning Algorithms-Theory and Applications in Signal Processing, Control and Communications,” Chapter 2, Mars, Phil, CRC Press (1996), which are both expressly incorporated herein by reference.
The intuition module115directs the learning of the program100towards one or more objectives by dynamically modifying the probabilistic learning module110. The intuition module115specifically accomplishes this by operating on one or more of the probability update module120, action selection module125, or outcome evaluation module130based on the performance index φ, which, as briefly stated, is a measure of how well the program100is performing in relation to the one or more objective to be achieved. The intuition module115may, e.g., take the form of any combination of a variety of devices, including an (1) evaluator, data miner, analyzer, feedback device, stabilizer; (2) decision maker; (3) expert or rule-based system; (4) artificial intelligence, fuzzy logic, neural network, or genetic methodology; (5) directed learning device; (6) statistical device, estimator, predictor, regressor, or optimizer. These devices may be deterministic, pseudo-deterministic, or probabilistic.
It is worth noting that absent modification by the intuition module115, the probabilistic learning module110would attempt to determine a single best action or a group of best actions for a given predetermined environment as per the objectives of basic learning automata theory. That is, if there is a unique action that is optimal, the unmodified probabilistic learning module110will substantially converge to it. If there is a set of actions that are optimal, the unmodified probabilistic learning module110will substantially converge to one of them, or oscillate (by pure happenstance) between them. In the case of a changing environment, however, the performance of an unmodified learning module110would ultimately diverge from the objectives to be achieved.FIGS. 2 and 3are illustrative of this point. Referring specifically toFIG. 2, a graph illustrating the action probability values piof three different actions α1, α2, and α3, as generated by a prior art learning automaton over time t, is shown. As can be seen, the action probability values pifor the three actions are equal at the beginning of the process, and meander about on the probability plane p, until they eventually converge to unity for a single action, in this case, α1. Thus, the prior art learning automaton assumes that there is always a single best action over time t and works to converge the selection to this best action. Referring specifically toFIG. 3, a graph illustrating the action probability values piof three different actions α1, α2, and α3, as generated by the program100over time t, is shown. Like with the prior art learning automaton, action probability values pifor the three action are equal at t=0. Unlike with the prior art learning automaton, however, the action probability values pifor the three actions meander about on the probability plane p without ever converging to a single action. Thus, the program100does not assume that there is a single best action over time t, but rather assumes that there is a dynamic best action that changes over time t. Because the action probability value for any best action will not be unity, selection of the best action at any given time t is not ensured, but will merely tend to occur, as dictated by its corresponding probability value. Thus, the program100ensures that the objective(s) to be met are achieved over time t.
Having now described the interrelationships between the components of the program100and the user105, we now generally describe the methodology of the program100. Referring toFIG. 4, the action probability distribution p is initialized (step150). Specifically, the probability update module120initially assigns equal probability values to all processor actions αi, in which case, the initial action probability distribution p(k) can be represented by
p1(0)=p2(0)=p2(0)=…pn(0)=1n.
Thus, each of the processor actions αihas an equal chance of being selected by the action selection module125. Alternatively, the probability update module120initially assigns unequal probability values to at least some of the processor actions αi, e.g., if the programmer desires to direct the learning of the program100towards one or more objectives quicker. For example, if the program100is a computer game and the objective is to match a novice game player's skill level, the easier processor action αi, and in this case game moves, may be assigned higher probability values, which as will be discussed below, will then have a higher probability of being selected. In contrast, if the objective is to match an expert game player's skill level, the more difficult game moves may be assigned higher probability values.
Once the action probability distribution p is initialized at step150, the action selection module125determines if a user action λxhas been selected from the user action set λ (step155). If not, the program100does not select a processor action αifrom the processor action set α (step160), or alternatively selects a processor action αi, e.g., randomly, notwithstanding that a user action λxhas not been selected (step165), and then returns to step155where it again determines if a user action λxhas been selected. If a user action λxhas been selected at step155, the action selection module125determines the nature of the selected user action λx, i.e., whether the selected user action λxis of the type that should be countered with a processor action αiand/or whether the performance index φ can be based, and thus whether the action probability distribution p should be updated. For example, again, if the program100is a game program, e.g., a shooting game, a selected user action λxthat merely represents a move may not be a sufficient measure of the performance index φ, but should be countered with a processor action αi, while a selected user action λxthat represents a shot may be a sufficient measure of the performance index φ.
Specifically, the action selection module125determines whether the selected user action λxis of the type that should be countered with a processor action αi(step170). If so, the action selection module125selects a processor action αifrom the processor action set α based on the action probability distribution p (step175). After the performance of step175or if the action selection module125determines that the selected user action λxis not of the type that should be countered with a processor action αi, the action selection module125determines if the selected user action λxis of the type that the performance index φ is based on (step180).
If so, the outcome evaluation module130quantifies the performance of the previously selected processor action αi(or a more previous selected processor action αiin the case of lag learning or a future selected processor action αiin the case of lead learning) relative to the currently selected user action λxby generating an outcome value β (step185). The intuition module115then updates the performance index φ based on the outcome value β, unless the performance index φ is an instantaneous performance index that is represented by the outcome value β itself (step190). The intuition module115then modifies the probabilistic learning module110by modifying the functionalities of the probability update module120, action selection module125, or outcome evaluation module130(step195). It should be noted that step190can be performed before the outcome value β is generated by the outcome evaluation module130at step180, e.g., if the intuition module115modifies the probabilistic learning module110by modifying the functionality of the outcome evaluation module130. The probability update module120then, using any of the updating techniques described herein, updates the action probability distribution p based on the generated outcome value β (step198).
The program100then returns to step155to determine again whether a user action λxhas been selected from the user action set λ. It should be noted that the order of the steps described inFIG. 4may vary depending on the specific application of the program100.
Single-Player Game Program (Single Game Move-Single Player Move)
Having now generally described the components and functionality of the learning program100, we now describe one of its various applications. Referring toFIG. 5, a single-player game program300(shown inFIG. 8) developed in accordance with the present inventions is described in the context of a duck hunting game200. The game200comprises a computer system205, which, e.g., takes the form of a personal desktop or laptop computer. The computer system205includes a computer screen210for displaying the visual elements of the game200to a player215, and specifically, a computer animated duck220and a gun225, which is represented by a mouse cursor. For the purposes of this specification, the duck220and gun225can be broadly considered to be computer and user-manipulated objects, respectively. The computer system205further comprises a computer console250, which includes memory230for storing the game program300, and a CPU235for executing the game program300. The computer system205further includes a computer mouse240with a mouse button245, which can be manipulated by the player215to control the operation of the gun225, as will be described immediately below. It should be noted that although the game200has been illustrated as being embodied in a standard computer, it can very well be implemented in other types of hardware environments, such as a video game console that receives video game cartridges and connects to a television screen, or a video game machine of the type typically found in video arcades.
Referring specifically to the computer screen210ofFIGS. 6 and 7, the rules and objective of the duck hunting game200will now be described. The objective of the player215is to shoot the duck220by moving the gun225towards the duck220, intersecting the duck220with the gun225, and then firing the gun225(FIG. 6). The player215accomplishes this by laterally moving the mouse240, which correspondingly moves the gun225in the direction of the mouse movement, and clicking the mouse button245, which fires the gun225. The objective of the duck220, on the other hand, is to avoid from being shot by the gun225. To this end, the duck220is surrounded by a gun detection region270, the breach of which by the gun225prompts the duck220to select and make one of seventeen moves255(eight outer moves255a, eight inner moves255b, and a non-move) after a preprogrammed delay (move3inFIG. 7). The length of the delay is selected, such that it is not so long or short as to make it too easy or too difficult to shoot the duck220. In general, the outer moves255amore easily evade the gun225than the inner moves255b, thus, making it more difficult for the player215to shot the duck220.
For purposes of this specification, the movement and/or shooting of the gun225can broadly be considered to be a player move, and the discrete moves of the duck220can broadly be considered to be computer or game moves, respectively. Optionally or alternatively, different delays for a single move can also be considered to be game moves. For example, a delay can have a low and high value, a set of discrete values, or a range of continuous values between two limits. The game200maintains respective scores260and265for the player215and duck220. To this end, if the player215shoots the duck220by clicking the mouse button245while the gun225coincides with the duck220, the player score260is increased. In contrast, if the player215fails to shoot the duck220by clicking the mouse button245while the gun225does not coincide with the duck220, the duck score265is increased. The increase in the score can be fixed, one of a multitude of discrete values, or a value within a continuous range of values.
As will be described in further detail below, the game200increases its skill level by learning the player's215strategy and selecting the duck's220moves based thereon, such that it becomes more difficult to shoot the duck220as the player215becomes more skillful. The game200seeks to sustain the player's215interest by challenging the player215. To this end, the game200continuously and dynamically matches its skill level with that of the player215by selecting the duck's220moves based on objective criteria, such as, e.g., the difference between the respective player and game scores260and265. In other words, the game200uses this score difference as a performance index φ in measuring its performance in relation to its objective of matching its skill level with that of the game player. In the regard, it can be said that the performance index φ is cumulative. Alternatively, the performance index φ can be a function of the game move probability distribution p.
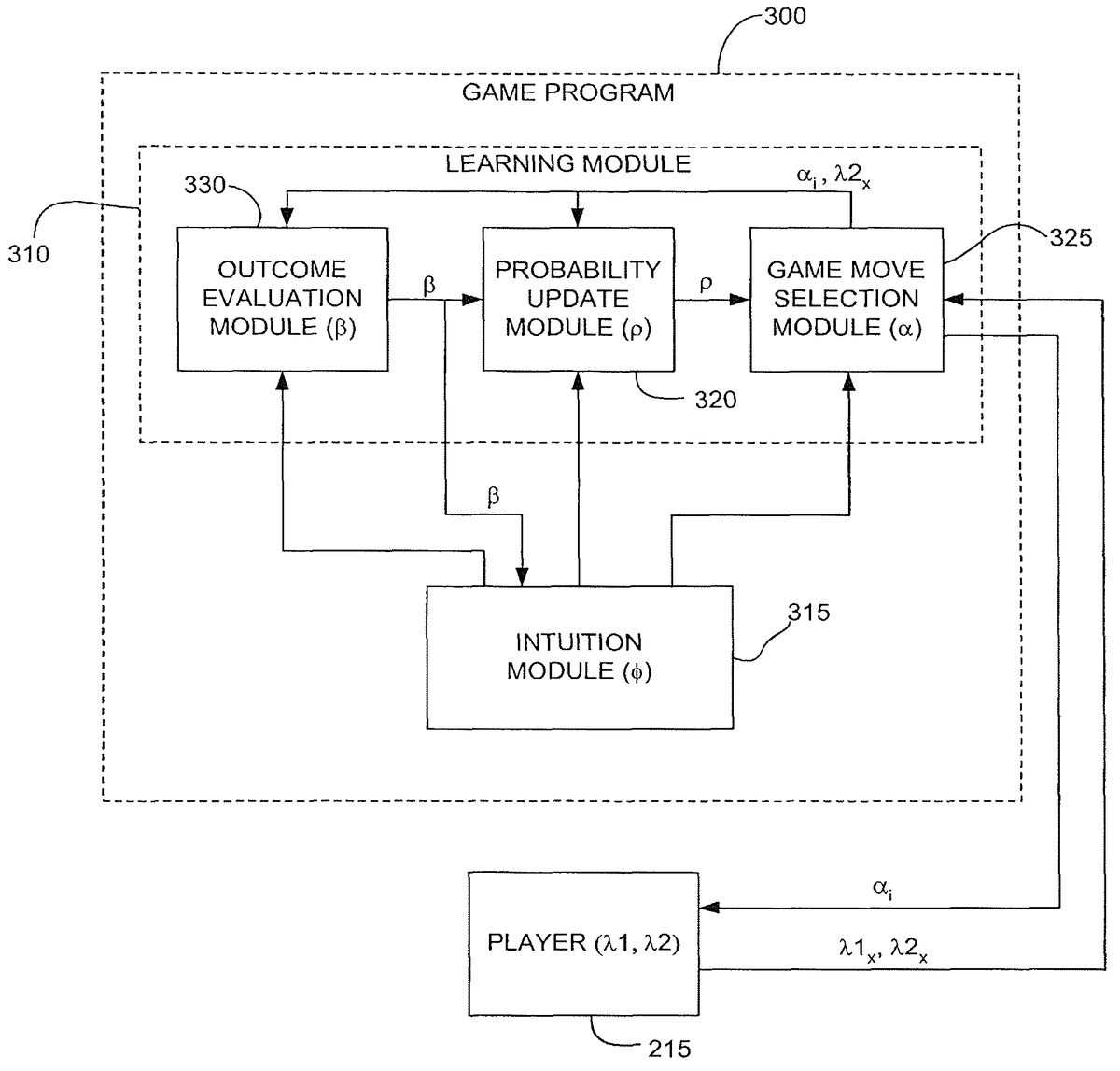
Referring further toFIG. 8, the game program300generally includes a probabilistic learning module310and an intuition module315, which are specifically tailored for the game200. The probabilistic learning module310comprises a probability update module320, a game move selection module325, and an outcome evaluation module330. Specifically, the probability update module320is mainly responsible for learning the player's215strategy and formulating a counterstrategy based thereon, with the outcome evaluation module330being responsible for evaluating moves performed by the game200relative to moves performed by the player215. The game move selection module325is mainly responsible for using the updated counterstrategy to move the duck220in response to moves by the gun225. The intuition module315is responsible for directing the learning of the game program300towards the objective, and specifically, dynamically and continuously matching the skill level of the game200with that of the player215. In this case, the intuition module315operates on the game move selection module325, and specifically selects the methodology that the game move selection module325will use to select a game move αifrom the game move set α as will be discussed in further detail below. In the preferred embodiment, the intuition module315can be considered deterministic in that it is purely rule-based. Alternatively, however, the intuition module315can take on a probabilistic nature, and can thus be quasi-deterministic or entirely probabilistic.
To this end, the game move selection module325is configured to receive a player move λ1xfrom the player215, which takes the form of a mouse240position, i.e., the position of the gun225, at any given time. In this embodiment, the player move λ1xcan be selected from a virtually infinite player move set λ1, i.e., the number of player moves λ1xare only limited by the resolution of the mouse240. Based on this, the game move selection module325detects whether the gun225is within the detection region270, and if so, selects a game move αifrom the game move set α, and specifically, one of the seventeen moves255that the duck220can make. The game move αimanifests itself to the player215as a visible duck movement.
The game move selection module325selects the game move αibased on the updated game strategy. To this end, the game move selection module325is further configured to receive the game move probability distribution p from the probability update module320, and pseudo-randomly selecting the game move αibased thereon. The game move probability distribution p is similar to equation [1] and can be represented by the following equation:
p(k)=[p1(k),p2(k),p3(k) . . .pn(k)], [1-1]where piis the game move probability value assigned to a specific game move αi; n is the number of game moves αiwithin the game move set α, and k is the incremental time at which the game move probability distribution was updated.
It is noted that pseudo-random selection of the game move αiallows selection and testing of any one of the game moves αi, with those game moves αicorresponding to the highest probability values being selected more often. Thus, without the modification, the game move selection module325will tend to more often select the game move αito which the highest probability value picorresponds, so that the game program300continuously improves its strategy, thereby continuously increasing its difficulty level.
Because the objective of the game200is sustainability, i.e., dynamically and continuously matching the respective skill levels of the game200and player215, the intuition module315is configured to modify the functionality of the game move selection module325based on the performance index φ, and in this case, the current skill level of the player215relative to the current skill level of the game200. In the preferred embodiment, the performance index φ is quantified in terms of the score difference value Δ between the player score260and the duck score265. The intuition module315is configured to modify the functionality of the game move selection module325by subdividing the game move set α into a plurality of game move subsets αs, one of which will be selected by the game move selection module325. In an alternative embodiment, the game move selection module325may also select the entire game move set α. In another alternative embodiment, the number and size of the game move subsets αscan be dynamically determined.
In the preferred embodiment, if the score difference value Δ is substantially positive (i.e., the player score260is substantially higher than the duck score265), the intuition module315will cause the game move selection module325to select a game move subset αs, the corresponding average probability value of which will be relatively high, e.g., higher than the median probability value of the game move probability distribution p. As a further example, a game move subset αscorresponding to the highest probability values within the game move probability distribution p can be selected. In this manner, the skill level of the game200will tend to quickly increase in order to match the player's215higher skill level.
If the score difference value Δ is substantially negative (i.e., the player score260is substantially lower than the duck score265), the intuition module315will cause the game move selection module325to select a game move subset αs, the corresponding average probability value of which will be relatively low, e.g., lower than the median probability value of the game move probability distribution p. As a further example, a game move subset αs, corresponding to the lowest probability values within the game move probability distribution p can be selected. In this manner, the skill level of the game200will tend to quickly decrease in order to match the player's215lower skill level.
If the score difference value Δ is substantially low, whether positive or negative (i.e., the player score260is substantially equal to the duck score265), the intuition module315will cause the game move selection module325to select a game move subset αs, the average probability value of which will be relatively medial, e.g., equal to the median probability value of the game move probability distribution p. In this manner, the skill level of the game200will tend to remain the same, thereby continuing to match the player's215skill level. The extent to which the score difference value Δ is considered to be losing or winning the game200may be provided by player feedback and the game designer.
Alternatively, rather than selecting a game move subset αs, based on a fixed reference probability value, such as the median probability value of the game move probability distribution p, selection of the game move set αscan be based on a dynamic reference probability value that moves relative to the score difference value Δ. To this end, the intuition module315increases and decreases the dynamic reference probability value as the score difference value Δ becomes more positive or negative, respectively. Thus, selecting a game move subset αs, the corresponding average probability value of which substantially coincides with the dynamic reference probability value, will tend to match the skill level of the game200with that of the player215. Without loss of generality, the dynamic reference probability value can also be learning using the learning principles disclosed herein.
In the illustrated embodiment, (1) if the score difference value Δ is substantially positive, the intuition module315will cause the game move selection module325to select a game move subset αscomposed of the top five corresponding probability values; (2) if the score difference value Δ is substantially negative, the intuition module315will cause the game move selection module325to select a game move subset αscomposed of the bottom five corresponding probability values; and (3) if the score difference value Δ is substantially low, the intuition module315will cause the game move selection module325to select a game move subset αscomposed of the middle seven corresponding probability values, or optionally a game move subset αscomposed of all seventeen corresponding probability values, which will reflect a normal game where all game moves are available for selection.
Whether the reference probability value is fixed or dynamic, hysteresis is preferably incorporated into the game move subset αsselection process by comparing the score difference value Δ to upper and lower score difference thresholds NS1and NS2, e.g., −1000 and 1000, respectively. Thus, the intuition module315will cause the game move selection module325to select the game move subset αsin accordance with the following criteria:If ΔNS2, then select game move subset αswith relatively high probability values; andIf NS1≦Δ≦NS2, then select game move subset αswith relatively medial probability values.
Alternatively, rather than quantify the relative skill level of the player215in terms of the score difference value Δ between the player score260and the duck score265, as just previously discussed, the relative skill level of the player215can be quantified from a series (e.g., ten) of previous determined outcome values β. For example, if a high percentage of the previous determined outcome values β is equal to “0,” indicating a high percentage of unfavorable game moves αi, the relative player skill level can be quantified as be relatively high. In contrast, if a low percentage of the previous determined outcome values β is equal to 0, indicating a low percentage of unfavorable game moves αi, the relative player skill level can be quantified as be relatively low. Thus, based on this information, a game move αican be pseudo-randomly selected, as hereinbefore described.
