U.S. Pat. No. 9,272,202
Method and Apparatus for Tracking of a Plurality of Subjects in a Video Game
AssigneeEdge 3 Technologies, Inc.
Issue DateFebruary 10, 2013
Illustrative Figure
Abstract
Method, computer program and system for tracking movement of a subject. The method includes receiving data from a distributed network of camera sensors employing one or more emitted light sources associated with one or more of the one or more camera sensors to generate a volumetric three-dimensional representation of the subject, identifying a plurality of clusters within the volumetric three-dimensional representation that correspond to motion features indicative of movement of the motion features of the subject, presenting one or more objects on one or more three dimensional display screens, and using the plurality of fixed position sensors to track motion of the motion features of the subject and track manipulation of the motion features of the volumetric three-dimensional representation to determine interaction of one or more of the motion features of the subject and one or more of the one or more objects on the three dimensional display.
Description
It should be noted that the figures are not necessarily drawn to scale and that elements of similar structures or functions are generally represented by like reference numerals for illustrative purposes throughout the figures. It also should be noted that the figures are only intended to facilitate the description of the various embodiments described herein. The figures do not describe every aspect of the teachings disclosed herein and do not limit the scope of the claims. DETAILED DESCRIPTION OF THE PREFERRED EMBODIMENTS A method and system for vision-based interaction in a virtual environment is disclosed. According to one embodiment, a computer-implemented method comprises receiving data from a plurality of sensors to generate a meshed volumetric three-dimensional representation of a subject. A plurality of clusters is identified within the meshed volumetric three-dimensional representation that corresponds to motion features. The motion features include hands, feet, knees, elbows, head, and shoulders. The plurality of sensors is used to track motion of the subject and manipulate the motion features of the meshed volumetric three-dimensional representation. Each of the features and teachings disclosed herein can be utilized separately or in conjunction with other features and teachings to provide a method and system for vision-based interaction in a virtual environment. Representative examples utilizing many of these additional features and teachings, both separately and in combination, are described in further detail with reference to the attached drawings. This detailed description is merely intended to teach a person of skill in the art further details for practicing preferred aspects of the present teachings and is not intended to limit the scope of the claims. Therefore, combinations of features disclosed in the following detailed description may not be necessary to practice the teachings in the broadest sense, and are instead taught merely to describe particularly representative examples of the ...
It should be noted that the figures are not necessarily drawn to scale and that elements of similar structures or functions are generally represented by like reference numerals for illustrative purposes throughout the figures. It also should be noted that the figures are only intended to facilitate the description of the various embodiments described herein. The figures do not describe every aspect of the teachings disclosed herein and do not limit the scope of the claims.
DETAILED DESCRIPTION OF THE PREFERRED EMBODIMENTS
A method and system for vision-based interaction in a virtual environment is disclosed. According to one embodiment, a computer-implemented method comprises receiving data from a plurality of sensors to generate a meshed volumetric three-dimensional representation of a subject. A plurality of clusters is identified within the meshed volumetric three-dimensional representation that corresponds to motion features. The motion features include hands, feet, knees, elbows, head, and shoulders. The plurality of sensors is used to track motion of the subject and manipulate the motion features of the meshed volumetric three-dimensional representation.
Each of the features and teachings disclosed herein can be utilized separately or in conjunction with other features and teachings to provide a method and system for vision-based interaction in a virtual environment. Representative examples utilizing many of these additional features and teachings, both separately and in combination, are described in further detail with reference to the attached drawings. This detailed description is merely intended to teach a person of skill in the art further details for practicing preferred aspects of the present teachings and is not intended to limit the scope of the claims. Therefore, combinations of features disclosed in the following detailed description may not be necessary to practice the teachings in the broadest sense, and are instead taught merely to describe particularly representative examples of the present teachings.
In the following description, for the purposes of explanation, specific nomenclature is set forth to facilitate an understanding of the various inventive concepts disclosed herein. However, it will be apparent to one skilled in the art that these specific details are not required in order to practice the various inventive concepts disclosed herein.
The present invention also relates to apparatus for performing the operations herein. This apparatus may be specially constructed for the required purposes, or it may comprise a general-purpose computer selectively activated or reconfigured by a computer program stored in the computer. Such a computer program may be stored in a computer-readable storage medium, such as, but is not limited to, any type of disk including floppy disks, optical disks. CD-ROMs, and magnetic-optical disks, read-only memories, random access memories, EPROMs, EEPROMs, magnetic or optical cards, or any type of media suitable for storing electronic instructions, and each coupled to a computer system bus.