The game move selection module325is configured to pseudo-randomly select a single game move αifrom the game move subset αs, thereby minimizing a player detectable pattern of game move αiselections, and thus increasing interest in the game200. Such pseudo-random selection can be accomplished by first normalizing the game move subset αsand then summing, for each game move αiwithin the game move subset αs, the corresponding probability value with the preceding probability values (for the purposes of this specification, this is considered to be a progressive sum of the probability values). For example, the following Table 1 sets forth the unnormalized probability values, normalized probability values, and progressive sum of an exemplary subset of five game moves:
TABLE 1Progressive Sum of Probability Values For Five ExemplaryGame Moves in SISO FormatUnnormalizedNormalizedProgressiveGame MoveProbability ValueProbability ValueSumα10.050.090.09α20.050.090.18α30.100.180.36α40.150.270.63α50.200.371.00
The game move selection module325then selects a random number between “0” and “1,” and selects the game move αicorresponding to the next highest progressive sum value. For example, if the randomly selected number is 0.38, game move α4will be selected.
The game move selection module325is further configured to receive a player move λ2xfrom the player215in the form of a mouse button245click/mouse240position combination, which indicates the position of the gun225when it is fired. The outcome evaluation module330is configured to determine and output an outcome value β that indicates how favorable the game move αiis in comparison with the received player move λ2x.
To determine the extent of how favorable a game move αiis, the outcome evaluation module330employs a collision detection technique to determine whether the duck's220last move was successful in avoiding the gunshot. Specifically, if the gun225coincides with the duck220when fired, a collision is detected. On the contrary, if the gun225does not coincide with the duck220when fired, a collision is not detected. The outcome of the collision is represented by a numerical value, and specifically, the previously described outcome value β. In the illustrated embodiment, the outcome value β equals one of two predetermined values: “1” if a collision is not detected (i.e., the duck220is not shot), and “0” if a collision is detected (i.e., the duck220is shot). Of course, the outcome value β can equal “0” if a collision is not detected, and “1” if a collision is detected, or for that matter one of any two predetermined values other than a “0” or “1,” without straying from the principles of the invention. In any event, the extent to which a shot misses the duck220(e.g., whether it was a near miss) is not relevant, but rather that the duck220was or was not shot. Alternatively, the outcome value β can be one of a range of finite integers or real numbers, or one of a range of continuous values. In these cases, the extent to which a shot misses or hits the duck220is relevant. Thus, the closer the gun225comes to shooting the duck220, the less the outcome value β is, and thus, a near miss will result in a relatively low outcome value β, whereas a far miss will result in a relatively high outcome value β. Of course, alternatively, the closer the gun225comes to shooting the duck220, the greater the outcome value β is. What is significant is that the outcome value β correctly indicates the extent to which the shot misses the duck220. More alternatively, the extent to which a shot hits the duck220is relevant. Thus, the less damage the duck220incurs, the less the outcome value β is, and the more damage the duck220incurs, the greater the outcome value β is.
The probability update module320is configured to receive the outcome value β from the outcome evaluation module330and output an updated game strategy (represented by game move probability distribution p) that the duck220will use to counteract the player's215strategy in the future. In the preferred embodiment, the probability update module320utilizes a linear reward-penalty P-type update. As an example, given a selection of the seventeen different moves255, assume that the gun125fails to shoot the duck120after it takes game move α3, thus creating an outcome value β=1. In this case, general updating equations [6] and [7] can be expanded using equations [10] and [11], as follows:
p3(k+1)=p3(k)+∑j=1j≠317apj(k);p1(k+1)=p1(k)-ap1(k);p2(k+1)=p2(k)-ap2(k);p4(k+1)=p4(k)-ap4(k);⋮p17(k+1)=p17(k)-ap17(k)
Thus, since the game move α3resulted in a successful outcome, the corresponding probability value p3is increased, and the game move probability values picorresponding to the remaining game moves αiare decreased.
If, on the other hand, the gun125shoots the duck120after it takes game move α3, thus creating an outcome value β=0, general updating equations [8] and [9] can be expanded, using equations [10] and [11], as follows:
p3(k+1)=p3(k)-∑j=1j≠317(b16-bpj(k))p1(k+1)=p1(k)+b16-bp1(k);p2(k+1)=p2(k)+b16-bp2(k);p4(k+1)=p4(k)+b16-bp4(k);⋮p17(k+1)=p17(k)+b16-bp17(k)
It should be noted that in the case where the gun125shoots the duck120, thus creating an outcome value β=0, rather than using equations [8], [9], and [11], a value proportional to the penalty parameter b can simply be subtracted from the selection game move, and can then be equally distributed among the remaining game moves αj. It has been empirically found that this method ensures that no probability value piconverges to “1,” which would adversely result in the selection of a single game move αievery time. In this case, equations [8] and [9] can be modified to read:
pi(k+1)=pi(k)-bpi(k)[8b]pj(k+1)=pj(k)+1n-1bpi(k)[9b]
Assuming game move α3results in an outcome value β=0, equations [8b] and [9b] can be expanded as follows:
p3(k+1)=p3(k)-bp3(k)p1(k+1)=p1(k)+b16p1(k);p2(k+1)=p2(k)+b16p2(k);p4(k+1)=p4(k)+b16p4(k);⋮p17(k+1)=p17(k)+b16p17(k)
In any event, since the game move α3resulted in an unsuccessful outcome, the corresponding probability value p3is decreased, and the game move probability values picorresponding to the remaining game moves αjare increased. The values of a and b are selected based on the desired speed and accuracy that the learning module310learns, which may depend on the size of the game move set α. For example, if the game move set α is relatively small, the game200preferably must learn quickly, thus translating to relatively high a and b values. On the contrary, if the game move set α is relatively large, the game200preferably learns more accurately, thus translating to relatively low a and b values. In other words, the greater the values selected for a and b, the faster the game move probability distribution p changes, whereas the lesser the values selected for a and b, the slower the game move probability distribution p changes. In the preferred embodiment, the values of a and b have been chosen to be 0.1 and 0.5, respectively.
In the preferred embodiment, the reward-penalty update scheme allows the skill level of the game200to track that of the player215during gradual changes in the player's215skill level. Alternatively, a reward-inaction update scheme can be employed to constantly make the game200more difficult, e.g., if the game200has a training mode to train the player215to become progressively more skillful. More alternatively, a penalty-inaction update scheme can be employed, e.g., to quickly reduce the skill level of the game200if a different less skillful player215plays the game200. In any event, the intuition module315may operate on the probability update module320to dynamically select any one of these update schemes depending on the objective to be achieved.
It should be noted that rather than, or in addition to, modifying the functionality of the game move selection module325by subdividing the game move set α into a plurality of game move subsets αsthe respective skill levels of the game200and player215can be continuously and dynamically matched by modifying the functionality of the probability update module320by modifying or selecting the algorithms employed by it. For example, the respective reward and penalty parameters a and b may be dynamically modified.
For example, if the difference between the respective player and game scores260and265(i.e., the score difference value Δ) is substantially positive, the respective reward and penalty parameters a and b can be increased, so that the skill level of the game200more rapidly increases. That is, if the gun125shoots the duck120after it takes a particular game move αi, thus producing an unsuccessful outcome, an increase in the penalty parameter b will correspondingly decrease the chances that the particular game move αiis selected again relative to the chances that it would have been selected again if the penalty parameter b had not been modified. If the gun125fails to shoot the duck120after it takes a particular game move αi, thus producing a successful outcome, an increase in the reward parameter a will correspondingly increase the chances that the particular game move αiis selected again relative to the chances that it would have been selected again if the penalty parameter α had not been modified. Thus, in this scenario, the game200will learn at a quicker rate.
On the contrary, if the score difference value Δ is substantially negative, the respective reward and penalty parameters a and b can be decreased, so that the skill level of the game200less rapidly increases. That is, if the gun125shoots the duck120after it takes a particular game move αi, thus producing an unsuccessful outcome, a decrease in the penalty parameter b will correspondingly increase the chances that the particular game move αiis selected again relative to the chances that it would have been selected again if the penalty parameter b had not been modified. If the gun125fails to shoot the duck120after it takes a particular game move αi, thus producing a successful outcome, a decrease in the reward parameter a will correspondingly decrease the chances that the particular game move αiis selected again relative to the chances that it would have been selected again if the reward parameter a had not been modified. Thus, in this scenario, the game200will learn at a slower rate.
If the score difference value Δ is low, whether positive or negative, the respective reward and penalty parameters a and b can remain unchanged, so that the skill level of the game200will tend to remain the same. Thus, in this scenario, the game200will learn at the same rate.
It should be noted that an increase or decrease in the reward and penalty parameters a and b can be effected in various ways. For example, the values of the reward and penalty parameters a and b can be incrementally increased or decreased a fixed amount, e.g., 0.1. Or the reward and penalty parameters a and b can be expressed in the functional form y=f(x), with the performance index φ being one of the independent variables, and the penalty and reward parameters a and b being at least one of the dependent variables. In this manner, there is a smoother and continuous transition in the reward and penalty parameters a and b.
Optionally, to further ensure that the skill level of the game200rapidly decreases when the score difference value Δ substantially negative, the respective reward and penalty parameters a and b can be made negative. That is, if the gun125shoots the duck120after it takes a particular game move αi, thus producing an unsuccessful outcome, forcing the penalty parameter b to a negative number will increase the chances that the particular game move αiis selected again in the absolute sense. If the gun125fails to shoot the duck120after it takes a particular game move αi, thus producing a successful outcome, forcing the reward parameter a to a negative number will decrease the chances that the particular game move aαiis selected again in the absolute sense. Thus, in this scenario, rather than learn at a slower rate, the game200will actually unlearn. It should be noted in the case where negative probability values piresult, the probability distribution p is preferably normalized to keep the game move probability values piwithin the [0,1] range.
More optionally, to ensure that the skill level of the game200substantially decreases when the score difference value Δ is substantially negative, the respective reward and penalty equations can be switched. That is, the reward equations, in this case equations [6] and [7], can be used when there is an unsuccessful outcome (i.e., the gun125shoots the duck120). The penalty equations, in this case equations [8] and [9] (or [8b] and [9b]), can be used when there is a successful outcome (i.e., when the gun125misses the duck120). Thus, the probability update module320will treat the previously selected αias producing an unsuccessful outcome, when in fact, it has produced a successful outcome, and will treat the previously selected αias producing a successful outcome, when in fact, it has produced an unsuccessful outcome. In this case, when the score difference value Δ is substantially negative, the respective reward and penalty parameters a and b can be increased, so that the skill level of the game200more rapidly decreases.
Alternatively, rather than actually switching the penalty and reward equations, the functionality of the outcome evaluation module330can be modified with similar results. For example, the outcome evaluation module330may be modified to output an outcome value β=0 when the current game move α is successful, i.e., the gun125does not shoot the duck120, and to output an outcome value β=1 when the current game move αiis unsuccessful, i.e., the gun125shoots the duck120. Thus, the probability update module320will interpret the outcome value β as an indication of an unsuccessful outcome, when in fact, it is an indication of a successful outcome, and will interpret the outcome value β as an indication of a successful outcome, when in fact, it is an indication of an unsuccessful outcome. In this manner, the reward and penalty equations are effectively switched.
Rather than modifying or switching the algorithms used by the probability update module320, the game move probability distribution p can be transformed. For example, if the score difference value Δ is substantially positive, it is assumed that the game moves αicorresponding to a set of the highest probability values piare too easy, and the game moves αicorresponding to a set of the lowest probability values piare too hard. In this case, the game moves αicorresponding to the set of highest probability values pican be switched with the game moves corresponding to the set of lowest probability values pi, thereby increasing the chances that that the harder game moves αi(and decreasing the chances that the easier game moves αi) are selected relative to the chances that they would have been selected again if the game move probability distribution p had not been transformed. Thus, in this scenario, the game200will learn at a quicker rate. In contrast, if the score difference value Δ is substantially negative, it is assumed that the game moves αicorresponding to the set of highest probability values piare too hard, and the game moves αicorresponding to the set of lowest probability values piare too easy. In this case, the game moves αicorresponding to the set of highest probability values pican be switched with the game moves corresponding to the set of lowest probability values pi, thereby increasing the chances that that the easier game moves αi(and decreasing the chances that the harder game moves αi) are selected relative to the chances that they would have been selected again if the game move probability distribution p had not been transformed. Thus, in this scenario, the game200will learn at a slower rate. If the score difference value Δ is low, whether positive or negative, it is assumed that the game moves αicorresponding to the set of highest probability values piare not too hard, and the game moves αicorresponding to the set of lowest probability values piare not too easy, in which case, the game moves αicorresponding to the set of highest probability values piand set of lowest probability values piare not switched. Thus, in this scenario, the game200will learn at the same rate.
It should be noted that although the performance index φ has been described as being derived from the score difference value Δ, the performance index φ can also be derived from other sources, such as the game move probability distribution p. If it is known that the outer moves255aor more difficult than the inner moves255b, the performance index φ, and in this case, the skill level of the player215relative to the skill level the game200, may be found in the present state of the game move probability values piassigned to the moves255. For example, if the combined probability values picorresponding to the outer moves255ais above a particular threshold value, e.g., 0.7 (or alternatively, the combined probability values picorresponding to the inner moves255bis below a particular threshold value, e.g., 0.3), this may be an indication that the skill level of the player215is substantially greater than the skill level of the game200. In contrast, if the combined probability values picorresponding to the outer moves255ais below a particular threshold value, e.g., 0.4 (or alternatively, the combined probability values picorresponding to the inner moves255bis above a particular threshold value, e.g., 0.6), this may be an indication that the skill level of the player215is substantially less than the skill level of the game200. Similarly, if the combined probability values picorresponding to the outer moves255ais within a particular threshold range, e.g., 0.4-0.7 (or alternatively, the combined probability values picorresponding to the inner moves255bis within a particular threshold range, e.g., 0.3-0.6), this may be an indication that the skill level of the player215and skill level of the game200are substantially matched. In this case, any of the afore-described probabilistic learning module modification techniques can be used with this performance index φ.
Alternatively, the probabilities values picorresponding to one or more game moves αican be limited to match the respective skill levels of the player215and game200. For example, if a particular probability value piis too high, it is assumed that the corresponding game move αimay be too hard for the player215. In this case, one or more probabilities values pican be limited to a high value, e.g., 0.4, such that when a probability value pireaches this number, the chances that that the corresponding game move αiis selected again will decrease relative to the chances that it would be selected if the corresponding game move probability pihad not been limited. Similarly, one or more probabilities values pican be limited to a low value, e.g., 0.01, such that when a probability value pireaches this number, the chances that that the corresponding game move αiis selected again will increase relative to the chances that it would be selected if the corresponding game move probability pihad not been limited. It should be noted that the limits can be fixed, in which case, only the performance index φ that is a function of the game move probability distribution p is used to match the respective skill levels of the player215and game200, or the limits can vary, in which case, such variance may be based on a performance index φ external to the game move probability distribution p.
Having now described the structure of the game program300, the steps performed by the game program300will be described with reference toFIG. 9. First, the game move probability distribution p is initialized (step405). Specifically, the probability update module320initially assigns an equal probability value to each of the game moves αi, in which case, the initial game move probability distribution p(k) can be represented by
p1(0)=p2(0)=p2(0)=…pn(0)=1n.
Thus, all of the game moves αihave an equal chance of being selected by the game move selection module325. Alternatively, probability update module320initially assigns unequal probability values to at least some of the game moves αi. For example, the outer moves255amay be initially assigned a lower probability value than that of the inner moves255b, so that the selection of any of the outer moves255aas the next game move αiwill be decreased. In this case, the duck220will not be too difficult to shoot when the game200is started. In addition to the game move probability distribution p, the current game move αito be updated is also initialized by the probability update module320at step405.
Then, the game move selection module325determines whether a player move λ2xhas been performed, and specifically whether the gun225has been fired by clicking the mouse button245(step410). If a player move λ2xhas been performed, the outcome evaluation module330determines whether the last game move αiwas successful by performing a collision detection, and then generates the outcome value β in response thereto (step415). The intuition module315then updates the player score260and duck score265based on the outcome value β (step420). The probability update module320then, using any of the updating techniques described herein, updates the game move probability distribution p based on the generated outcome value β (step425).
After step425, or if a player move λ2xhas not been performed at step410, the game move selection module325determines if a player move λ1xhas been performed, i.e., gun225, has breached the gun detection region270(step430). If the gun225has not breached the gun detection region270, the game move selection module325does not select any game move αifrom the game move subset α and the duck220remains in the same location (step435). Alternatively, the game move αimay be randomly selected, allowing the duck220to dynamically wander. The game program300then returns to step410where it is again determined if a player move λ2xhas been performed. If the gun225has breached the gun detection region270at step430, the intuition module315modifies the functionality of the game move selection module325based on the performance index φ, and the game move selection module325selects a game move αifrom the game move set α.
Specifically, the intuition module315determines the relative player skill level by calculating the score difference value Δ between the player score260and duck score265(step440). The intuition module315then determines whether the score difference value Δ is greater than the upper score difference threshold NS2(step445). If Δ is greater than NS2, the intuition module315, using any of the game move subset selection techniques described herein, selects a game move subset αS, a corresponding average probability of which is relatively high (step450). If Δ is not greater than NS2, the intuition module315then determines whether the score difference value Δ is less than the lower score difference threshold NS1(step455). If Δ is less than NS1the intuition module315, using any of the game move subset selection techniques described herein, selects a game move subset αs, a corresponding average probability of which is relatively low (step460). If Δ is not less than NS1, it is assumed that the score difference value Δ is between NS1and NS2, in which case, the intuition module315, using any of the game move subset selection techniques described herein, selects a game move subset αs, a corresponding average probability of which is relatively medial (step465). In any event, the game move selection module325then pseudo-randomly selects a game move αifrom the selected game move subset αs, and accordingly moves the duck220in accordance with the selected game move αi(step470). The game program300then returns to step410, where it is determined again if a player move λ2xhas been performed.
It should be noted that, rather than use the game move subset selection technique, the other afore-described techniques used to dynamically and continuously match the skill level of the player215with the skill level of the game200can be alternatively or optionally be used as well. For example, and referring toFIG. 10, the probability update module320initializes the game move probability distribution p and current game move αisimilarly to that described in step405ofFIG. 9. The initialization of the game move probability distribution p and current game move αiis similar to that performed in step405ofFIG. 9. Then, the game move selection module325determines whether a player move λ2xhas been performed, and specifically whether the gun225has been fired by clicking the mouse button245(step510). If a player move λ2xhas been performed, the intuition module315modifies the functionality of the probability update module320based on the performance index φ.
Specifically, the intuition module315determines the relative player skill level by calculating the score difference value Δ between the player score260and duck score265(step515). The intuition module315then determines whether the score difference value Δ is greater than the upper score difference threshold NS2(step520). If Δ is greater than NS2, the intuition module315modifies the functionality of the probability update module320to increase the game's200rate of learning using any of the techniques described herein (step525). For example, the intuition module315may modify the parameters of the learning algorithms, and specifically, increase the reward and penalty parameters a and b.
If Δ is not greater than NS2, the intuition module315then determines whether the score difference value Δ is less than the lower score difference threshold NS1(step530). If Δ is less than NS1, the intuition module315modifies the functionality of the probability update module320to decrease the game's200rate of learning (or even make the game200unlearn) using any of the techniques described herein (step535). For example, the intuition module315may modify the parameters of the learning algorithms, and specifically, decrease the reward and penalty parameters a and b. Alternatively or optionally, the intuition module315may assign the reward and penalty parameters a and b negative numbers, switch the reward and penalty learning algorithms, or even modify the outcome evaluation module330to output an outcome value β=0 when the selected game move αis actually successful, and output an outcome value β=1 when the selected game move αiis actually unsuccessful.
If Δ is not less than NS2, it is assumed that the score difference value Δ is between NS1and NS2, in which case, the intuition module315does not modify the probability update module320(step540).
In any event, the outcome evaluation module330then determines whether the last game move αiwas successful by performing a collision detection, and then generates the outcome value β in response thereto (step545). Of course, if the intuition module315modifies the functionality of the outcome evaluation module330during any of the steps525and535, step545will preferably be performed during these steps. The intuition module315then updates the player score260and duck score265based on the outcome value β (step550). The probability update module320then, using any of the updating techniques described herein, updates the game move probability distribution p based on the generated outcome value β (step555).
After step555, or if a player move λ2xhas not been performed at step510, the game move selection module325determines if a player move λ1xhas been performed, i.e., gun225, has breached the gun detection region270(step560). If the gun225has not breached the gun detection region270, the game move selection module325does not select a game move αifrom the game move set α and the duck220remains in the same location (step565). Alternatively, the game move αimay be randomly selected, allowing the duck220to dynamically wander. The game program300then returns to step510where it is again determined if a player move λ2xhas been performed. If the gun225has breached the gun detection region270at step560, the game move selection module325pseudo-randomly selects a game move αifrom the game move set α and accordingly moves the duck220in accordance with the selected game move αi(step570). The game program300then returns to step510, where it is determined again if a player move λ2xhas been performed.
More specific details on the above-described operation of the duck game100can be found in the Computer Program Listing Appendix attached hereto and previously incorporated herein by reference. It is noted that each of the files “Intuition Intelligence-duckgame1.doc” and “Intuition Intelligence-duckgame2.doc” represents the game program300, with file “Intuition Intelligence-duckgame1.doc” utilizing the game move subset selection technique to continuously and dynamically match the respective skill levels of the game200and player215, and file “Intuition Intelligence-duckgame2.doc” utilizing the learning algorithm modification technique (specifically, modifying the respective reward and penalty parameters a and b when the score difference value Δ is too positive or too negative, and switching the respective reward and penalty equations when the score difference value Δ is too negative) to similarly continuously and dynamically match the respective skill levels of the game200and player215.
Single-Player Educational Program (Single Game Move-Single Player Move)
The learning program100can be applied to other applications besides game programs. A single-player educational program700(shown inFIG. 12) developed in accordance with the present inventions is described in the context of a child's learning toy600(shown inFIG. 11), and specifically, a doll600and associated articles of clothing and accessories610that are applied to the doll600by a child605(shown inFIG. 12). In the illustrated embodiment, the articles610include a (1) purse, calculator, and hairbrush, one of which can be applied to a hand615of the doll600; (2) shorts and pants, one of which can be applied to a waist620of the doll600; (3) shirt and tank top, one of which can be applied to a chest625of the doll600; and (4) dress and overalls, one of which can be applied to the chest625of the doll600. Notably, the dress and overalls cover the waist620, so that the shorts and pants cannot be applied to the doll600when the dress or overalls are applied. Depending on the measured skill level of the child605, the doll600will instruct the child605to apply either a single article, two articles, or three articles to the doll600. For example, the doll600may say “Simon says, give me my calculator, pants, and tank top.”
In accordance with the instructions given by the doll600, the child605will then attempt to apply the correct articles610to the doll600. For example, the child605may place the calculator in the hand615, the pants on the waist620, and the tank top on the chest625. To determine which articles610the child605has applied, the doll600comprises sensors630located on the hand615, waist620, and chest625. These sensors630sense the unique resistance values exhibited by the articles610, so that the doll600can determine which of the articles610are being applied.
As illustrated in Tables 2-4, there are 43 combinations of articles610that can be applied to the doll600. Specifically, actions α1-α9represent all of the single article combinations, actions α10-α31represent all of the double article combinations, and actions α32-α43represent all of the triple article combinations that can be possibly applied to the doll600.
TABLE 2Exemplary Single Article Combinations for DollAction (α)HandWaistChestα1Pursexxα2Calculatorxxα3Hairbrushxxα4xShortsxα5xPantsxα6xxShirtα7xxTanktopα8xxDressα9xxOveralls
TABLE 3Exemplary Double article combinations for DollAction (α)HandWaistChestα10PurseShortsxα11PursePantsxα12PursexShirtα13PursexTanktopα14PursexDressα15PursexOverallsα16CalculatorShortsxα17CalculatorPantsxα18CalculatorxShirtα19CalculatorxTanktopα20CalculatorxDressα21CalculatorxOverallsα22HairbrushShortsxα23HairbrushPantsxα24HairbrushxShirtα25HairbrushxTanktopα26HairbrushxDressα27HairbrushxOverallsα28xShortsShirtα29xShortsTanktopα30xPantsShirtα31xPantsTanktop
TABLE 4Exemplary Three Article Combinations for DollAction (α)HandWaistChestα32PurseShortsShirtα33PurseShortsTanktopα34PursePantsShirtα35PursePantsTanktopα36CalculatorShortsShirtα37CalculatorShortsTanktopα38CalculatorPantsShirtα39CalculatorPantsTanktopα40HairbrushShortsShirtα41HairbrushShortsTanktopα42HairbrushPantsShirtα43HairbrushPantsTanktop
In response to the selection of one of these actions αi, i.e., prompting the child605to apply one of the 43 article combinations to the doll600, the child605will attempt to apply the correct article combinations to the doll600, represented by corresponding child actions λ1-λ43. It can be appreciated an article combination λxwill be correct if it corresponds to the article combination αiprompted by the doll600(i.e., the child action λ corresponds with the doll action α), and will be incorrect if it corresponds to the article combination αiprompted by the doll600(i.e., the child action A does not correspond with the doll action α).
The doll600seeks to challenge the child605by prompting him or her with more difficult article combinations as the child605applies correct combinations to the doll600. For example, if the child605exhibits a proficiency at single article combinations, the doll600will prompt the child605with less single article combinations and more double and triple article combinations. If the child605exhibits a proficiency at double article combinations, the doll600will prompt the child605with less single and double article combinations and more triple article combinations. If the child605exhibits a proficiency at three article combinations, the doll600will prompt the child605with even more triple article combinations.
The doll600also seeks to avoid over challenging the child605and frustrating the learning process. For example, if the child605does not exhibit a proficiency at triple article combinations, the doll600will prompt the child605with less triple article combinations and more single and double article combinations. If the child605does not exhibit a proficiency at double article combinations, the doll600will prompt the child605with less double and triple article combinations and more single article combinations. If the child605does not exhibit a proficiency at single article combinations, the doll600will prompt the child605with even more single article combinations.
To this end, the educational program700generally includes a probabilistic learning module710and an intuition module715, which are specifically tailored for the doll600. The probabilistic learning module710comprises a probability update module720, an article selection module725, and an outcome evaluation module730. Specifically, the probability update module720is mainly responsible for learning the child's current skill level, with the outcome evaluation module730being responsible for evaluating the article combinations αiprompted by the doll600relative to the article combinations λxselected by the child605. The article selection module725is mainly responsible for using the learned skill level of the child605to select the article combinations αithat are used to prompt the child605. The intuition module715is responsible for directing the learning of the educational program700towards the objective, and specifically, dynamically pushing the skill level of the child605to a higher level. In this case, the intuition module715operates on the probability update module720, and specifically selects the methodology that the probability update module720will use to update an article probability distribution p.
To this end, the outcome evaluation module730is configured to receive an article combination αifrom the article selection module725(i.e., one of the forty-three article combinations that are prompted by the doll600), and receive an article combination λxfrom the child605(i.e., one of the forty-three article combinations that can be applied to the doll600). The outcome evaluation module730is also configured to determine whether each article combination λxreceived from the child605matches the article combination αiprompted by the doll600, with the outcome value β equaling one of two predetermined values, e.g., “0” if there is a match and “1” if there is not a match. In this case, a P-type learning methodology is used. Optionally, the outcome evaluation module730can generate an outcome value β equaling a value between “0” and “1.” For example, if the child605is relatively successful by matching most of the articles within the prompted article combination αi, the outcome value β can be a lower value, and if the child605is relatively unsuccessful by not matching most of the articles within the prompted article combination αi, the outcome value β can be a higher value. In this case, Q-and S-type learning methodologies can be used. In contrast to the duck game200where the outcome value β measured the success or failure of a duck move relative to the game player, the performance of a prompted article combination αiis not characterized as being successful or unsuccessful, since the doll600is not competing with the child605, but rather serves to teach the child605.
The probability update module720is configured to generate and update the article probability distribution p in a manner directed by the intuition module715, with the article probability distribution p containing forty-three probability values picorresponding to the forty-three article combinations αi. In the illustrated embodiment, the forty-three article combinations αiare divided amongst three article combination subsets αs:αs1for the nine single article combinations; αs2for the twenty-two double article combinations; and αs3for the twelve three article combinations. When updating the article probability distribution p, the three article combination subsets αsare updated as three actions, with the effects of each updated article combination subset αsbeing evenly distributed amongst the article combinations αiin the respective subset αs. For example, if the single article combination subset αs1is increased by ten percent, each of the single article combinations α1-α9will be correspondingly increased by ten percent.
The article selection module725is configured for receiving the article probability distribution p from the probability update module720, and pseudo-randomly selecting the article combination αitherefrom in the same manner as the game move selection module325of the program300selects a game move αifrom a selected game move subset αs. Specifically, pseudo-random selection can be accomplished by first generating a progressive sum of the probability values pi. For example, Table 5 sets forth exemplary normalized probability values and a progressive sum for the forty-three article combinations αiof the article probability distribution p:
TABLE 5Progressive Sum of Probability Values For Forty-ThreeExemplary Article CombinationsNormalizedProgressiveGame MoveProbability ValueSumα10.0590.059α20.0590.118α30.0590.187.........α90.0590.531α100.0140.545α110.0140.559α120.0140.573.........α310.0140.839α320.0130.852α330.0130.865.........α430.0131.000
The article selection module725then selects a random number between “0” and “1,” and selects the article combination αicorresponding to the next highest progressive sum value. For example, if the randomly selected number is 0.562, article combination α11(i.e., purse and pants) will be selected.
In an alternative embodiment, the article probability distribution p contains three probability values pirespectively corresponding to three article combination subsets αs, one of which can then be pseudo-randomly selected therefrom. In a sense, the article combination subsets αsare treated as actions to be selected. For example, Table 6 sets forth exemplary normalized probability values and a progressive sum for the three article combination subsets αsof the article probability distribution p:
TABLE 6Progressive Sum of Probability Values For Three ExemplaryArticle Combination SubsetsNormalizedProgressiveGame MoveProbability ValueSumα10.650.65α20.250.90α30.101.00
The article selection module725then selects a random number between “0” and “1,” and selects the article combination subset αscorresponding to the next highest progressive sum value. For example, if the randomly selected number is 0.78, article combination subset αs2will be selected. After the article combination subset αshas been pseudo-randomly selected, the article selection module725then randomly selects an article combination αifrom that selected combination subset αs. For example, if the second article combination subset αswas selected, the article selection module725will randomly select one of the twenty-two double article combinations α10-α31.
The intuition module715is configured to modify the functionality of the probability update module720based on the performance index φ, and in this case, the current skill level of the child605relative to the current teaching level of the doll600. In the preferred embodiment, the performance index φ is quantified in terms of the degree of difficulty of the currently prompted article combination αiand the outcome value β (i.e., whether or not the child605successfully matched the article combination αi). In this respect, the performance index φ is instantaneous. It should be appreciated, however, that the performance of the educational program700can also be based on a cumulative performance index φ. For example, the educational program700can keep track of a percentage of the child's matching article combinations λxbroken down by difficulty level of the prompted article combinations αi.
It can be appreciated, that applying only one article to the doll600is an easier task than applying two articles to the doll600, which is in turn an easier task then applying three articles to the doll600in an given time. The intuition module715will attempt to “push” the child's skill level higher, so that the child605will consistently be able to correctly apply two articles, and then three articles610, to the doll600.
The intuition module715modifies the functionality of the probability update module720by determining which updating methodology will be used. The intuition module715also determines which article combination α will be rewarded or penalized, which is not necessarily the article combination that was previously selected by the article selection module725.
Referring toFIGS. 13a-f, various methodologies can be selected by the intuition module715to update the article probability distribution p, given a currently prompted article combination αiand outcome value β. Although, the probability values piin the article probability distribution p have been described as corresponding to the individual article combinations α, for purposes of simplicity and brevity, the probability values pidepicted inFIGS. 13a-frespectively correspond with the single, double and triple article combination subsets αs. As will be described in further detail below, the intuition module715directs the probability update module720to shift the article probability distribution p from probability value(s) picorresponding to article combinations αiassociated with lesser difficult levels to probability value(s) picorresponding to article combinations αiassociated with greater difficult levels when the child605is relatively successful at matching the prompted article combination αi, and to shift the article probability distribution p from probability value(s) picorresponding to article combinations αiassociated with greater difficult levels to probability value(s) picorresponding to article combinations αiassociated with lesser difficult levels when the child605is relatively unsuccessful at matching the prompted article combination αi. In the illustrated embodiment, P-type learning methodologies (β equals either “0” or “1”) are used, in which case, it is assumed that the child605is absolutely successful or unsuccessful at matching the prompted article combination αi. Alternatively, Q-and S-type learning methodologies (β is between “0” and “1”) are used, in which case, it is assumed that the child605can partially match or not match the prompted article combination αi. For example, the outcome value β may be a lesser value if the child605matches most of the articles in the prompted article combination αi, (relatively successful), and may be a greater value if the child605does not match most of the articles in the prompted article combination αi, (relatively unsuccessful).
FIG. 13aillustrates a methodology used to update the article probability distribution p when a single article combination subset αs1is currently selected, and the child605succeeds in matching the prompted article combination a (i.e., β=0). In this case, the intuition module715will attempt to drive the child's skill level from the single article combination subset αs1to the double article combination subset αs2by increasing the probability that the child605will subsequently be prompted by the more difficult double subset combination sets αs2and triple subset combination sets αs3. The intuition module715accomplishes this be shifting the probability distribution p from the probability value pito the probability values p2and p3. Specifically, the single article combination subset αs1is penalized by subtracting a proportionate value equal to “x” (e.g., ⅕ of pi) from probability value piand distributing it to the probability values p2and p3.
Since the child's success with a single article combination set αs1indicates that the child605may be relatively proficient at double article combinations αs2, but not necessarily the more difficult triple article combinations αs3, the probability value p2is increased more than the probability value p3to ensure that the child's skill level is driven from the single article combination subset αs1to the double article combination subset αs2, and not overdriven to the third article combination subset αs3. For example, the proportions of “x” added to the probability values p2and p3can be ⅔ and ⅓, respectively. In effect, the learning process will be made smoother for the child605. Notably, the methodology illustrated inFIG. 13aallows control over the relative amounts that are added to the probability values p2and p3. That is, the amount added to the probability value p2will always be greater than the amount added to the probability value p3irrespective of the current magnitudes of the probability values p2and p3, thereby ensuring a smooth learning process.
General equations [20] and [21a] can be used to implement the learning methodology illustrated inFIG. 13a. Given that h1(p(k))=(⅕)p1(k), d12=⅔, and d13=⅓, equations [20] and [21a] can be broken down into:
p1(k+1)=p1(k)-h1(p(k))=p1(k)-15p1(k)=45p1(k);[20-1]p2(k+1)=p2(k)+(23)(15)p1(k)=p2(k)+215p1(k);and[21a-1]p3(k+1)=p3(k)+(13)(15)p1(k)=p3(k)+115p1(k)[21a-2]
FIG. 13billustrates a methodology used to update the article probability distribution p when a single article combination subset αs1is currently selected, and the child605does not succeed in matching the prompted article combination α(i.e., β=1). In this case, the intuition module715will attempt to prevent over-challenging the child605by decreasing the probability that the child605will subsequently be prompted by the more difficult double and triple subset combination sets αs2and αs3. The intuition module715accomplishes this be shifting the probability distribution p from the probability values p2and p3to the probability value pi. Specifically, the single article combination subset αs1is rewarded by subtracting a proportional value equal to “x” from probability value p2and adding it to the probability value p1, and subtracting a proportionate value equal to “y” from probability value p3and adding it to the probability value pi.
Since the child's failure with a single article combination set αs1indicates that the child605may not be proficient at double and triple article combinations αs2and αs3, the intuition module715attempts to adapt to the child's apparently low skill level by decreasing the probability values p2and p3as quickly as possible. Because the probability value p2will most likely be much greater than the probability value p3if the child605is not proficient at the single article combination sets αs2, the intuition module715adapts to the child's low skill level by requiring that the proportionate amount that is subtracted from the probability value p2be greater than that subtracted from the probability value p3, i.e., the proportionate value “x” is set higher than the proportional value “y”. For example, “x” can equal 2/15 and “y” can equal 1/15.
Notably, the methodology illustrated inFIG. 13ballows control over the proportionate amounts that are subtracted from the probability values p2and p3and added to the probability value p1, so that the doll600can quickly adapt to a child's lower skill level in a stable manner. That is, if the probability values p2and p3are relatively high, a proportionate amount subtracted from these probability values will quickly decrease them and increase the probability value p1, whereas if the probability values p2and p3are relatively low, a proportionate amount subtracted from these probability values will not completely deplete them.
General equations [6a]-[7a] can be used to implement the learning methodology illustrated inFIG. 13b. Given that g12(p(k))=( 2/15)p2(k) and g13(p(k))=(⅕)p3(k), equations [6a]-[7a] can be broken down into:
p1(k+1)=p1(k)+∑j=23g1j(p(k))=p1(k)+215p2(k)+115p3(k);[6a-1]p2(k+1)=p2(k)-g12(p(k))=p2(k)-215p2(k)=1315p2(k);and[7a-1]p3(k+1)=p3(k)-g13(p(k))=p3(k)-115p3(k)=1415p3(k)[7a-2]
FIG. 13cillustrates a methodology used to update the article probability distribution p when a double article combination subset αs2is currently selected, and the child605succeeds in matching the prompted article combination α(i.e., β=0). In this case, the intuition module715will attempt to drive the child's skill level from the double article combination subset αs2to the triple article combination subset αs3by increasing the probability that the child605will subsequently be prompted by the more difficult triple subset combination sets αs3. The intuition module715accomplishes this be shifting the probability distribution p from the probability value p1to the probability values p2and p3. Specifically, the single article combination subset αs1is penalized by subtracting a proportionate value equal to “x” (e.g., ⅕ of p1) from probability value piand distributing it to the probability values p2and p3.
Since the child's success with a double article combination set αs2indicates that the child605may be relatively proficient at triple article combinations αs2, the probability value p3is increased more than the probability value p2to ensure that the child's skill level is driven from the double article combination subset αs2to the triple article combination subset αs3. For example, the proportions of “x” added to the probability values p2and p3can be ⅓ and ⅔, respectively. Notably, the methodology illustrated inFIG. 13callows control over the relative amounts that are added to the probability values p2and p3. That is, the amount added to the probability value p3will always be greater than the amount added to the probability value p2irrespective of the current magnitudes of the probability values p2and p3, thereby ensuring that the child's skill level is driven towards the triple article combination subset αs3, rather than maintaining the child's skill level at the double article combination subset αs2.
General equations [20] and [21a] can be used to implement the learning methodology illustrated inFIG. 13c. Given that h1(p(k))=(⅕)p1(k), d12=⅓, and d13=⅔, equations [20] and [21a] can be broken down into:
p1(k+1)=p1(k)-h1(p(k))=p1(k)-15p1(k)=45p1(k);[20-2]p2(k+1)=p2(k)+(13)(15)p1(k)=p2(k)+115p1(k);and[21a-3]p3(k+1)=p3(k)+(23)(15)p1(k)=p3(k)+215p1(k)[21a-4]
FIG. 13dillustrates a methodology used to update the article probability distribution p when a double article combination subset αs2is currently selected, and the child605does not succeed in matching the prompted article combination α(i.e., β=1). In this case, the intuition module715will attempt to prevent over-challenging the child605by decreasing the probability that the child605will subsequently be prompted by the more difficult double and triple subset combination sets αs2and αs3. The intuition module715accomplishes this by shifting the probability distribution p from the probability values p2and p3to the probability value p1. Specifically, the single article combination subset αs1is rewarded by subtracting a proportional value equal to “x” from probability value p2and adding it to the probability value pi, and subtracting a proportionate value equal to “y” from probability value p3and adding it to the probability value p1.