The methods presented herein are not inherently related to any particular computer or other apparatus. Various general-purpose systems may be used with programs in accordance with the teachings herein, or it may prove convenient to construct more specialized apparatus to perform the required method steps. The required structure for a variety of these systems will appear from the description below. In addition, the present invention is not described with reference to any particular programming language. It will be appreciated that a variety of programming languages may be used to implement the teachings of the invention as described herein.
Moreover, the various features of the representative examples and the dependent claims may be combined in ways that are not specifically and explicitly enumerated in order to provide additional useful embodiments of the present teachings. It is also expressly noted that all value ranges or indications of groups of entities disclose every possible intermediate value or intermediate entity for the purpose of original disclosure, as well as for the purpose of restricting the claimed subject matter. It is also expressly noted that the dimensions and the shapes of the components shown in the figures are designed to help to understand how the present teachings are practiced, but not intended to limit the dimensions and the shapes shown in the examples.
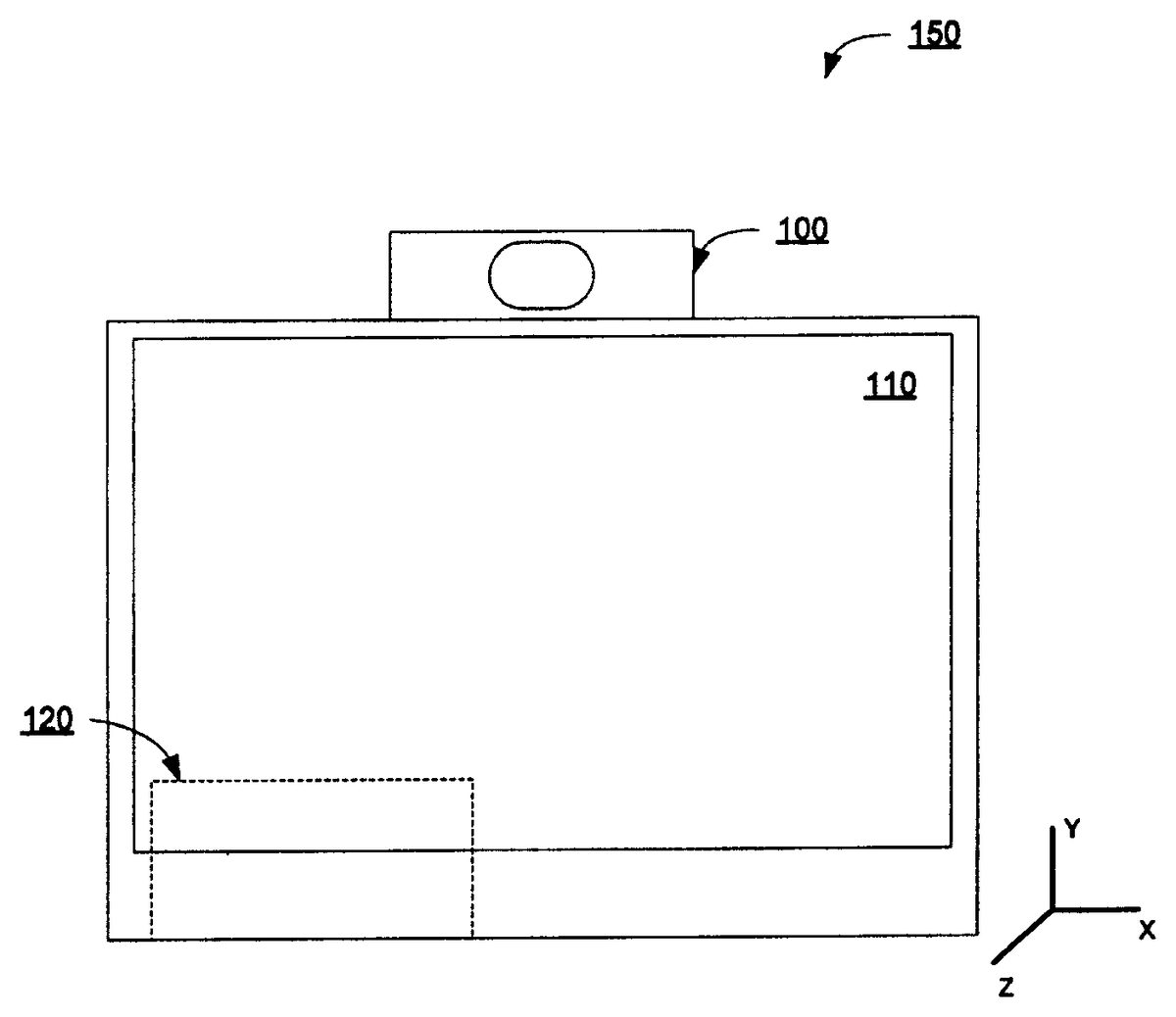
FIG. 1illustrates an exemplary vision-based virtual reality system150, according to one embodiment. The vision-based virtual reality system150includes a three-dimensional sensor100, a display110and a computer120. According to one embodiment, three-dimensional sensor100is a three-dimensional time-to-flight (TOF) sensor that captures the three-dimensional information of a target object. For a given point on the surface of the target object, sensor100captures the two-dimensional image and calculates the position of the object in X and Y coordinates. The Z-directional distance information from sensor100to the target object is obtained by measuring the time that light takes to travel from sensor100to the target object and back to sensor100. Because the speed of the light is known, the time measurement can be used to determine the distance to the target object. According to one embodiment, sensor100is equipped with a plurality of light sources and light sensors in a grid pattern. According to another embodiment, sensor100is equipped with a limited number of light sources and light sensors but is supplemented with a driving mechanism to move the sensors and light sources. The driving mechanism allows for a larger scanning space at a desired resolution. By aggregating the measurements of multiple points on the target object, the three-dimensional geometrical information of the target object is constructed. It is understood that other suitable three-dimensional sensing mechanisms can be used without deviating from the scope of the present invention.
Time-of-flight sensor100renders very accurate and fast position information for the target object. Sensor100and the image processing capabilities of computer120allow system150to operate in real-time.
Display110renders the image of the target object in two- or three-dimensions. When rendering the image in two-dimensions, the depth information (in the Z-direction) is not substantially used, but it may be used to trigger an event or an action. For example, if sensor100detects that the object is within a predetermined distance, an associated event is triggered.
According to one embodiment, display110is a three-dimensional display allowing user200to perceive objects in a three-dimensional virtual space. According to another embodiment, display110is a three-dimensional stereoscopic display that requires no special eyewear for user200to perceive three-dimensional virtual images. Examples of such three-dimensional stereoscopic displays are the 42-3D6W01 WOW 3D LCD DISPLAY from Koninklijke Phillips Electronics N.V., Netherlands and the 3D PLASMA DISPLAY from NTT Data Sanyo System Corporation, Japan.
Computer120integrates and processes the data from sensor100, and displays the processed data onto display110. Video pre-processing is first attempted on the acquired data. There are two types of noises which impact the quality of the acquired data; white Gaussian noise associated with rendered images from sensor100, and more importantly specularity or reflectivity noise associated with the surface specularities and reflectances of target objects. The pre-processed data including two-dimensional X and Y coordinates and Z-directional distance information is delivered to computer120and further data processing is performed to construct three-dimensional images to be shown on display110. Such data processing may include data filtering, transformations, reconstruction, interpolation, image texturing, rendering, coloring, editing, etc. Post data processing of computer120allows user200to perceive real-time events of interest while minimizing background noise on the captured data. Typically, a 20-40 Hz refresh rate is considered fast enough to avoid excessive lags, but higher refresh rates may be used to construct more realistic and natural images.
According to one embodiment, system150is used for controlling a video game using the motions and actions of the video gamer. A peripheral device is not required to control the video game. Conventional video games require physical controllers (e.g., a gamepad, keyboard, mouse, joystick or gloves)
The location of a user's hands, legs and feet are detected and measured by system150. As the positions of the body parts of the video gamer change, a software algorithm running on computer120detects those movements and creates a triggering event depending on the location, direction, pattern and speed of the movements. The triggering event creates a discrete command that is used as an input to the video game controller (not shown) or any other virtual reality systems.
FIGS. 2-5illustrate exemplary captured and processed images using three-dimensional sensor100, according to one embodiment. Gamer200stands in front of system150to play a boxing game. Sensor100captures the image of gamer200as shown in camera image240. Sensor100also measures the distance of various objects within camera image240.