Since the child's failure with a double article combination set αs2indicates that the child605may not be proficient at triple article combinations αs2, the probability value p3is decreased more than the probability value p2. The intuition module715accomplishes this by requiring that the proportionate amount that is subtracted from the probability value p3be greater than that subtracted from the probability value p2, i.e., the proportionate value “y” is set higher than the proportional value “x”. For example, “x” can equal 1/15 and “y” can equal 2/15.
Notably, the methodology illustrated inFIG. 13dallows control over the proportionate amounts that are subtracted from the probability values p2and p3and added to the probability value p1, so that the doll600can quickly adapt to a child's lower skill level in a stable manner. That is, if the probability values p2and p3are relatively high, a proportionate amount subtracted from these probability values will quickly decrease them and increase the probability value pi, whereas if the probability values p2and p3are relatively low, a proportionate amount subtracted from these probability values will not completely deplete them.
General equations [6a]-[7a] can be used to implement the learning methodology illustrated inFIG. 13d. Given that g12(p(k))=( 1/15)p2(k) and g13(p(k))=( 2/15)p3(k), equations [6a]-[7a] can be broken down into:
p1(k+1)=p1(k)+∑j=23g1j(p(k))=p1(k)+115p2(k)+215p3(k);[6a-2]p2(k+1)=p2(k)-g12(p(k))=p2(k)-115p2(k)=1415p2(k);and[7a-3]p3(k+1)=p3(k)-g13(p(k))=p3(k)-215p3(k)=1315p3(k)[7a-4]
FIG. 13eillustrates a methodology used to update the article probability distribution p when a triple article combination subset αs3is currently selected, and the child605succeeds in matching the prompted article combination α(i.e., β=0). In this case, the intuition module715will attempt to drive the child's skill level further to the triple article combination subset αs3by increasing the probability that the child605will subsequently be prompted by the more difficult triple subset combination sets αs3. The intuition module715accomplishes this be shifting the probability distribution p from the probability values p1and p2to the probability value p3. Specifically, the triple article combination subset αs1is rewarded by subtracting a proportional value equal to “x” from probability value p1and adding it to the probability value p3, and subtracting a proportionate value equal to “y” from probability value p2and adding it to the probability value p3.
Since the child605is much more proficient at single article combinations αs1than with double article combinations αs2, the intuition module715attempts to reduce the probability value p1more than the probability value p2. The intuition module715accomplishes this by requiring that the proportionate amount that is subtracted from the probability value pibe greater than that subtracted from the probability value p2, i.e., the proportionate value “x” is set higher than the proportional value “y”. For example, “x” can equal 2/15 and “y” can equal 1/15.
Notably, the methodology illustrated inFIG. 13eallows control over the proportionate amounts that are subtracted from the probability values p2and p3and added to the probability value p1, so that the doll600can quickly adapt to a child's higher skill level in a stable manner. That is, if the probability values p1and p2are relatively high, a proportionate amount subtracted from these probability values will quickly decrease them and increase the probability value p3, whereas if the probability values p1and p2are relatively low, a proportionate amount subtracted from these probability values will not completely deplete them.
General equations [6a]-[7a] can be used to implement the learning methodology illustrated inFIG. 13e. Given that g31(p(k))=( 2/15)p1(k) and g32(p(k))=( 1/15)p2(k), equations [6a]-[7a] can be broken down into:
p3(k+1)=p3(k)+∑j=12g3j(p(k))=p3(k)+215p1(k)+115p2(k);[6a-3]p1(k+1)=p1(k)-g31(p(k))=p1(k)-215p1(k)=1315p1(k);and[7a-5]p2(k+1)=p2(k)-g32(p(k))=p2(k)-115p2(k)=1415p2(k)[7a-6]
FIG. 13fillustrates a methodology used to update the article probability distribution p when a triple article combination subset αs3is currently selected, and the child605does not succeed in matching the prompted article combination α(i.e., β=1). In this case, the intuition module715will attempt to prevent over-challenging the child605by decreasing the probability that the child605will subsequently be prompted by the more difficult triple subset combination set αs3. The intuition module715accomplishes this be shifting the probability distribution p from the probability value p3to the probability values p1and p2. Specifically, the triple article combination subset αs3is penalized by subtracting a proportionate value equal to “x” (e.g., ⅕ of p3) from probability value p3and distributing it to the probability values p1and p2.
Since the child's failure with a triple article combination set αs1indicates that the child605may not be relatively proficient at double article combinations αs2, but not necessarily not proficient with the easier single article combinations αs1, the probability value p2is increased more than the probability value p1to ensure that the child605is not under-challenged with single article combination subsets αs1. For example, the proportions of “x” added to the probability values p1and p2can be ⅓ and ⅔, respectively. Notably, the methodology illustrated inFIG. 13fallows control over the relative amounts that are added to the probability values p1and p2. That is, the amount added to the probability value p2will always be greater than the amount added to the probability value p1irrespective of the current magnitudes of the probability values p1and p2, thereby ensuring that the child605is not under-challenged with single article combination subsets αs1.
General equations [20] and [21a] can be used to implement the learning methodology illustrated inFIG. 13f. Given that h3(p(k))=(⅕)p3(k), d31=⅓, and d32=⅔, equations [20] and [21a] can be broken down into:
p3(k+1)=p3(k)-h3(p(k))=p3(k)-15p3(k)=45p3(k);[20-3]p1(k+1)=p1(k)+(13)(15)p3(k)=p1(k)+115p3(k);and[21a-5]p2(k+1)=p2(k)+(23)(15)p3(k)=p2(k)+215p3(k)[21a-6]
Although the intuition module715has been previously described as selecting the learning methodologies based merely on the difficulty of the currently prompted article combination αiand the outcome value β, the intuition module715may base its decision on other factors, such as the current probability values pi. For example, assuming a single article combination subset αs1is currently selected, and the child605succeeds in matching the prompted article combination α(i.e., β=0), if probability value p3is higher than probability value p2, a modified version of the learning methodology illustrated inFIG. 13acan be selected, wherein the all of the amount subtracted from probability value p1can be added to probability value p2to make the learning transition smoother.
Having now described the structure of the educational program700, the steps performed by the educational program700will be described with reference toFIG. 14. First, the probability update module720initializes the article probability distribution p (step805). For example, the educational program700may assume that the child605initially exhibits a relatively low skill level with the doll600, in which case, the initial combined probability values picorresponding to the single article combination subset αs1can equal 0.80, and the initial combined probability values picorresponding to the double article combination subset αs2can equal 0.20. Thus, the probability distribution p is weighted towards the single article combination subset αs1, so that, initially, there is a higher probability that the child605will be prompted with the easier single article combinations αi.
The article selection module725then pseudo-randomly selects an article combination αifrom the article probability distribution p, and accordingly prompts the child605with that selected article combination αi(step810). In the alternative case where the article probability distribution p only contains three probability values pifor the respective three article combination subsets αs, the article section module725pseudo-randomly selects an article combination subset αs, and then from the selected article combination subset αs, randomly selects an article combination αi.
After the article combination αihas been selected, the outcome evaluation module730then determines whether the article combination λxhas been selected by the child605, i.e., whether the child has applied the articles610to the doll600(step815). To allow the child605time to apply the articles610to the doll600or to change misapplied articles610, this determination can be made after a certain period of time has expired (e.g., 10 seconds). If an article combination λxhas not been selected by the child605at step815, the educational program700then returns to step815where it is again determined if an article combination λxhas been selected. If an article combination λxhas been selected by the child605, the outcome evaluation module730then determines if it matches the article combination αiprompted by the doll600, and generates the outcome value β in response thereto (step820).
The intuition module715then modifies the functionality of the probability update module720by selecting the learning methodology that is used to update the article probability distribution p based on the outcome value β and the number of articles contained within the prompted article combination αi(step825). Specifically, the intuition module715selects (1) equations [20-1], [21a-1], and [21a-2] if the article combination λxselected by the child605matches a prompted single article combination αi; (2) equations [6a-1], [7a-1], and [7a-2] if the article combination λxselected by the child605does not match a prompted single article combination αi; (3) equations [20-2], [21a-3], and [21a-4] if the article combination λxselected by the child605matches a prompted double article combination αi; (4) equations [6a-2], [7a-3], and [7a-4] if the article combination λxselected by the child605does not match a prompted double article combination αi; (5) equations [6a-3], [7a-5], and [7a-6] if the article combination λxselected by the child605matches a prompted triple article combination αi; and (6) equations [20-3], [21a-5], and [21a-6] if the article combination λxselected by the child605does not match a prompted triple article combination αi.
The probability update module720then, using equations selected by the intuition module715, updates the article probability distribution p (step830). Specifically, when updating the article probability distribution p, the probability update module720initially treats the article probability distribution p as having three probability values picorresponding to the three article combination subsets αs. After the initial update, the probability update module720then evenly distributes the three updated probability values piamong the probability values picorresponding to the article combinations α. That is, the probability value picorresponding to the single article combination subset αs1is distributed among the probability values picorresponding to the nine single article combinations αi; the probability value picorresponding to the double article combination subset α2is distributed among the probability values picorresponding to the twenty-two double article combinations αi; and the probability value picorresponding to the triple article combination subset αs3is distributed among the probability values picorresponding to the twelve triple article combinations αi. In the alternative embodiment where the article probability distribution p actually contains three article probability values picorresponding to the three article combination subsets αs, the probability update module720simply updates the three article probability values pi, which are subsequently selected by the article selection module725. The program700then returns to step810.
Although the actions on which the program700operates has previously been described as related to prompted tasks, e.g., article combinations, the actions can also relate to educational games that can be played by the child605. Another single-player educational program900(shown inFIG. 15) developed in accordance with the present inventions is described in the context of a modification of the previously described child's learning toy600(shown inFIG. 11).
The modified doll600can contain three educational games (represented by games α1-α3) that can be presented to the child605. These educational games will have different degrees of difficulty. For example, the first game α1can be a relatively easy article matching game that prompts the child605to apply the articles one at a time to the doll600. The second game α2can be a more difficult color matching memory game that prompts the child605with a series of colors that the child605could input using a color keypad (not shown). The third game α3can be an even more difficult cognition game that prompts the child605with a number that the child605responds with color coded numbers the sum of which should add up to the prompted number.
In this case, the doll600seeks to challenge the child605by presenting him or her with more difficult games as the child605masters the doll600. For example, if the child605exhibits a proficiency at the article matching game α1, the doll600will less frequently present the child605with the article matching game α1, and more frequently present the child605with color matching memory game α2and cognition game α3. If the child605exhibits a proficiency at the color matching memory game α2, the doll600will less frequently present the child605with the article matching game α1and color matching memory game α2, and more frequently present the child605with the cognition game α3. If the child605exhibits a proficiency at the cognition game α3, the doll600will even more frequently present the cognition game α3to the child605.
The doll600also seeks to avoid over challenging the child605and frustrating the learning process. For example, if the child605does not exhibit a proficiency at the cognition game α3, the doll600will less frequently present the child605with the cognition game α3and more frequently present the child605with the article matching game α1and color matching memory game α2. If the child605does not exhibit a proficiency at the color matching memory game α2, the doll600will less frequently present the child605with the color matching memory game α2and cognition game α3, and more frequently present the child605with the article matching game α1. If the child605does not exhibit a proficiency at the article matching game α1, the doll600will even more frequently present the article matching game α1to the child605.
The educational program900is similar to the previously described educational program700with the exception that it treats the actions αias educational games, rather than article combinations, and treats the child actions λxas actions to be input by the child605as specified by the currently played educational game, i.e., inputting articles in the case of the article matching game α1, inputting colors in the case of the color matching memory game α2, and inputting number coded colors in the case of the cognition game α3.
To this end, the educational program900generally includes a probabilistic learning module910and an intuition module915, which are specifically tailored for the modified doll600. The probabilistic learning module910comprises a probability update module920, a game selection module925, and an outcome evaluation module930. Specifically, the probability update module920is mainly responsible for learning the child's current skill level, with the outcome evaluation module930being responsible for evaluating the educational games αipresented by the doll600relative to the actions λxselected by the child605. The game selection module925is mainly responsible for using the learned skill level of the child605to select the games αithat presented to the child605. The intuition module915is responsible for directing the learning of the educational program900towards the objective, and specifically, dynamically pushing the skill level of the child605to a higher level. In this case, the intuition module915operates on the probability update module920, and specifically selects the methodology that the probability update module920will use to update a game probability distribution p.
To this end, the outcome evaluation module930is configured to receive an educational game αifrom the game selection module925(i.e., one of the three educational games to be presented to the child605by the doll600), and receive actions λxfrom the child605(i.e., actions that the child605inputs into doll600during the current educational game αi). The outcome evaluation module930is also configured to determine whether the actions λxreceived from the child605are successful within the selected educational game αi, with the outcome value β equaling one of two predetermined values, e.g., “0” if the child actions λxare successful within the selected educational game αi, and “1” if the child actions λxis not successful within the selected educational game αi. In this case, a P-type learning methodology is used. Optionally, Q-and S-type learning methodologies can be used to quantify child actions λxthat are relatively successful or unsuccessful.
The probability update module920is configured to generate and update the game probability distribution p in a manner directed by the intuition module915, with the article probability distribution p containing three probability values picorresponding to the three educational games αi. The game selection module925is configured for receiving the article probability distribution p from the probability update module920, and pseudo-randomly selecting the education game αitherefrom in the same manner as the article selection module725of the program700selects article combination subsets αs.
The intuition module915is configured to modify the functionality of the probability update module920based on the performance index φ, and in this case, the current skill level of the child605relative to the current teaching level of the doll600. In the preferred embodiment, the performance index φ is quantified in terms of the degree of difficulty of the currently selected educational game αiand the outcome value β (i.e., whether or not the actions λxselected by the child605are successful). In this respect, the performance index φ is instantaneous. It should be appreciated, however, that the performance of the educational program900can also be based on a cumulative performance index φ. For example, the educational program900can keep track of a percentage of the child's successful with the educational games αi.
The intuition module915modifies the functionality of the probability update module920is the same manner as the previously described intuition module715modifies the functionality of the probability update module720. That is, the intuition module915determines which updating methodology will be used and which educational game α will be rewarded or penalized in a manner similar to that described with respect toFIGS. 13a-f. For example, the intuition module915directs the probability update module920to shift the game probability distribution p from probability value(s) picorresponding to educational games αiassociated with lesser difficult levels to probability value(s) picorresponding to educational games αiassociated with greater difficult levels when the child605is relatively successful at the currently selected education game αi, and to shift the game probability distribution p from probability value(s) picorresponding to educational games αiassociated with greater difficult levels to probability value(s) picorresponding to educational games αiassociated with lesser difficult levels when the child605is relatively unsuccessful at the currently selected education game αi.
In the illustrated embodiment, P-type learning methodologies (β equals either “0” or “1”) are used, in which case, it is assumed that the child605is absolutely successful or unsuccessful in any given educational game αi. Alternatively, Q-and S-type learning methodologies (β is between “0” and “1”) are used, in which case, it is assumed that the child605can be partially successful or unsuccessful in any given educational game αi. For example, the outcome value β may be a lesser value if most of the child actions λxare successful, and may be a greater value if most of the child actions λxare unsuccessful.
The intuition module915can select from the learning methodologies illustrated inFIGS. 13a-f. For example, the intuition module915can select (1) the methodology illustrated inFIG. 13aif the child605succeeds in the article matching game α1; (2) the methodology illustrated inFIG. 13bif the child605does not succeed in the article matching game α1; (3) the methodology illustrated inFIG. 13cif the child605succeeds in the color matching memory game α2; (4) the methodology illustrated inFIG. 13dif the child605does not succeed in the color matching memory game α2; (5) the methodology illustrated inFIG. 13eif the child605succeeds in the cognition game α3; and (6) the methodology illustrated inFIG. 13fif the child605does not succeed in the cognition game α3.
So that selection of the educational games αiis not too erratic, the intuition module915may optionally modify the game selection module925, so that it does not select the relatively easy article matching game α1after the relatively difficult cognition game α3has been selected, and does not select the relatively difficult cognition game α3after the relatively easy article matching game α1has been selected. Thus, the teaching level of the doll600will tend to play the article matching game α1, then the color matching memory game α2, and then the cognition game α3, as the child605learns.
Having now described the structure of the educational program900, the steps performed by the educational program900will be described with reference toFIG. 16. First, the probability update module920initializes the game probability distribution p (step1005). For example, the educational program900may assume that the child605initially exhibits a relatively low skill level with the doll600, in which case, the initial probability values picorresponding to the relatively easy article matching game α1can equal 0.80, and the initial probability value picorresponding to the color matching memory game α2can equal 0.20. Thus, the probability distribution p is weighted towards the article matching game α1, so that, initially, there is a higher probability that the child605will be prompted with the easier article matching game α1.
The game selection module925then pseudo-randomly selects an educational game αifrom the game probability distribution p, and accordingly presents the child605with that selected game αi(step1010).
After the educational game αihas been selected, the outcome evaluation module930then receives actions λxfrom the child605(step1015) and determines whether the game αihas been completed (step1020). If the selected educational game αihas not been completed at step1015, the educational program900then returns to step1015where it receives actions λxfrom the child605. If the selected educational game αihas been completed at step1015, the outcome evaluation module930then determines whether the actions λxfrom the child605are successful, and generates the outcome value β in response thereto (step1025).
The intuition module915then modifies the functionality of the probability update module920by selecting the learning methodology that is used to update the article probability distribution p based on the outcome value β and the currently played educational game αi(step1030). Specifically, the intuition module915selects (1) equations [20-1], [21a-1], and [21a-2] if the actions λxselected by the child605within the article matching game αiare relatively successful; (2) equations [6a-1], [7a-1], and [7a-2] if the actions λxselected by the child605within the article matching game αiare relatively unsuccessful; (3) equations [20-2], [21 a-3], and [21a-4] if the actions λxselected by the child605within the color matching memory game α2are relatively successful; (4) equations [6a-2], [7a-3], and [7a-4] if the actions λxselected by the child605within the color matching memory game α2are relatively unsuccessful; (5) equations [6a-3], [7a-5], and [7a-6] if the actions λxselected by the child605within the cognition game α3are relatively successful; and (6) equations [20-3], [21a-5], and [21a-6] if the actions λxselected by the child605within the cognition game α3are relatively unsuccessful.
The probability update module920then, using equations selected by the intuition module915, updates the article probability distribution p (step1035). The program900then returns to step1010where the game selection module925again pseudo-randomly selects an educational game αifrom the game probability distribution p, and accordingly presents the child605with that selected game αi.
More Specific details on the above-described operation of the toy600can be found in the computer program listing appendix attached hereto and previously incorporated herein by reference. It is noted that the file “Intuition Intelligence-simonsays.doc” shows that the game can be played in two modes.
Specifically, in the hardware mode (communication through USB), the toy is connected to a digital logic board on a USB Controller board. A USB cable connects the USB port on the PC and the USB Controller board. A simple USB software driver on the PC aids in reading the “code” that is generated by the digital logic. The digital logic is connected to the various switches and the sensor points of the toy. The sensors are open circuits that are closed when an accessory is placed (or connected to a sensor) on the toy. Each article or accessory of the toy has different resistor values. The digital logic determines which sensors circuits are closed and open, which switches are ON and OFF, and the resistor value of the article connected to the sensor. Based on these inputs digital logic generates different codes. Digital logic generated code is processed by the program in the PC.
In the software mode, the hardware communication is simulated by typing in the code directly to a text box. The software version emulation eliminates the need for USB communication and the digital logic circuit code generation. The code that is needed for the game play is pre-initialized in variables for different prompts. The code that is expected by the toy is also shown on the screen, so that the toy can be tested. If the code expected and the code typed in the text box (or the hardware generated code) are the same, it is consider a success for the child.