FIG. 2illustrates an exemplary processed image250for capturing a left high punch motion using three-dimensional sensor100, according to one embodiment. Game controller (or computer120) is notified when gamer200throws a left high punch. Area210is highlighted on processed image250. The distance to the right arm220is also monitored to determine if a right punch is thrown.FIG. 3illustrates an exemplary processed image350for capturing a right low punch motion using three-dimensional sensor100, according to another embodiment. When gamer300throws a right low punch, area320is highlighted on processed image350and computer120is notified a right-punch event. The body of gamer300is shown in gray indicating that gamer300's body is farther away from sensor100than gamer300's fists. The relative distance from the body330of gamer300to gamer300's fists might be used to determine if a punch is thrown or not. For example, if the distance measured to the fist when subtracted from the distance to the body is greater than a predetermined value, then a punch is considered to be thrown. Referring toFIG. 2, the difference of the distances to the left fist and the body is greater than the predetermined value so that a left punch was thrown. On the other hand, the difference of the distances to the left fist and the body is smaller than the predetermined value so that a right punch was not thrown.
According to another embodiment, objects or spatial regions are tracked along various paths over time. The path itself is mapped, and data is then tracked in a four-coordinate system comprising (x, y, z, t), where x, y, z are three-dimensional spatial coordinates and t is time. As a result, various training algorithms are used on the data paths to “best-fit” the paths of predefined events.
According to one embodiment, a computational algorithm is used to detect the spatial orientation and position of the object within processed image250. If the highlighted area220is skewed towards the left side of the image250as shown inFIG. 2, system150determines that a right punch is thrown. On the other hand, if the highlighted area210is skewed towards the right side of the image250, system150determines that a left punch is thrown. It is understood that a different algorithm can be used to determine the orientation and position of an object without deviating from the scope of the present invention. For example, the orientation and position can be obtained by an artificial neural network multilayer perceptron (MLP) model through back-propagation learning based on a training database. Other learning techniques can be applied on the four-dimensional data obtained.
FIG. 4illustrates an exemplary processed image450for capturing a high block motion using three-dimensional sensor100, according to one embodiment. Gamer400raises both hands indicating a high block. This time, punches are not thrown, rather both hands are raised and areas410and420are highlighted as a result. System150identifies each fist as objects410and420within processed image450. The distances to objects410and420are calculated in three-dimensions and system150determines that gamer400intended a high block.
FIG. 5illustrates an exemplary processed image550for capturing a forward body motion using three-dimensional sensor100, according to one embodiment. Gamer500approaches sensor100, therefore the area530(the body of gamer500) fills a larger portion of processed image550. In this case, an ‘approach’ event is triggered. The opposite ‘withdraw’ event is detected when system150determines that area530decreases within processed image550. Another approach may be taken to detect such a forward body motion. Clusters leaving the main cluster (i.e. body) is monitored and temporally tracked as they traverse in a three-dimensional space. The path in which such clusters leave the main cluster may be used to identify various events and motions.
If more sensing elements are used, one can achieve a higher resolution. Therefore, depending on the application and computing resources, the resolution of sensor100might be optimized to achieve appropriate performance while providing a real-time immersive experience to a gamer.
By using different techniques and algorithms, many different events can be created and mapped to control a video game. A series of events might be monitored and recorded over a period of time to create a history- or time-dependent event and thus recognize gestures incorporating temporal characteristics. In a certain video game, a combination of user inputs may trigger a unique event. For example, if a right punch is thrown while approaching, a more damaging punch can be thrown.
A multi-player game can be played using two or more systems150, one for each player. Each system150captures the image of a player and each computer120coupled to the system150processes the data collected by sensor100and controls an individual input from the player. According to one embodiment, a single computer120may be shared to process data from multiple sensors100. According to another embodiment, a separate dedicated computer may be used to collectively process data from multiple sensors100. A special event can be created by processing the motions from multiple players, which is not possible using dedicated computers for each player.
According to one embodiment, a multi-player game connects multiple players over a network. In such cases, computer120of each system150might capture the raw data from sensor100and upload it to a network computer that processes the raw data. The networked computer also communicates with each computer120to provide visual feedback associated with the other players.
FIG. 6Ais a front-oriented perspective view of a vision-based virtual reality system650, according to one embodiment. Sensor600may be mounted in a plurality of positions with respect to the player. Multiple sensors600or601are used to form a distributed sensor network and create a meshed volumetric three-dimensional image within a confined area. The distributed network of TOF sensors allows for gesture recognition algorithms.