Single-User Phone Number Listing Program
Although game and toy applications have only been described in detail so far, the learning program100can have even more applications. For example, referring toFIGS. 17 and 18, a priority listing program1200(shown inFIG. 19) developed in accordance with the present inventions is described in the context of a mobile phone1100. The mobile phone1100comprises a display1110for displaying various items to a phone user1115(shown inFIG. 19). The mobile phone1100further comprises a keypad1140through which the phone user1115can dial phone numbers and program the functions of the mobile phone1100. To the end, the keypad1140includes number keys1145, a scroll key1146, and selection keys1147. The mobile phone1100further includes a speaker1150, microphone1155, and antenna1160through which the phone user1115can wirelessly carry on a conversation. The mobile phone1100further includes keypad circuitry1170, control circuitry1135, memory1130, and a transceiver1165.
The keypad circuitry1170decodes the signals from the keypad1140, as entered by the phone user1115, and supplies them to the control circuitry1135. The control circuitry1135controls the transmission and reception of call and voice signals. During a transmission mode, the control circuitry1135provides a voice signal from the microphone1155to the transceiver1165. The transceiver1165transmits the voice signal to a remote station (not shown) for communication through the antenna1160. During a receiving mode, the transceiver1165receives a voice signal from the remote station through the antenna1160. The control circuitry1135then provides the received voice signal from the transceiver1165to the speaker1150, which provides audible signals for the phone user1115. The memory1130stores programs that are executed by the control circuitry1135for basic functioning of the mobile phone1100. In many respects, these elements are standard in the industry, and therefore their general structure and operation will not be discussed in detail for purposes of brevity.
In addition to the standard features that typical mobile phones have, however, the mobile phone1100displays a favorite phone number list1120from which the phone user1115can select a phone number using the scroll and select buttons1146and1147on the keypad1140. In the illustrated embodiment, the favorite phone number list1120has six phone numbers1820at any given time, which can be displayed to the phone user1115in respective sets of two and four numbers. It should be noted, however, that the total number of phone numbers within the list1120may vary and can be displayed to the phone user1115in any variety of manners.
The priority listing program1200, which is stored in the memory1130and executed by the control circuitry1135, dynamically updates the telephone number list1120based on the phone user's1115current calling habits. For example, the program1200maintains the favorite phone number list1120based on the number of times a phone number has been called, the recent activity of the called phone number, and the time period (e.g., day, evening, weekend, weekday) in which the phone number has been called, such that the favorite telephone number list1120will likely contain a phone number that the phone user1115is anticipated to call at any given time. As will be described in further detail below, the listing program1200uses the existence or non-existence of a currently called phone number on a comprehensive phone number list as a performance index φ in measuring its performance in relation to its objective of ensuring that the favorite phone number list1120will include future called phone numbers, so that the phone user1115is not required to dial the phone number using the number keys1145. In this regard, it can be said that the performance index φ is instantaneous. Alternatively or optionally, the listing program1200can also use the location of the phone number on the comprehensive phone number list as a performance index φ.
Referring now toFIG. 19, the listing program1200generally includes a probabilistic learning module1210and an intuition module1215, which are specifically tailored for the mobile phone1100. The probabilistic learning module1210comprises a probability update module1220, a phone number selection module1225, and an outcome evaluation module1230. Specifically, the probability update module1220is mainly responsible for learning the phone user's1115calling habits and updating a comprehensive phone number list α that places phone numbers in the order that they are likely to be called in the future during any given time period. The outcome evaluation module1230is responsible for evaluating the comprehensive phone number list α relative to current phone numbers λxcalled by the phone user1115. The phone number selection module1225is mainly responsible for selecting a phone number subset αsfrom the comprehensive phone number list α for eventual display to the phone user1115as the favorite phone number list1120. The intuition module1215is responsible for directing the learning of the listing program1200towards the objective, and specifically, displaying the favorite phone number list1120that is likely to include the phone user's1115next called phone number. In this case, the intuition module1215operates on the probability update module1220, the details of which will be described in further detail below.
To this end, the phone number selection module1225is configured to receive a phone number probability distribution p from the probability update module1220, which is similar to equation [1] and can be represented by the following equation:
p(k)=[p1(k),p2(k),p3(k) . . .pn(k)], [1-2]where piis the probability value assigned to a specific phone number αi; n is the number of phone numbers αiwithin the comprehensive phone number list α, and k is the incremental time at which the phone number probability distribution p was updated.
Based on the phone number probability distribution p, the phone number selection module1225generates the comprehensive phone number list α, which contains the listed phone numbers αiordered in accordance with their associated probability values pi. For example, the first listed phone number αiwill be associated with the highest probability value pi, while the last listed phone number αiwill be associated with the lowest probability value pi. Thus, the comprehensive phone number list α contains all phone numbers ever called by the phone user1115and is unlimited. Optionally, the comprehensive phone number list α can contain a limited amount of phone numbers, e.g., 100, so that the memory1130is not overwhelmed by seldom called phone numbers. In this case, seldom called phone numbers αimay eventually drop off of the comprehensive phone number list α.
It should be noted that a comprehensive phone number list α need not be separate from the phone number probability distribution p, but rather the phone number probability distribution p can be used as the comprehensive phone number list α to the extent that it contains a comprehensive list of phone numbers αicorresponding to all of the called phone numbers λx. However, it is conceptually easier to explain the aspects of the listing program1200in the context of a comprehensive phone number list that is ordered in accordance with the corresponding probability values pi, rather than in accordance with the order in which they are listed in the phone number probability distribution p.
From the comprehensive phone number list α, the phone number selection module1225selects the phone number subset αs(in the illustrated embodiment, six phone numbers αi) that will be displayed to the phone user1115as the favorite phone number list1120. In the preferred embodiment, the selected phone number subset αswill contain those phone numbers αithat correspond to the highest probability values pi, i.e., the top six phone numbers αion the comprehensive phone number list α.
As an example, consider Table 7, which sets forth in exemplary comprehensive phone number list α with associated probability values pi.
TABLE 7Exemplary Probability Values for Comprehensive Phone Number ListNumberListed Phone Numbers (αi)Probability Values (pi)1949-339-29320.2532343-39850.1833239-32080.1284239-29080.1025343-10980.1096349-00850.0737239-38330.0538239-40430.038.........96213-483-33430.00997383-303-38380.00798808-483-39840.00799398-38380.005100239-34090.002
In this exemplary case, phone numbers 949-339-2932, 343-3985, 239-3208, 239-2908, 343-1098, and 349-0085 will be selected as the favorite phone number list1220, since they are associated with the top six probability values pi.
The outcome evaluation module1230is configured to receive a called phone number λxfrom the phone user1115via the keypad1140and the comprehensive phone number list α from the phone number selection module1225. For example, the phone user1115can dial the phone number λxusing the number keys1145of the keypad1140, selecting the phone number λxfrom the favorite phone number list1120by operating the scroll and selection keys1146and1147of the keypad1140, or through any other means. In this embodiment, the phone number λxcan be selected from a virtually infinite set of phone numbers λ, i.e., all valid phone numbers that can be called by the mobile phone1100. The outcome evaluation module1230is further configured to determine and output an outcome value β that indicates if the currently called phone number λxis on the comprehensive phone number list α. In the illustrated embodiment, the outcome value β equals one of two predetermined values: “1” if the currently called phone number λxmatches a phone number αion the comprehensive phone number list α, and “0” if the currently called phone number λxdoes not match a phone number αion the comprehensive phone number list α.
It can be appreciated that unlike in the duck game300where the outcome value β is partially based on the selected game move αi, the outcome value β is technically not based on listed phone numbers αiselected by the phone number selection module1225, i.e., the phone number subset αs, but rather whether a called phone number λxis on the comprehensive phone number list α irrespective of whether it is in the phone number subset αs. It should be noted, however, that the outcome value β can optionally or alternatively be partially based on the selected phone number subset αs, as will be described in further detail below.
The intuition module1215is configured to receive the outcome value β from the outcome evaluation module1230and modify the probability update module1220, and specifically, the phone number probability distribution p, based thereon. Specifically, if the outcome value β equals “0,” indicating that the currently called phone number λxwas not found on the comprehensive phone number list α, the intuition module1215adds the called phone number λxto the comprehensive phone number list α as a listed phone number αi.
The phone number αican be added to the comprehensive phone number list α in a variety of ways. In general, the location of the added phone number αiwithin the comprehensive phone number list α depends on the probability value piassigned or some function of the probability value piassigned.
For example, in the case where the number of phone numbers αiis not limited or has not reached its limit, the phone number αimay be added by assigning a probability value pito it and renormalizing the phone number probability distribution p in accordance with the following equations:
pi(k+1)=f(x); [22]
pj(k+1)=pj(k)(1−f(x));j≠i[23]where i is the added index corresponding to the newly added phone number αi, piis the probability value corresponding to phone number αiadded to the comprehensive phone number list α,f(x) is the probability value piassigned to the newly added phone number αi, pjis each probability value corresponding to the remaining phone numbers αjon the comprehensive phone number list α, and k is the incremental time at which the phone number probability distribution was updated.
In the illustrated embodiment, the probability value piassigned to the added phone number αiis simply the inverse of the number of phone numbers αion the comprehensive phone number list α, and thus f(x) equals 1/(n+1), where n is the number of phone numbers on the comprehensive phone number list α prior to adding the phone number αi. Thus, equations [22] and [23] break down to:
pi(k+1)=1n+1;[22-1]pj(k+1)=pj(k)nn+1;j≠i[23-1]
In the case where the number of phone numbers αiis limited and has reached its limit, the phone number α with the lowest corresponding priority value piis replaced with the newly called phone number λxby assigning a probability value pito it and renormalizing the phone number probability distribution p in accordance with the following equations:
pi(k+1)=f(x);[24]pj(k+1)=pj(k)∑j≠inpj(k)(1-f(x));j≠i[25]where i is the index used by the removed phone number αi, piis the probability value corresponding to phone number αiadded to the comprehensive phone number list α, f(x) is the probability value pmassigned to the newly added phone number αi, pjis each probability value corresponding to the remaining phone numbers ajon the comprehensive phone number list α, and k is the incremental time at which the phone number probability distribution was updated.
As previously stated, in the illustrated embodiment, the probability value piassigned to the added phone number αiis simply the inverse of the number of phone numbers αion the comprehensive phone number list α, and thus f(x) equals 1/n, where n is the number of phone numbers on the comprehensive phone number list α. Thus, equations [24] and [25] break down to:
pi(k+1)=1n;[24-1]pj(k+1)=pj(k)∑j≠1npj(k)(n-1n);j≠i[25-1]
It should be appreciated that the speed in which the automaton learns can be controlled by adding the phone number αito specific locations within the phone number probability distribution p. For example, the probability value piassigned to the added phone number αican be calculated as the mean of the current probability values pi, such that the phone number αiwill be added to the middle of the comprehensive phone number list α to effect an average learning speed. The probability value piassigned to the added phone number αican be calculated as an upper percentile (e.g. 25%) to effect a relatively quick learning speed. Or the probability value piassigned to the added phone number αican be calculated as a lower percentile (e.g. 75%) to effect a relatively slow learning speed. It should be noted that if there is a limited number of phone numbers αion the comprehensive phone number list α, thereby placing the lowest phone numbers αiin the likelihood position of being deleted from the comprehensive phone number list α, the assigned probability value pishould be not be so low as to cause the added phone number αito oscillate on and off of the comprehensive phone number list α when it is alternately called and not called.
In any event, if the outcome value β received from the outcome evaluation module1230equals “1,” indicating that the currently called phone number λxwas found on the comprehensive phone number list α, the intuition module1215directs the probability update module1220to update the phone number probability distribution p using a learning methodology. In the illustrated embodiment, the probability update module1220utilizes a linear reward-inaction P-type update.
As an example, assume that a currently called phone number λxmatches a phone number α10on the comprehensive phone number list α, thus creating an outcome value β=1. Assume also that the comprehensive phone number list α currently contains 50 phone numbers αi. In this case, general updating equations [6] and [7] can be expanded using equations [10] and [11], as follows:
p10(k+1)=p10(k)+∑j=1j≠1050apj(k);p1(k+1)=p1(k)-ap1(k);p2(k+1)=p2(k)-ap2(k);p4(k+1)=p4(k)-ap4(k);⋮p50(k+1)=p50(k)-ap50(k)
Thus, the corresponding probability value p10is increased, and the phone number probability values picorresponding to the remaining phone numbers αiare decreased. The value of a is selected based on the desired learning speed. The lower the value of a, the slower the learning speed, and the higher the value of a, the higher the learning speed. In the preferred embodiment, the value of a has been chosen to be 0.02. It should be noted that the penalty updating equations [8] and [9] will not be used, since in this case, a reward-penalty P-type update is not used.
Thus, it can be appreciated that, in general, the more a specific listed phone number αiis called relative to other listed phone numbers αi, the more the corresponding probability value piis increased, and thus the higher that listed phone number αiis moved up on the comprehensive phone number list α. As such, the chances that the listed phone number αiwill be contained in the selected phone number subset αsand displayed to the phone user1115as the favorite phone number list1120will be increased. In contrast, the less a specific listed phone number αiis called relative to other listed phone numbers αi, the more the corresponding probability value piis decreased (by virtue of the increased probability values picorresponding to the more frequently called listed phone numbers αi), and thus the lower that listed phone number αiis moved down on the comprehensive phone number list α. As such, the chances that the listed phone number αiwill be contained in the phone number subset αsselected by the phone number selection module1225and displayed to the phone user1115as the favorite phone number list1120will be decreased.
It can also be appreciated that due to the nature of the learning automaton, the relative movement of a particular listed phone number αiis not a matter of how many times the phone number αiis called, and thus, the fact that the total number of times that a particular listed phone number αihas been called is high does not ensure that it will be contained in the favorite phone number list1120. In reality, the relative placement of a particular listed phone number αiwithin the comprehensive phone number list αsis more of a function of the number of times that the listed phone number αihas been recently called. For example, if the total number of times a listed phone number αiis called is high, but has not been called in the recent past, the listed phone number αimay be relatively low on the comprehensive phone number list α and thus it may not be contained in the favorite phone number list1120. In contrast, if the total number of times a listed phone number αiis called is low, but it has been called in the recent past, the listed phone number αimay be relatively high on the comprehensive phone number list α and thus it may be contained in the favorite phone number list1120. As such, it can be appreciated that the learning automaton quickly adapts to the changing calling patterns of a particular phone user1115.
It should be noted, however, that a phone number probability distribution p can alternatively be purely based on the frequency of each of the phone numbers λx. For example, given a total of n phone calls made, and a total number of times that each phone number is received f1, f2, f3. . . , the probability values pifor the corresponding listed phone calls αican be:
pi(k+1)=fin[26]
Noteworthy, each probability value piis not a function of the previous probability value pi(as characterized by learning automaton methodology), but rather the frequency of the listed phone number αiand total number of phone calls n. With the purely frequency-based learning methodology, when a new phone number αiis added to the phone list α, its corresponding probability value piwill simply be 1/n, or alternatively, some other function of the total number of phone calls n. Optionally, the total number of phone calls n is not absolute, but rather represents the total number of phone calls n made in a specific time period, e.g., the last three months, last month, or last week. In other words, the phone number probability distribution p can be based on a moving average. This provides the frequency-based learning methodology with more dynamic characteristics.
In any event, as described above, a single comprehensive phone number list α that contains all phone numbers called regardless of the time and day of the week is generated and updated. Optionally, several comprehensive phone number lists α can be generated and updated based on the time and day of the week. For example, Tables 8 and 9 below set forth exemplary comprehensive phone number lists α1and α2that respectively contain phone numbers α1iand α2ithat are called during the weekdays and weekend.
TABLE 8Exemplary Probability Values for ComprehensiveWeekday Phone Number ListListed Weekday PhoneNumberNumbers (α1i)Probability Values (pi)1349-02920.2232349-00850.2133343-39850.1684343-29220.1225328-23020.1116928-38820.0867343-10980.0738328-48930.032.........96493-38320.01197383-303-38380.00598389-38980.00599272-34830.003100213-483-33430.001
TABLE 9Exemplary Probability Values for ComprehensiveWeekend Phone Number ListListed Weekday PhoneNumberNumbers (α2i)Probability Values (pi)1343-39850.2382343-10980.1943949-482-23820.1284343-29220.1035483-48380.0856349-02920.0737349-49290.0628493-48930.047.........96202-34920.01497213-403-92320.00698389-38930.00399272-34830.002100389-38980.001
Notably, the top six locations of the exemplary comprehensive phone number lists α1and α2contain different phone numbers α1iand α2i, presumably because certain phone numbers α1i(e.g., 349-0085, 328-2302, and 928-3882) were mostly only called during the weekdays, and certain phone numbers α2i(e.g., 343-1098, 949-482-2382 and 483-4838) were mostly only called during the weekends. The top six locations of the exemplary comprehensive phone number lists α1and α2also contain common phone numbers α1iand α2i, presumably because certain phone numbers α1iand α2i(e.g., 349-0292, 343-3985, and 343-2922) were called during the weekdays and weekends. Notably, these common phone numbers α1iand α2iare differently ordered in the exemplary comprehensive phone number lists α1and α2, presumably because the phone user's1115weekday and weekend calling patterns have differently influenced the ordering of these phone numbers. Although not shown, the comprehensive phone number lists α1and α2can be further subdivided, e.g., by day and evening.
When there are multiple comprehensive phone number lists α that are divided by day and/or time, the phone selection module1225, outcome evaluation module1230, probability update module1220, and intuition module1215operate on the comprehensive phone number lists α based on the current day and/or time (as obtained by a clock or calendar stored and maintained by the control circuitry1135). Specifically, the intuition module1215selects the particular comprehensive list α that will be operated on. For example, during a weekday, the intuition module1215will select the comprehensive phone number lists α1, and during the weekend, the intuition module1215will select the comprehensive phone number lists α2.
The phone selection module1225will maintain the ordering of all of the comprehensive phone number lists α, but will select the phone number subset αsfrom the particular comprehensive phone number lists α selected by the intuition module1215. For example, during a weekday, the phone selection module1225will select the favorite phone number list αsfrom the comprehensive phone number list α1, and during the weekend, the phone selection module1225will select the favorite phone number list αsfrom the comprehensive phone number list α2. Thus, it can be appreciated that the particular favorite phone number list1120displayed to the phone user1115will be customized to the current day, thereby increasing the chances that the next phone number λxcalled by the phone user1115will be on the favorite phone number list1120for convenient selection by the phone user1115.
The outcome evaluation module1230will determine if the currently called phone number λxmatches a phone number αicontained on the comprehensive phone number list α selected by the intuition module1215and generate an outcome value β based thereon, and the intuition module1215will accordingly modify the phone number probability distribution p corresponding to the selected comprehensive phone number list α. For example, during a weekday, the outcome evaluation module1230determines if the currently called phone number λxmatches a phone number αicontained on the comprehensive phone number list α1, and the intuition module1215will then modify the phone number probability distribution p corresponding to the comprehensive phone number list α1. During a weekend, the outcome evaluation module1230determines if the currently called phone number λxmatches a phone number αicontained on the comprehensive phone number list α2, and the intuition module1215will then modify the phone number probability distribution p corresponding to the comprehensive phone number list α2.
In the illustrated embodiment, the outcome evaluation module1230, probability update module1220, and intuition module1215only operate on the comprehensive phone number list α and were not concerned with the favorite phone number list αs. It was merely assumed that a phone number αicorresponding to a frequently and recently called phone number αithat was not currently in the selected phone number subset αswould eventually work its way into the favorite phone number list1120, and a phone number αicorresponding to a seldom called phone number αithat was currently in the selected phone number subset αswould eventually work its way off of the favorite phone number list1120.
Optionally, the outcome evaluation module1230, probability update module1220, and intuition module1215can be configured to provide further control over this process to increase the chances that the next called phone number λxwill match a phone number αiin the selected phone number list αsfor display to the user1115as the favorite phone number list1120.
For example, the outcome evaluation module1230may generate an outcome value β equal to “1” if the currently called phone number λxmatches a phone number αiin the previously selected phone number subset αs, “0” if the currently called phone number λxdoes not match a phone number αion the comprehensive phone number list α, and “2” if the currently called phone number λxmatches a phone number αion the comprehensive phone number list α, but not in the previously selected phone number subset αs. If the outcome value is “0” or “1”, the intuition module1215will direct the probability update module1220as previously described. If the outcome value is “2”, however, the intuition module1215will not direct the probability update module1220to update the phone number probability distribution p using a learning methodology, but instead will assign a probability value pito the listed phone number αi. For example, the assigned probability value pimay be higher than that corresponding to the last phone number αiin the selected phone number subset αs, in effect, replacing that last phone number αiwith the listed phone number αicorresponding to the currently called phone number λx. The outcome evaluation module1230may generate an outcome value β equal to other values, e.g., “3” if the a phone number λxcorresponding to a phone number αinot in the selected phone number subset αshas been called a certain number of times within a defined period, e.g., 3 times in one day or 24 hours. In this case, the intuition module1215may direct the probability update module1220to assign a probability value pito the listed phone number αi, perhaps placing the corresponding phone number αion the favorite phone number list αs.
As another example to provide better control over the learning process, the phone number probability distribution p can be subdivided into two sub-distributions p1and p2, with the first sub-distribution p1corresponding to the selected phone number subset αs, and the second sub-distribution p2corresponding to the remaining phone numbers αion the comprehensive phone number list α. In this manner, the first and second sub-distributions p1and p2will not affect each other, thereby preventing the relatively high probability values picorresponding to the favorite phone number list αsfrom overwhelming the remaining probability values pi, which might otherwise slow the learning of the automaton. Thus, each of the first and second sub-distributions p1and p2are independently updated with the same or even different learning methodologies. Modification of the probability update module1220can be accomplished by the intuition module1215in the foregoing manners.
The intuition module1215may also prevent any one probability value pifrom overwhelming the remaining probability values piby limiting it to a particular value, e.g., 0.5. In this sense, the learning module1210will not converge to any particular probability value pi, which is not the objective of the mobile phone1100. That is, the objective is not to find a single favorite phone number, but rather a list of favorite phone numbers that dynamically changes with the phone user's1115changing calling patterns. Convergence to a single probability value piwould defeat this objective.
So far, it has been explained that the listing program1200uses the instantaneous outcome value β as a performance index φ in measuring its performance in relation to its objective of maintaining favorite phone number list1120to contain future called telephone numbers. It should be appreciated, however, that the performance of the listing program1200can also be based on a cumulative performance index φ. For example, the listing program1200can keep track of a percentage of the called phone numbers λxthat match phone numbers αiin the selected phone number subset αsor a consecutive number of called phone numbers λxthat do not match phone numbers αinot found in the selected phone number subset αs, based on the outcome value β, e.g., whether the outcome value β equals “2.” Based on this cumulative performance index φ, the intuition module1215can modify the learning speed or nature of the learning module1210.
It has also been described that the phone user1115actions encompass phone numbers λxfrom phone calls made by the mobile phone1100(i.e., outgoing phone calls) that are used to generate the outcome values β. Alternatively or optionally, the phone user1115actions can also encompass other information to improve the performance of the listing program1200. For example, the phone user1115actions can include actual selection of the called phone numbers λxfrom the favorite phone number list αs. With this information, the intuition module1215can, e.g., remove phone numbers αithat have not been selected by the phone user1115, but are nonetheless on the favorite phone number list1120. Presumably, in these cases, the phone user1115prefers to dial this particular phone number λxusing the number keys1145and feels he or she does not need to select it, e.g., if the phone number is well known to the phone user1115. Thus, the corresponding listed phone number αiwill be replaced on the favorite phone number list αswith another phone number αi.
As another example, the phone user1115actions can include phone numbers from phone calls received by the mobile phone1100(i.e., incoming phone calls), which presumably correlate with the phone user's1115calling patterns to the extent that the phone number that is received represents a phone number that will likely be called in the future. In this case, the listing program1200may treat the received phone number similar to the manner in which it treats a called phone number λx, e.g., the outcome evaluation module1230determines whether the received phone number is found on the comprehensive phone number list α and/or the selected phone number subset αs, and the intuition module1215accordingly modifies the phone number probability distribution p based on this determination. Alternatively, a separate comprehensive phone number list can be maintained for the received phone numbers, so that a separate favorite phone number list associated with received phone numbers can be displayed to the user.
As still another example, the outcome value β can be time-based in that the cumulative time of a specific phone call (either incoming or outgoing) can be measured to determine the quality of the phone call, assuming that the importance of a phone call is proportional to its length. If the case of a relatively lengthy phone call, the intuition module1215can assign a probability value (if not found on the comprehensive phone number list α) or increase the probability value (if found on the comprehensive phone number list α) of the corresponding phone number higher than would otherwise be assigned or increased. In contrast, in the case of a relatively short phone call, the intuition module1215can assign a probability value (if not found on the comprehensive phone number list α) or increase the probability value (if found on the comprehensive phone number list α) of the corresponding phone number lower than would otherwise be assigned or increased. When measuring the quality of the phone call, the processing can be performed after the phone call is terminated.
Having now described the structure of the listing program1200, the steps performed by the listing program1200will be described with reference toFIG. 20. In this process, the intuition module1215does not distinguish between phone numbers αithat are listed in the phone number subset αsand those that are found on the remainder of the comprehensive phone number list α.
First, the outcome evaluation module1230determines whether a phone number λxhas been called (step1305). Alternatively or optionally, the evaluation module1230may also determine whether a phone number λxhas been received. If a phone number λxhas not been received, the program1200goes back to step1305. If a phone number λxhas been called and/or received, the outcome evaluation module1230determines whether it is on the comprehensive phone number list α and generates an outcome value β in response thereto (step1315). If so β=1), the intuition module1215directs the probability update module1220to update the phone number probability distribution p using a learning methodology to increase the probability value picorresponding to the listed phone number αi(step1325). If not (β=0), the intuition module1215generates a corresponding phone number αiand assigns a probability value pito it, in effect, adding it to the comprehensive phone number list α (step1330).
The phone number selection module1225then reorders the comprehensive phone number list α, and selects the phone number subset αstherefrom, and in this case, the listed phone numbers αiwith the highest probability values pi(e.g., the top six) (step1340). The phone number subset αsis then displayed to the phone user1115as the favorite phone number list1120(step1345). The listing program1200then returns to step1305, where it is determined again if phone number λxhas been called and/or received.
Referring toFIG. 21, the operation of the listing program1200will be described, wherein the intuition module1215does distinguish between phone numbers αithat are listed in the phone number subset αsand those that are found on the remainder of the comprehensive phone number list α.
First, the outcome evaluation module1230determines whether a phone number λxhas been called and/or received (step1405). If a phone number λxhas been called and/or received, the outcome evaluation module1230determines whether it matches a phone number αiin either of the phone number subset αs(in effect, the favorite phone number list1120) or the comprehensive phone number list α and generates an outcome value β in response thereto (steps1415and1420). If the phone number λxmatches a phone number αion the favorite phone number list αs(β=1), the intuition module1215directs the probability update module1220to update the phone number probability distribution p (or phone number probability sub-distributions p1and p2) using a learning methodology to increase the probability value picorresponding to the listed phone number ai(step1425). If the called phone number λxdoes not match a phone number αion the comprehensive phone number list (β=0), the intuition module1215generates a corresponding phone number αiand assigns a probability value pito it, in effect, adding it to the comprehensive phone number list α (step1430). If the called phone number λxdoes not match a phone number αion the favorite phone number list αs, but matches one on the comprehensive phone number list α (β=2), the intuition module1215assigns a probability value pito the already listed phone number αito, e.g., place the listed phone number αiwithin or near the favorite phone number list αs(step1435).
The phone number selection module1225then reorders the comprehensive phone number list α, and selects the phone number subset αstherefrom, and in this case, the listed phone numbers αiwith the highest probability values pi(e.g., the top six) (step1440). The phone number subset αsis then displayed to the phone user1115as the favorite phone number list1120(step1445). The listing program1200then returns to step1405, where it is determined again if phone number λxhas been called and/or received.
Referring toFIG. 22, the operation of the listing program1200will be described, wherein the intuition module1215distinguishes between weekday and weekend phone calls.
First, the outcome evaluation module1230determines whether a phone number λxhas been called (step1505). Alternatively or optionally, the evaluation module1230may also determine whether a phone number λxhas been received. If a phone number λxhas not been received, the program1200goes back to step1505. If a phone number λxhas been called and/or received, the intuition module1215determines whether the current day is a weekend day or a weekend (step1510). If the current day is a weekday, the weekday comprehensive phone list α1 is operated on in steps1515(1)-1545(1) in a similar manner as the comprehensive phone list α is operated on in steps1415-1440inFIG. 21. In this manner, a favorite phone number list1120customized to weekday calling patterns is displayed to the phone user1115. If the current day is a weekend day, the weekend comprehensive phone list α2is operated on in steps1515(2)-1545(2) in a similar manner as the comprehensive phone list α is operated on in steps1415-1440inFIG. 21. In this manner, a favorite phone number list1120customized to weekend calling patterns is displayed to the phone user1115. Optionally, rather than automatically customizing the favorite phone number list1120to the weekday or weekend for display to the phone user1115, the phone user1115can select which customized favorite phone number list1120will be displayed. The listing program1200then returns to step1505, where it is determined again if phone number λxhas been called and/or received.
More specific details on the above-described operation of the mobile phone1100can be found in the Computer Program Listing Appendix attached hereto and previously incorporated herein by reference. It is noted that the file “Intuition Intelligence-mobilephone-outgoing.doc” generates a favorite phone number list only for outgoing phone calls, that is, phone calls made by the mobile phone. It does not distinguish between the favorite phone number list and the remaining phone numbers on the comprehensive list when generating outcome values, but does distinguish between weekday phone calls and weekend phone calls. The file “Intuition Intelligence-mobilephone-incoming.doc” generates a favorite phone number list only for incoming phone calls; that is, phone calls received by the mobile phone. It does not distinguish between the favorite phone number list and the remaining phone numbers on the comprehensive list when generating outcome values, and does not distinguish between weekday phone calls and weekend phone calls.
It should be noted that the files “Intuition Intelligence-mobilephone-outgoing.doc” and “Intuition Intelligence-mobilephone-incoming.doc” simulation programs were designed to emulate real-world scenarios and to demonstrate the learning capability of the priority listing program. To this end, the software simulation is performed on a personal computer with Linux Operating System Mandrake Version 8.2. This operating system was selected because the MySQL database, PHP and Apache Web Server are natively built in. The MySQL database acts as a repository and stores the call logs and tables utilized in the programs. The MySQL database is a very fast, multi-user relational database management system that is used for storing and retrieving information. The PHP is a cross-platform, Hyper Text Markup Language (HTML)-embedded, server-side, web scripting language to provide and process dynamic content. The Apache Web Server is a public-domain web server that receives a request, processes a request, and sends the response back to the requesting entity. Because a phone simulator was not immediately available, the phone call simulation was performed using a PyWeb Deckit Wireless Application Protocol (WAP) simulator, which is a front-end tool/browser that emulates the mobile phone, and is used to display wireless language content debug the code. It is basically a browser for handheld devices. The Deckit transcoding technology is built-in to allow one to test and design the WAP site offline. The transcoding is processed locally on the personal computer.
Single-User Television Channel Listing Program
The afore-described listing programs can be used for other applications besides prioritizing and anticipating watched television channels on a telephone. For example, referring toFIG. 23, a priority listing program1700(shown inFIG. 25) developed in accordance with the present inventions is described in the context of a television remote control1600. The remote control1600comprises a keypad1620through which a remote control user1615(shown inFIG. 25) can remotely control a television (not shown), and which contains standard keys, such as number keys1625, a channel up and down key1630, a volume up and down key1632, a scroll/selection keys1635, and various other function keys. Referring further toFIG. 24, the remote control1600further includes keypad circuitry1640, control circuitry1645, memory1650, a transmitter1655, and an infrared (IR) emitter (or alternatively a light emitting diode (LED))1660. The keypad circuitry1640decodes the signals from the keypad1620, as entered by the remote control user1615, and supplies them to the control circuitry1645. The control circuitry1645then provides the decoded signals to the transmitter1655, which wirelessly transmits the signals to the television through the IR emitter1660. The memory1650stores programs that are executed by the control circuitry1645for basic functioning of the remote control1600. In many respects, these elements are standard in the industry, and therefore their general structure and operation will not be discussed in detail for purposes of brevity.
In addition to the standard features that typical remote controls have, however, the keypad1620contains a favorite channel key1665referred to as a “MYFAV” key. Much like the channel up or down keys1630, operation of the favorite channel key1665immediately tunes (or switches) the television from the current television channel to the next television channel. Repetitive operation of the favorite channel key1665will switch the television from this new current television channel to the next one, and so on. Unlike the channel up or down keys1630, however, the next television channel will not necessarily be the channel immediately above or below the current channel, but will tend to be one of the favorite television channels of the remote control user1615.
It should be noted that rather than immediately and automatically switching television channels to a favorite television channel, operation of the favorite channel key1665can cause favorite television channel lists to be displayed on the television, similar to the previously described favorite phone number lists that were displayed on the mobile phone1100. These lists will contain television channels that correspond to the remote control user1615favorite television channels, as determined by the remote control1600. Once displayed on the television, the user can use the scroll/selection key1635on the keypad1620to select a desired channel from the favorite television channel list.
In any event, the priority listing program1700, which is stored in the memory1650and executed by the control circuitry1645, dynamically updates a comprehensive television channel list (described in further detail below) from which the next television channel will be selected. Preferably, the first channel on the comprehensive television channel list will be selected, then the second channel, then the third channel, and so on. The program1700updates the comprehensive television channel list based on the user's1615television watching pattern. For example, the program1700may maintain the comprehensive television channel list based on the number of times a television channel has been watched and the recent activity of the television channel, such that the comprehensive television channel list will likely contain a television channel that the remote control user1615is anticipated to watch at any given time. For example, if channels 2, 4, 6, and 7 have recently been watched numerous times, the program1700will tend to maintain these channels at the top of the comprehensive television channel list, so that they will be selected when the remote control user1615operates the favorite television channel key1665.
To further improve the accuracy of anticipating the next channel that will be watched by the remote control user1615, the program1700may optionally maintain several comprehensive television channel lists based on temporal information, such as, e.g., the day of the week (weekend or weekday) and/or time of day (day or evening). For example, a user1615may tend to watch a specific set of channels (e.g., 2, 4, and 8) between 8 pm and 10 pm on weekdays, and other set of channels (2, 5, and 11) between 3 pm and 6 pm on weekends. Or a user1615may tend to watch news programs between 10 pm and 12 pm on weekdays, and cartoons between 10 am and 12 pm on weekends. Thus, to further refine the process, the comprehensive television channel list can be divided into sublists that are selected and applied based on the current day of the week and/or time of the day.
To ensure that television channels that are quickly switched are not registered as being watched, the program1700only assumes that a program is watched if the remote control user1615has continuously watched the television channel for more than a specified period of time (e.g., five minutes). Thus, a television channel will only affect the comprehensive television channel list if this period of time is exceeded. This period of time can be fixed for all lengths of television programs, or optionally, can be based on the length of the television program (e.g., the longer the television program, the longer the time period). Optionally, programming information contained in a device, such as, e.g., a set top box or a video cassette recorder, can be used to determine if a television program is actually watched or not.
It should also be noted that although only a single user is illustrated, multiple users can obviously use the remote control1600. In this case, usage of the remote control1600by multiple users will be transparent to the program1700, which will maintain the comprehensive television channel list as if a single user was always using the remote control1600. As will be described in further detail below, the program can be modified to maintain a television channel list for each of the users1615, so that the television channel patterns of one user do not dilute or interfere with the television channel patterns of another user. In this manner, the comprehensive television channel list can be customized to the particular user that is currently operating the remote control1600.
As will be described in further detail below, the listing program1700uses the existence or non-existence of a watched television channel on a comprehensive television channel list as a performance index φ in measuring its performance in relation to its objective of ensuring that the comprehensive channel list will include the future watched television channel, so that the remote control user1615is not required to “surf” through all of the television channels or manually punch in the television channel using the number keys. In this regard, it can be said that the performance index φ is instantaneous. Alternatively or optionally, the listing program1700can also use the location of the television channel on the comprehensive channel list as a performance index φ.
Referring now toFIG. 25, the listing program1700includes a probabilistic learning module1710and an intuition module1715, which are specifically tailored for the remote control1600. The probabilistic learning module1710comprises a probability update module1720, a television channel selection module1725, and an outcome evaluation module1730. Specifically, the probability update module1720is mainly responsible for learning the remote control user's1615television watching habits and updating the previously described comprehensive television channel list α that places television channels in the order that they are likely to be watched in the future during any given time period. The outcome evaluation module1730is responsible for evaluating the comprehensive channel list α relative to current television channels λxwatched by the remote control user1615. The channel selection module1725is mainly responsible for selecting a television channel from the comprehensive channel list α upon operation of the favorite television channel key1665. Preferably, this is accomplished by selecting the channel at the top of the comprehensive channel list α, then the second channel, third channel, and so on, as the favorite television channel key1665is repeatedly operated. The intuition module1715is responsible for directing the learning of the listing program1700towards the objective of selecting the television channel that is likely to be the remote control user's1615next watched television channel. In this case, the intuition module1715operates on the probability update module1720, the details of which will be described in further detail below.
To this end, the channel selection module1725is configured to receive a television channel probability distribution p from the probability update module1720, which is similar to equation [1] and can be represented by the following equation:
p(k)=[p1(k),p2(k),p3(k) . . .pn(k)], [1-3]where piis the probability value assigned to a specific television channel αi; n is the number of television channels αion the comprehensive channel list α, and k is the incremental time at which the television channel probability distribution was updated.
Based on the television channel probability distribution p, the channel selection module1725generates the comprehensive channel list α, which contains the listed television channels αiordered in accordance with their associated probability values pi. For example, the first listed television channel αiwill be associated with the highest probability value pi, while the last listed television channel αiwill be associated with the lowest probability value pi. Thus, the comprehensive channel list α contains all television channels ever watched by the remote control user1615and is unlimited. Optionally, the comprehensive channel list α can contain a limited amount of television channels αi, e.g., 10, so that the memory1650is not overwhelmed by seldom watched television channels, which may eventually drop off of the comprehensive channel list α.
It should be noted that a comprehensive television channel list α need not be separate from the television channel probability distribution p, but rather the television channel probability distribution p can be used as the comprehensive channel list α to the extent that it contains a comprehensive list of television channels αimatching all of the watched television channels λx. However, it is conceptually easier to explain the aspects of the listing program1700in the context of a comprehensive television channel list that is ordered in accordance with the corresponding probability values pi, rather than in accordance with the order in which they are listed in the television channel probability distribution p.
From the comprehensive channel list α, the channel selection module1725selects the television channel αithat the television will be switched to. In the preferred embodiment, the selected television channel αiwill be that which corresponds to the highest probability value pi, i.e., the top television channel αion the comprehensive channel list α. The channel selection module1725will then select the next television channel αithat the television will be switched to, which preferably corresponds to the next highest probability value pi, i.e., the second television channel αion the comprehensive channel list α, and so on. As will be described in further detail below, this selection process can be facilitated by using a channel list pointer, which is incremented after each channel is selected, and reset to “1” (so that it points to the top channel) after a television channel has been deemed to be watched or after the last channel on the comprehensive channel list α has been reached.
As an example, consider Table 10, which sets forth in exemplary comprehensive television channel list α with associated probability values pi.
TABLE 10Exemplary Probability Values for ComprehensiveTelevision Channel ListNumberListed Television Channels (αi)Probability Values (pi)120.2862110.254340.1424260.1145350.097690.0547480.0338760.012950.00810150.003
In this exemplary case, channel 2, then channel 11, then channel 4, and so on, will be selected as the television channels to which the television will be sequentially switched. Optionally, these channels can selected as a favorite television channel list to be displayed on the television, since they are associated with the top three probability values pi.
The outcome evaluation module1730is configured to receive a watched television channel λxfrom the remote control user1615via the keypad1620of the remote control1600. For example, the remote control user1615can switch the television to the television channel λxusing the number keys1625or channel-up or channel-down keys1630on the keypad1620, operating the favorite channel key1665on the keypad1620, or through any other means, including voice activation. In this embodiment, the television channel λxcan be selected from a complete set of television channels λ, i.e., all valid television channels that can be watched on the television. As previously discussed, the switched television channel will be considered to be a watched television channel only after a certain period of time has elapsed while the television is on that television channel. The outcome evaluation module1730is further configured to determine and output an outcome value β that indicates if the currently watched television channel λxmatches a television channel αion the comprehensive channel list α. In the illustrated embodiment, the outcome value β equals one of two predetermined values: “1” if the currently watched television channel λxmatches a television channel αion the comprehensive channel list α, and “0” if the currently watched television channel λxdoes not match a television channel αion the comprehensive channel list α.
It can be appreciated that unlike in the duck game300where the outcome value β is partially based on the selected game move αi, the outcome value β is technically not based on the listed television channel αiselected by the channel selection module1725, but rather whether a watched television channel λxmatches a television channel αion the comprehensive channel list α irrespective of whether it is the selected television channel. It should be noted, however, that the outcome value β can optionally or alternatively be partially based on a selected television channel.
The intuition module1715is configured to receive the outcome value α from the outcome evaluation module1730and modify the probability update module1720, and specifically, the television channel probability distributions, based thereon. Specifically, if the outcome value β equals “0,” indicating that the currently watched television channel λxdoes not match a television channel αion the comprehensive channel list α, the intuition module1715adds the watched television channel λxto the comprehensive channel list α as a listed television channel αi.
The television channel αican be added to the comprehensive channel list α in a variety of ways, including in the manner used by the program1700to add a telephone number in the mobile phone1100. Specifically, the location of the added television channel αion the comprehensive channel list α depends on the probability value piassigned or some function of the probability value piassigned.
For example, in the case where the number of television channels αiis not limited, or the number of television channels αihas not reached its limit, the television channel αimay be added by assigning a probability value pito it and renormalizing the television channel probability distribution p in accordance with the following equations:
pi(k+1)=f(x); [27]
pj(k+1)=pj(k)(1−f(x));j≠i[28]where i is the added index corresponding to the newly added television channel αi, piis the probability value corresponding to television channel αiadded to the comprehensive channel list α,f(x) is the probability value piassigned to the newly added television channel αi, pjis each probability value corresponding to the remaining television channels αjon the comprehensive channel list α, and k is the incremental time at which the television channel probability distribution was updated.
In the illustrated embodiment, the probability value piassigned to the added television channel αiis simply the inverse of the number of television channels αion the comprehensive channel list α, and thus f(x) equals 1/(n+1), where n is the number of television channels on the comprehensive channel list α prior to adding the television channel αi. Thus, equations [27] and [28] break down to:
pi(k+1)=1n+1;[27-1]pj(k+1)=pj(k)nn+1;j≠i[28-1]
In the case where the number of television channels αiis limited and has reached its limit, the television channel a with the lowest corresponding priority value piis replaced with the newly watched television channel λxby assigning a probability value pito it and renormalizing the television channel probability distribution p in accordance with the following equations:
pi(k+1)=f(x);[29]pj(k+1)=pj(k)∑j≠inpj(k)(1-f(x));j≠i[30]where i is the index used by the removed television channel αi, piis the probability value corresponding to television channel αiadded to the comprehensive channel list α,f(x) is the probability value pmassigned to the newly added television channel ai, pjis each probability value corresponding to the remaining television channels αjon the comprehensive channel list α, and k is the incremental time at which the television channel probability distribution was updated.
As previously stated, in the illustrated embodiment, the probability value piassigned to the added television channel αiis simply the inverse of the number of television channels αion the comprehensive channel list α, and thus f(x) equals 1/n, where n is the number of television channels on the comprehensive channel list α. Thus, equations [35] and [36] break down to:
pi(k+1)=1n;[29-1]pj(k+1)=pj(k)∑j≠inpj(k)(n-1n);j≠i[30-1]
It should be appreciated that the speed in which the automaton learns can be controlled by adding the television channel αito specific locations within the television channel probability distributions. For example, the probability value piassigned to the added television channel αican be calculated as the mean of the current probability values pi, such that the television channel αiwill be added to the middle of the comprehensive channel list α to effect an average learning speed. The probability value piassigned to the added television channel αican be calculated as an upper percentile (e.g. 25%) to effect a relatively quick learning speed. Or the probability value piassigned to the added television channel αican be calculated as a lower percentile (e.g. 75%) to effect a relatively slow learning speed. It should be noted that if there is a limited number of television channels αion the comprehensive channel list α, thereby placing the lowest television channels αiin the likelihood position of being deleted from the comprehensive channel list α, the assigned probability value pishould be not be so low as to cause the added television channel αito oscillate on and off of the comprehensive channel list α when it is alternately watched and not watched.
In any event, if the outcome value β received from the outcome evaluation module1730equals “1,” indicating that the currently watched television channel λxmatches a television channel αion the comprehensive channel list α, the intuition module1715directs the probability update module1720to update the television channel probability distribution p using a learning methodology. In the illustrated embodiment, the probability update module1720utilizes a linear reward-inaction P-type update.
As an example, assume that a currently watched television channel λxmatches a television channel α5on the comprehensive channel list α, thus creating an outcome value β=1. Assume also that the comprehensive channel list α currently contains 10 television channels αi. In this case, general updating equations [6] and [7] can be expanded using equations [10] and [11], as follows:
p5(k+1)=p5(k)+∑j=1j≠510apj(k);p1(k+1)=p1(k)-ap1(k);p2(k+1)=p2(k)-ap2(k);p3(k+1)=p3(k)-ap3(k);p4(k+1)=p4(k)-ap4(k);p6(k+1)=p6(k)-ap6(k);p7(k+1)=p7(k)-ap7(k);p8(k+1)=p8(k)-ap8(k);p9(k+1)=p9(k)-ap9(k);p10(k+1)=p10(k)-ap10(k)
Thus, the corresponding probability value p5is increased, and the television channel probability values picorresponding to the remaining television channels αiare decreased. The value of α is selected based on the desired learning speed. The lower the value of α, the slower the learning speed, and the higher the value of α, the higher the learning speed. In the preferred embodiment, the value of α has been chosen to be 0.03. It should be noted that the penalty updating equations [8] and [9] will not be used, since in this case, a reward-penalty P-type update is not used.
Thus, it can be appreciated that, in general, the more a specific listed television channel αiis watched relative to other listed television channels αi, the more the corresponding probability value piis increased, and thus the higher that listed television channel αiis moved up on the comprehensive channel list α. As such, the chances that the listed television channel αiwill be selected will be increased. In contrast, the less a specific listed television channel αiis watched relative to other listed television channels αi, the more the corresponding probability value piis decreased (by virtue of the increased probability values picorresponding to the more frequently watched listed television channels αi), and thus the lower that listed television channel αiis moved down on the comprehensive channel list α. As such, the chances that the listed television channel αiwill be selected by the channel selection module1725will be decreased.
It can also be appreciated that due to the nature of the learning automaton, the relative movement of a particular listed television channel αiis not a matter of how many times the television channel αiis watched, and thus, the fact that the total number of times that a particular listed television channel αihas been watched is high does not ensure that it will be selected. In reality, the relative placement of a particular listed television channel αion the comprehensive channel list αsis more of a function of the number of times that the listed television channel αihas been recently watched. For example, if the total number of times a listed television channel αiis watched is high, but has not been watched in the recent past, the listed television channel αimay be relatively low on the comprehensive channel list α and thus it may not be selected. In contrast, if the total number of times a listed television channel αiis watched is low, but it has been watched in the recent past, the listed television channel αimay be relatively high on the comprehensive channel list α and thus it may be selected. As such, it can be appreciated that the learning automaton quickly adapts to the changing watching patterns of a particular remote control user1615.
It should be noted, however, that a television channel probability distribution p can alternatively be purely based on the frequency of each of the television channels λx. For example, given a total of n television channels watched, and a total number of times that each television channel is watched f1, f2, f3. . . , the probability values pifor the corresponding listed television channels αican be:
pi(k+1)=fin[31]
Noteworthy, each probability value piis not a function of the previous probability value pi(as characterized by learning automaton methodology), but rather the frequency of the listed television channel αiand total number of watched television channels n. With the purely frequency-based learning methodology, when a new television channel αiis added to the comprehensive channel list α, its corresponding probability value piwill simply be 1/n, or alternatively, some other function of the total number of watched television channels n. Optionally, the total number of watched television channels n is not absolute, but rather represents the total number of watched television channels n made in a specific time period, e.g., the last three months, last month, or last week. In other words, the television channel probability distribution p can be based on a moving average. This provides the frequency-based learning methodology with more dynamic characteristics.
In any event, as described above, a single comprehensive television channel list α that contains all television channels watched regardless of the time and day of the week is generated and updated. Optionally, several comprehensive television channel lists α can be generated and updated based on the time and day of the week. For example, Tables 11 and 12 below set forth exemplary comprehensive television channel lists α1and α2that respectively contain television channels α1iand α2ithat are watched during the weekdays and weekend.
TABLE 11Exemplary Probability Values for ComprehensiveWeekday Television Channel ListListed Weekday TelevisionNumberChannels (α1i)Probability Values (pi)140.2632110.1883480.1624290.133590.103620.0757880.0338380.025970.01410150.004
TABLE 12Exemplary Probability Values for ComprehensiveWeekend Television Channel ListListed Weekend TelevisionNumberChannels (α1i)Probability Values (pi)1110.256270.209340.1534380.1255930.0836290.0677480.043890.032920.0201080.012
Notably, the top five locations of the exemplary comprehensive television channel lists αl and α2contain different television channels α1iand α2i, presumably because certain television channels α1i(e.g., 48, 29, and 9) were mostly only watched during the weekdays, and certain television channels α2i(e.g., 7, 38, and 93) were mostly only watched during the weekends. The top five locations of the exemplary comprehensive television channel lists α1and α2also contain common television channels α1iand α2i, presumably because certain television channels α1iand α2i(e.g., 4 and 11) were watched during the weekdays and weekends. Notably, these common television channels α1iand α2iare differently ordered in the exemplary comprehensive television channel lists α1and α2, presumably because the remote control user's1615weekday and weekend watching patterns have differently influenced the ordering of these television channels. Although not shown, the single comprehensive list α can be subdivided, or the comprehensive channel lists α1and α2can be further subdivided, e.g., by day and evening.
When there are multiple comprehensive television channel lists α that are divided by day and/or time, the channel selection module1725, outcome evaluation module1730, probability update module1720, and intuition module1715operate on the comprehensive channel lists α based on the current day and/or time (as obtained by a clock or calendar stored and maintained by the control circuitry1645). Specifically, the intuition module1715selects the particular comprehensive list α that will be operated on. For example, during a weekday, the intuition module1715will select the comprehensive channel lists α1, and during the weekend, the intuition module1715will select the comprehensive channel lists α2.
The channel selection module1725will maintain the ordering of all of the comprehensive channel lists α, but will select the television channel from the particular comprehensive television channel list α selected by the intuition module1715. For example, during a weekday, the channel selection module1725will select the television channel from the comprehensive channel list α1, and during the weekend, the channel selection module1725will select the television channel from the comprehensive channel list α2. Thus, it can be appreciated that the particular television channel to which the television will be switched will be customized to the current day, thereby increasing the chances that the next television channel λxwatched by the remote control user1615will be the selected television channel.
The outcome evaluation module1730will determine if the currently watched television channel λxmatches a television channel αion the comprehensive channel list a selected by the intuition module1715and generate an outcome value λxbased thereon, and the intuition module1715will accordingly modify the television channel probability distribution p corresponding to the selected comprehensive television channel list α. For example, during a weekday, the outcome evaluation module1730determines if the currently watched television channel λxmatches a television channel αion the comprehensive channel list α1, and the intuition module1715will then modify the television channel probability distribution p corresponding to the comprehensive channel list α1. During a weekend, the outcome evaluation module1730determines if the currently watched television channel λxmatches a television channel αion the comprehensive channel list α2, and the intuition module1715will then modify the television channel probability distribution p corresponding to the comprehensive channel list α2.
The intuition module1715may also prevent any one probability value pifrom overwhelming the remaining probability values piby limiting it to a particular value, e.g., 0.5. In this sense, the learning module1710will not converge to any particular probability value pi, which is not the objective of the remote control1600. That is, the objective is not to find a single favorite television channel, but rather a list of favorite television channels that dynamically changes with the remote control user's1615changing watching patterns. Convergence to a single probability value piwould defeat this objective.
So far, it has been explained that the listing program1700uses the instantaneous outcome value β as a performance index φ in measuring its performance in relation to its objective of select a television channel that will be watched by the remote control user1615. It should be appreciated, however, that the performance of the listing program1700can also be based on a cumulative performance index φ. For example, the listing program1700can keep track of a percentage of the watched television channels λxthat match a television channel αion the comprehensive channel list α or portion thereof, or a consecutive number of watched television channels λxthat do not match a television channel αion the comprehensive channel list α or portion thereof, based on the outcome value β. Based on this cumulative performance index φ, the intuition module1715can modify the learning speed or nature of the learning module1710.
Optionally, the outcome value β can be time-based in that the cumulative time that a television channel is watched can be measured to determine the quality of the watched television channel. If the case of a relatively lengthy time the television channel is watched, the intuition module1715can assign a probability value (if not found on the comprehensive channel list α) or increase the probability value (if found on the comprehensive channel list α) of the corresponding television channel higher than would otherwise be assigned or increased. In contrast, in the case of a relatively short time the television channel is watched, the intuition module1715can assign a probability value (if not found on the comprehensive channel list α) or increase the probability value (if found on the comprehensive channel list α) of the corresponding television channel lower than would otherwise be assigned or increased. When measuring the quality of the watched television channel, the processing can be performed after the television channel is switched.
It should be noted that, in the case where a comprehensive television channel list is displayed on the screen of the television for selection by the remote control user1615, the channel selection module1725may optionally select a television channel subset from the comprehensive channel list α for eventual display to the remote control user1615as a comprehensive television channel list. Updating of a comprehensive television channel list that contains a television channel subset, and selection of the comprehensive television channel list for display, is similar to that accomplished in the previously described mobile phone1100when updating the comprehensive phone number list and selecting the favorite phone number therefrom.
Although the program1700is described as being stored within a remote control1600, it can be distributed amongst several components within a remote control television system, or another component within the remote control television system, e.g., within the television, itself, or some other device associated with the television, e.g., a cable box, set top box, or video cassette recorder. In addition, although the program1700is described for use with a television, it should be noted that it can be applied to other consumer electronic equipment on which users can watch or listen to programs by switching channels, e.g., stereo equipment, satellite radio, MP3 player, Web devices, etc.
Having now described the structure of the listing program1700, the steps performed by the listing program1700will be described with reference toFIG. 26. First, the outcome evaluation module1730determines whether a television channel λxhas been newly watched (step1805). As previously discussed, this occurs when a predetermined period of time has elapsed while the television is tuned to the television channel. If a television channel λxhas been newly watched, the outcome evaluation module1730determines whether it matches a television channel αion the comprehensive channel list α and generates an outcome value β in response thereto (step1815). If so (β=1), the intuition module1715directs the probability update module1720to update the television channel probability distributions using a learning methodology to increase the probability value picorresponding to the listed television channel αi(step1825). If not (β=0), the intuition module1715generates a corresponding television channel αiand assigns a probability value pito it, in effect, adding it to the comprehensive channel list α (step1830). The channel selection module1725then reorders the comprehensive channel list α (step1835), sets the channel list pointer to “1” (step1840), and returns to step1805.
If a television channel a has not been newly watched at step1805, e.g., if the predetermined period of time has not expired, the channel selection module1725determines whether the favorite channel key1665has been operated (step1845). If so, the channel selection module1725selects a listed television channel αi, and in this case, the listed television channel αicorresponding to the channel list pointer (step1850). The television is then switched to the selected television channel αi(step1855), and the channel list pointer is incremented (step1860). After step1860, or if the favorite channel key1665has not been operated at step1845, the listing program1700then returns to step1805, where it is determined again if television channel λxhas been watched.
Referring now toFIG. 27, another priority listing program2000(shown inFIG. 28) developed in accordance with the present inventions is described in the context of another television remote control1900. The remote control1900is similar to the previously described remote control1600with the exception that it comprises a keypad1920that alternatively or optionally contains a specialized favorite channel key1965referred to as a “LINKFAV” key. The specialized favorite channel key1965is similar to the generalized favorite channel key1965in that its operation immediately and automatically switches the television from the current television channel to a next television channel that tends to correspond to one of the user's1615favorite television channels. Unlike with the generalized favorite channel key1965, however, the next television channel will tend to be one of the user's1615favorite television channels based on the specific (as opposed to a general) channel watching pattern that the remote control user1615is currently in.
To this end, the program2000dynamically updates a plurality of linked comprehensive television channel lists from which the next television channel will be selected. Like with the generalized comprehensive television channel list, the program2000may maintain each of the linked comprehensive television channel lists based on the number of times a television channel has been watched, and the recent activity of the television channel. The linked comprehensive television channel lists are arranged and updated in such a manner that a selected one will be able to be matched and applied to the specific channel watching pattern that the remote control user1615is currently in.
Specifically, each linked comprehensive television channel list corresponds to a value of a specified television channel parameter, such that, when the remote control user1615operates the specialized favorite television key1965, the linked comprehensive television channel list corresponding to the value exhibited by the currently watched television channel can be recalled, and thus, the next channel selected from that recalled list will be more likely to be the television channel that the remote control user1615desires to watch. A channel parameter can, e.g., include a switched channel number (in which case, the values may be 2, 3, 4, 5, etc.), channel type (in which case, the values may be entertainment, news, drama, sports, comedy, education, food, movies, science fiction, cartoon, action, music, shopping, home), channel age/gender (in which case, the values may be adult, teenage, kids, women, etc.), or channel rating (in which case, the values may be TV-Y, TV-Y7, TV-14, TV-MA, etc.). If the channel parameter is a channel type, channel age/gender or channel rating, a device (such as, e.g., a set top box, television or video cassette recorder) can be used to extract this information from the incoming program signal.
For example, if the channel parameter is a switched channel number, and if the television has been recently and often switched from channel 2 to channels 4, 8, and 11, or vice versa, the program2000will tend to maintain channels 4, 8, and 11 at the top of a list corresponding to channel 2, so that these favorite channels will be selected when the remote control user1615is currently watching channel 2 and operates the specialized favorite television channel key1965. As another example, if the channel parameter is a channel type, and if movie channels 14 (TNT), 24 (MAX), and 26 (HBO3) have been recently watched numerous times, the program2000will tend to maintain these channels at the top of a list corresponding to movie channels, so that these favorite channels will be selected when the remote control user1615is currently watching a movie channel and operates the specialized favorite television channel key1965.
As with the previously described program1700, the program2000may optionally maintain the specialized television channel lists based on temporal information, such as, e.g., the day of the week (weekend or weekday) and/or time of day (day or evening). Thus, the specialized television channel lists can be further divided into sublists that are selected and applied based on the current day of the week and/or time of the day.
As with the program1700, the program2000only assumes that a program is watched if the remote control user1615has continuously watched the television channel for more than a specified period of time (e.g., five minutes), so that a television channel will only affect the linked comprehensive television channel lists when this period of time is exceeded. Also, in the case where the television channel parameter is a switched channel number, selection of the next television channel from the specialized television channel lists, which would quickly vary with time, would be unstable without requiring a certain period of time to expire before a television channel can be considered watched. For example, without this feature, operation of the specialized favorite television channel key1965may switch the television from channel 2 to 4 if channel 4 is at the top of the linked comprehensive television channel list corresponding with channel 2, and then further operation of the specialized favorite television channel key1965may switch the television from channel 4 back to channel 2 if channel 2 is at the top of the linked comprehensive television channel list corresponding to channel 4. The channel would then switch back in and forth between channel 2 and 4 when the specialized favorite television channel key1965is further operated.
Thus, an assumption that a channel is a currently watched channel after a period of time has expired would prevent this adverse effect by forcing the program2000to select one linked comprehensive television channel list from which the unique channels can be sequentially selected. For example, when the currently watched television channel is channel 2, operation of the specialized favorite channel key1965may switch the television channel from channel 2 those channels that are on the linked comprehensive television channel list corresponding to channel 2. The predetermined period of time will, therefore, have to expire before the linked television channel, i.e., channel 2, is changed to the currently watched television channel.
As briefly discussed with respect to the program1700, the program2000can be modified to maintain each of the specialized television channel lists for multiple users, so that the television channel patterns of one user do not dilute or interfere with the television channel patterns of another user. It should be noted, however, that in many cases, the specific channel watching patterns will be so unique to the users1615that the separate maintenance of the lists will not be necessary-at least with respect to the specialized favorite television channel key1965. For example, a specific television channel pattern that is unique to kids (e.g., cartoons) will typically not conflict with a specific television channel pattern that is unique to adults (e.g., news).
As will be described in further detail below, the listing program2000uses the existence or non-existence of a watched television channel on the pertinent linked comprehensive television channel list as a performance index φ in measuring its performance in relation to its objective of ensuring that the pertinent linked channel list will include the future watched television channel, so that the remote control user1615is not required to “surf” through all of the television channels or manually punch in the television channel using the number keys. In this regard, it can be said that the performance index φ is instantaneous. Alternatively or optionally, the listing program2000can also use the location of the television channel in the pertinent linked comprehensive channel list as a performance index φ.
Referring now toFIG. 28, the listing program2000includes a probabilistic learning module2010and an intuition module2015, which are specifically tailored for the remote control1900. The probabilistic learning module2010comprises a probability update module2020, a television channel selection module2025, and an outcome evaluation module2030.
Specifically, the probability update module2020is mainly responsible for learning the remote control user's1615television watching habits and updating linked comprehensive television channel lists α1-αm that places television channels αiin the order that they are likely to be watched in the future during any given time period. m equals the number of values associated with the pertinent television channel parameter. For example, if the television channel parameter is a channel number, and there are 100 channels, m equals 100. If the television channel parameter is a channel type, and there are ten channel types, m equals 10.
The outcome evaluation module2030is responsible for evaluating the linked comprehensive channel lists α1-αm relative to current television channels λxwatched by the remote control user1615. The channel selection module2025is mainly responsible for selecting a television channel αifrom the pertinent linked comprehensive channel list α, upon operation of the favorite television channel key1965. Preferably, this is accomplished by selecting the channel αiat the top of the pertinent linked comprehensive channel list α, then the second channel, third channel, and so on, as the specialized favorite channel key1965is repeatedly operated.
The intuition module2015is responsible for directing the learning of the listing program2000towards the objective of selecting the television channel αithat is likely to be the remote control user's1615next watched television channel αi. In this case, the intuition module2015selects the pertinent linked comprehensive channel list α, and operates on the probability update module2020, the details of which will be described in further detail below.
To this end, the channel selection module2025is configured to receive multiple television channel probability distributions p1-pm from the probability update module2020, which is similar to equation [1] and can be represented by the following equation:
p1(k)=[p11(k),p12(k),p13(k) . . .p1n(k)];
p2(k)=[p21(k),p22(k),p23(k) . . .p2n(k)];
p3(k)=[p31(k),p32(k),p33(k) . . .p3n(k)]
.
.
.
.
pm(k)=[pm1(k),pm2(k),pm3(k) . . .pmn(k)] [1-4]where m is the number of probability distributions, i.e., the number of values associated with the pertinent television channel parameter; piis the probability value assigned to a specific television channel αi, n is the number of television channels αion the comprehensive channel list α, and k is the incremental time at which the television channel probability distribution was updated.
Based on the television channel probability distribution p1-pm, the channel selection module2025generates the linked comprehensive channel lists α1-αm, each of which contains the listed television channels αiordered in accordance with their associated probability values pi. Thus, each linked comprehensive channel list α contains all watched television channels αiexhibiting a value corresponding to the list. For example, if the television channel parameter is a switched channel number, each linked comprehensive channel list α will be linked with a channel number and will contain all television channels αiever watched by the remote control user1615that were switched to and from that television channel. If the television channel parameter is a channel type, each linked comprehensive channel list α will be linked with a channel type and will contain all television channels αiof that channel type ever watched by the remote control user1615. As with the comprehensive channel list α described with respect to the program1700, each of the linked comprehensive channel lists α1-αm can be unlimited, or optionally, contain a limited amount of television channels αi, e.g., 10, so that the memory1650is not overwhelmed by seldom watched television channels.
As with the previously described comprehensive television channel list α, each of the linked comprehensive channel lists α1-αm need not be separate from their respective television channel probability distributions p1-pm, but rather a television channel probability distribution p can be used as a linked comprehensive channel list α to the extent that it contains a comprehensive list of the linked television channels αi.
From the linked comprehensive channel lists α1-αm, the channel selection module2025selects the list corresponding to the television channel parameter value exhibited by the current television channel watched, and then selects, from that list, a television channel αithat the television will be switched to. In the preferred embodiment, the selected television channel αiwill be that which corresponds to the highest probability value pi, i.e., the top television channel αiin the selected linked comprehensive channel list α. The channel selection module2025will then select the next television channel αithat the television will be switched to, which preferably corresponds to the next highest probability value pi, i.e., the second television channel αiin the selected linked comprehensive channel list α, and so on. As previously described above, this selection process can be facilitated by using a channel list pointer. In the preferred embodiment, once the last television channel αiis selected, the channel selection module2025will select the current channel that was watched prior to initiation of the selection process, and will then go through the selected linked comprehensive channel list α again. Optionally, the channel selection module2025will only cycle through a subset of the selected linked comprehensive channel list α, e.g., the top three.
As an example, consider Table 13, which sets forth exemplary linked comprehensive television channel lists α with associated probability values pi. In this case, the channel parameter is a switched channel number.
TABLE 13Exemplary Probability Values for Linked ComprehensiveTelevision Channel ListsListed TelevisionNumberChannels (αi)Probability Values (pi)Television Channel 21110.3102260.283340.202490.0935350.0576950.0227390.012850.011970.00710380.003Television Channel 4120.280280.238390.1684380.1195300.0846830.032750.028870.0189330.00910930.004...Television Channel 1001930.2942480.2283840.1724110.013590.0826880.0617940.027870.0139380.00810980.002
In this exemplary case, if the currently watched channel is channel 2, channel 11, then channel 26, then channel 4, and so on, will be selected as the television channels to which the television will be sequentially switched. If the currently watched channel is channel 4, channels 2, 8, and 9, and so on, will be selected. If the currently watched channel is channel 100, channels 93, 48, and 84 will be selected. Notably, there is no corresponding linked comprehensive television channel list α for channel 3, presumably because channel 3 has never been watched.
As with the previously described outcome evaluation module1730, the outcome evaluation module2030is configured to receive a watched television channel λxfrom the remote control user1615via the keypad1920using any one of a variety of manners. The outcome evaluation module2030is further configured to determine and output an outcome value β that indicates if the currently watched television channel λxmatches a television channel αion the linked comprehensive channel list α, as selected by the intuition module2015described below. In the illustrated embodiment, the outcome value β equals one of two predetermined values: “1” if the currently watched television channel λxmatches a television channel αion the selected linked comprehensive channel list α, and “0” if the currently watched television channel λxdoes not match a television channel αion the selected linked comprehensive channel list α.
The intuition module2015is configured to select the linked comprehensive channel list α corresponding to the television channel parameter value exhibited by the currently watched television channel λx. This selected linked comprehensive channel list α is the list that is operated on by the outcome evaluation module2030described above. The intuition module2015is further configured to receive the outcome value β from the outcome evaluation module2030and modify the probability update module2020, and specifically, the television channel probability distributions corresponding to the selected linked comprehensive channel list α. Specifically, if the outcome value β equals “0,” indicating that next watched television channel λxdoes not match a television channel αion the selected linked comprehensive channel list α, the intuition module2015adds the watched television channel λxto the selected linked comprehensive channel list α as a listed television channel αi. The television channel αican be added to the selected linked comprehensive channel list α in a manner similarly described with respect to the intuition module1715. If the outcome value β received from the outcome evaluation module2030equals “1,” indicating that the next watched television channel λxmatches a television channel αion the selected linked comprehensive channel list α, the intuition module2015directs the probability update module2020to update the corresponding television channel probability distribution p in the manner previously described with respect to intuition module1715.
Optionally, the intuition module2015can be configured to select the linked comprehensive channel list α corresponding to the next watched television channel λxand update that based on whether the current watched television channel λxis found on that list-in effect, creating a bilateral link between the currently watched television channel λxand the next watched television channel λx, rather than just a unilateral link from the currently watched television channel λxto the next watched television channel λx. Thus, in this case, two linked comprehensive channel lists α will be updated for each television channel λxthat is watched (one for the currently watched television channel λx, and one for the next watched television channel λx).
In the case where the channel selection module2025selects a subset of the selected linked comprehensive television channel list α (e.g., for display to the remote control user1615as a favorite television channel list) or cycles through a subset of the linked comprehensive television channel list α, the outcome evaluation module2030may generate more outcome values β. For example, in this case, the outcome evaluation module2030may generate an outcome value β equal to “1” if the currently watched television channel λxmatches a television channel αiin the previously selected television channel subset, “0” if the currently watched television channel a does not match a television channel αion the selected linked comprehensive television channel list α, and “2” if the currently watched television channel λxmatches a television channel αion the selected linked comprehensive phone number list α, but not in the previously selected television channel subset. If the outcome value is “0” or “1”, the intuition module2015will direct the probability update module2020as previously described. If the outcome value is “2”, however, the intuition module2015will not direct the probability update module2020to update the probability distribution p using a learning methodology, but instead will assign a probability value pito the listed television channel αi. For example, the assigned probability value pimay be higher than that corresponding to the last television channel aiin the selected television channel subset, in effect, replacing that last television channel αiwith the listed television channel aicorresponding to the currently watched television channel λx.
The program2000can include other optional features, such as those previously described with respect to the program1700. For example, for each television channel, several linked comprehensive television channel lists α can be generated and updated based on the time and day of the week. The intuition module2015may also prevent any one probability value pifrom overwhelming the remaining probability values piwithin each linked probability distribution p by limiting it to a particular value, e.g., 0.5. Also, the performance of the listing program2000can be based on a cumulative performance index φ rather than an instantaneous performance index φ. The outcome value β can be time-based in that the cumulative time that a television channel is watched can be measured to determine the quality of the watched television channel.
Having now described the structure of the listing program2000, the steps performed by the listing program2000will be described with reference toFIG. 29. First, the outcome evaluation module2030determines whether a television channel λxhas been newly watched (step2105). As previously discussed, this occurs when a predetermined period of time has elapsed while the television is tuned to the television channel. If a television channel λxhas been newly watched, the intuition module2015selects the linked comprehensive channel list α corresponding to a television channel parameter value exhibited by the currently watched channel λx(step2110). For example, if the television channel parameter is a switched channel number, and the currently watched channel λxis channel 2, the outcome evaluation module2030will select the linked comprehensive channel list α corresponding to channel 2. If the television channel parameter is a channel type, and the currently watched channel λxis a sports channel, the outcome evaluation module2030will select the linked comprehensive channel list a corresponding to sports.
The outcome evaluation module2030then determines whether the watched television channel λxmatches a television channel αion the selected linked comprehensive channel list α (step2115). If so (β=1), the intuition module2015directs the probability update module2020to update the corresponding television channel probability distributions using a learning methodology to increase the probability value picorresponding to the listed television channel ai(step2125). If not (β=0), the intuition module2015generates a corresponding television channel αiand assigns a probability value pito it, in effect, adding it to the selected linked comprehensive channel list α (step2130). The channel selection module2025then reorders the selected linked comprehensive channel list α (step2135), sets the channel list pointer for the selected linked comprehensive channel list α to “1” (step2140), and returns to step2105.
If a television channel λxhas not been newly watched at step2105, e.g., if the predetermined period of time has not expired, the channel selection module2025determines whether the favorite channel key1965has been operated (step2145). If so, the channel selection module2025selects the linked comprehensive channel list α corresponding to the television channel parameter value exhibited by the currently watched channel λx(step2150), and then selects a listed television channel therefrom, and in this case, the listed television channel αicorresponding to the channel list pointer for the selected linked comprehensive channel list a (step2155). The television is then switched to the selected television channel αi(step2160), and the channel list pointer for the selected linked comprehensive channel list α is incremented (step2165). After step2165, or if the favorite channel key1965has not been operated at step2145, the listing program2000then returns to step2105, where it is determined again if a television channel λxhas been newly watched.
More specific details on the above-described operation of the television remote controls1600and1900can be found in the Computer Program Listing Appendix attached hereto and previously incorporated herein by reference. It is noted that the file “Intuition Intelligence-remote.doc” implements both functionalities for the generalized favorite channel key1665and the specialized favorite channel key1965, with the channel parameter being a switched television channel. It should be noted that the files “Intuition Intelligence-remote.doc” was designed to emulate real-world remote control usage scenarios and to demonstrate the learning and intelligence capability. Only the functions relating to the generalized and specialized favorite channel keys1665and1965are set forth.
To this end, the remote control simulation is performed on a personal computer with the Windows 98 OS with Microsoft Access 2000 database support and Media Player. Media Player plays an AVI video file to simulate as if user is watching a program on TV. The Access 2000 database acts as a repository and stores all the lists with all relevant data including the probability values, count of the channel watched, channel number, name, etc., as well as channel number, channel name, channel type, age group, rating, etc. The code and algorithm is implemented in Visual Basic 5.0 with the help of Access 2000 database support.
As the program has access to more information than a simple remote (which has no Program details, like rating, cast, etc.) it uses a combination of the data available from the cable box or set top box or other mechanisms which can provide the additional information. The program can also implemented without that additional programming information as well. The access to this additional information, however, provides help in demonstrating more sophisticated demo.
Although the previous embodiments in the context of single-user scenarios, it should be appreciated that these embodiments may be modified to operate in the context of multi-user scenarios, such as those described with respect to FIGS. 30-70 of U.S. patent application Ser. No. 10/231,875, which has previously been expressly incorporated herein by reference.
Although particular embodiments of the present inventions have been shown and described, it will be understood that it is not intended to limit the present inventions to the preferred embodiments, and it will be obvious to those skilled in the art that various changes and modifications may be made without departing from the spirit and scope of the present inventions. Thus, the present inventions are intended to cover alternatives, modifications, and equivalents, which may be included within the spirit and scope of the present inventions as defined by the claims. All publications, patents, and patent applications cited herein are hereby incorporated by reference in their entirety for all purposes.
Claims
- A method of providing learning capability to a computer game, comprising: identifying a move performed by said game player;selecting one of a plurality of game moves based on a game move probability distribution comprising a plurality of probability values corresponding to said plurality of game moves;determining an outcome of said selected game move relative to said identified player move;updating said game move probability distribution based on said outcome;maintaining a relative score value between said game player and said computer game;determining a current skill level of said game player relative to a current skill level of said computer game based on said maintained relative score;modifying one or more of said game move selection, said outcome determination, and said game move probability distribution update;and repeating the foregoing steps to modify said current skill level of said computer game to continuously and dynamically match said current skill level of the said game player.
- The method of claim 1 , wherein said selected game move is selected in response to said identified player move.
- The method of claim 1 , wherein said modification comprises modifying said game move selection.
- The method of claim 3 , wherein said plurality of game moves are organized into a plurality of game move subsets, said selected game move is selected from one of said plurality of game move subsets, and said subsequent game move selection comprises selecting another of said plurality of game move subsets.
- The method of claim 4 , wherein said game move selection comprises selecting another game move from said another of said plurality of game move subsets in response to another player move.
- The method of claim 1 , wherein said modification comprises modifying said outcome determination.
- The method of claim 1 , wherein said modification comprises modifying said game move probability distribution update.
- The method of claim 1 , wherein said outcome is determined by performing a collision technique on said identified player move and said selected game move.
- The method of claim 1 , wherein said selected game move corresponds to the highest probability value within said game move probability distribution.
- The method of claim 1 , wherein said selected game move corresponds to a pseudo-random selection of a probability value within said game move probability distribution.
- The method of claim 1 , wherein said plurality of game moves is performed by a game-manipulated object, and said identified player move is performed by a user-manipulated object.
- The method of claim 11 , wherein said plurality of game moves comprises discrete movements of said game-manipulated object.
- The method of claim 11 , wherein said plurality of game moves comprises a plurality of delays related to a movement of said game-manipulated object.
- The method of claim 11 , wherein said identified player move comprises a simulated shot taken by said user-manipulated object.
- The method of claim 11 , wherein said game-manipulated object and said user-manipulated object are visual to said game player.
- The method of claim 1 , wherein said game move probability distribution is updated using a learning automaton.
- A computer game, comprising: a processor;a probabilistic learning module, when executed by the processor, configured for learning a plurality of game moves in response to a plurality of moves performed by a game player, wherein the probabilistic learning module includes: a game move selection module configured for selecting one of a plurality of game moves, said game move selection being based on a game move probability distribution comprising a plurality of probability values corresponding to said plurality of game moves;an outcome evaluation module configured for determining an outcome of said selected game move relative to said identified player move;and a probability update module configured for updating said game move probability distribution based on said outcome;and an intuition module, when executed by the processor, configured for maintaining a relative score value between said game player and said computer game, determining a current skill level of said game player relative to a current skill level of said computer game based on said maintained relative score, and modifying a functionality of said probabilistic learning module, thereby modifying said current skill level of said computer game to continuously and dynamically match said current skill level of the said game player.
- The computer game of claim 17 , wherein said intuition module is configured for modifying said functionality of said probabilistic learning module by modifying a functionality of said game move selection module.
- The computer game of claim 17 , wherein said intuition module is configured for modifying said functionality of said probabilistic learning module by modifying a functionality of said outcome evaluation module.
- The computer game of claim 17 , wherein said intuition module is configured for modifying said functionality of said probabilistic learning module by modifying a functionality of said probability update module.
- The computer game of claim 17 , wherein said plurality of game moves is performed by a game-manipulated object, and said identified player move is performed by a user-manipulated object.
- The computer game of claim 21 , wherein said plurality of game moves comprises discrete movements of said game-manipulated object.
- The computer game of claim 21 , wherein said plurality of game moves comprises a plurality of delays related to a movement of said game-manipulated object.
- The computer game of claim 21 , wherein said identified player move comprises a simulated shot taken by said user-manipulated object.
- The computer game of claim 21 , wherein said game-manipulated object and said user-manipulated object are visual to said game player.
- The computer game of claim 17 , wherein said probabilistic learning module comprises a learning automaton.
Disclaimer: Data collected from the USPTO and may be malformed, incomplete, and/or otherwise inaccurate.