Sensor600is mounted using an arm at the top of vision-based virtual reality system650. Sensor601is mounted on the front side of system650or on a wall surrounding user630. Computer620displays the processed image of sensor600and/or sensor601on display610. Sensor600captures the two-dimensional image in X-Z plane and measures the negative Y-directional distance to the object under itself. Sensor601captures the two-dimensional image in X-Y plane and measure the Z-directional distance to the object placed in front of system650.
FIG. 6Bis a side-oriented view of a vision-based virtual reality system650, according to one embodiment. User630stands under a top-mounted or ceiling-mounted sensor600, which captures the three-dimensional spatial information about user630. Unlike system150, sensor600of system650is positioned above user630. Multiple sensors including wall-mounted sensor601and top-mounted sensor600, may be mounted in a different position. According to one embodiment, user630is immersed in a space surrounded by a plurality of sensors. For example, wall-mounted sensors601are positioned on the four walls surrounding user630and an additional ceiling-mounted sensor600is positioned above user630. The movements and actions of user630are captured and processed to determine discrete command inputs to the control system650. Redundant information may be obtained from multiple sensors but is useful for minimizing self occlusions as well as noise and for refining the desired command inputs that user630intended. Each wall surrounding user630may be equipped with a three-dimensional display610to provide immersive visual feedback to user630.
FIG. 7illustrates an exemplary top-oriented processed image of user630taken with top-mounted sensor600, according to one embodiment. For the purpose of illustration, the depth information is illustrated with contour lines in gray scale. Computer620runs a software algorithm that analyzes the processed image. As user630moves his/her body parts, the specific movement is captured, analyzed and compared with a library of predefined motions and events. The library of predefined motions, objects and events may be stored on computer620or any other storage devices connected to computer620. User630can create an event associated with a certain motion (or combinations of motions) and store it on the library. Depending on the result of the analysis, an appropriate action may be taken. For example, user630raises his/her left hand, and the software algorithm registers the motion as a ‘lift left hand’ event. A variety of motions can be pre-learned, trained or taught by the software algorithm.
According to on embodiment, computer620conducts two approaches for integrating new gestures: 1) supervised learning in which various Hidden Markov models are used in conjunction with Bayesian learning to refine the gesture dictionary, and 2) unsupervised learning in which self-organizing maps define a reorganization of a neural network to best match the input data.
FIG. 8illustrates an exemplary data processing flowchart, according to one embodiment. The software algorithm, as referenced above, receives raw data from a sensor (802) and processes the received raw data such as noise filtering or signal transformations from one domain to another domain for extracting specific information contained in the captured data (803). Based on the processed data, depth information is clustered and partitioned, for example, using a mean-shift algorithm (804). The three-dimensional sensor space in which user630is contained and sensor600or601covers is partitioned into discrete volumetric elements, called dual-state cuboids. The software algorithm determines whether each cuboid is populated or not by input data from user630and tracks the changes of states of all cuboids within the three-dimensional sensor space (805). If necessary, the changes of states of the cuboids are recorded for a period of time to detect a history- or time-depending motion. If a motion is detected, an appropriate output command is created and delivered to, for example, a gaming controller (806) and display610updates (807). If there is no motion detected, the output command is bypassed and display610updates (807). Without an interruption to stop, the next set of raw data is received (809) and the processes repeat.
According to one embodiment, system150,650or the combination of systems150and/or650may be used to control the actions of a video game such as Xbox 360® by Microsoft Corporation, PlayStation® 3 by Sony Computer Entertainment or Wii™ by Nintendo. Discrete commands detected by the software algorithm are linked to a control device (e.g., a gamepad, a game controller, a wireless remote controller) to control the video game. This capability allows game players the ability to control existing video games with their body motions instead of conventional video control inputs typically realized by pressing buttons, moving around the game controller. For a multi-player video game, each player is equipped with a separate system150or650to provide controls to the motion of each character in the multi-player video game.
According to another embodiment, system150,650or the combination of systems150and/or650may be used to control the movement of a virtual character within a virtual world such as Second Life by Linden Research Inc. Second Life is an Internet-based virtual world wherein a user creates his/her virtual character called Avatar, socialize and participate in individual and social activities, create and trade items with virtual money and provides services to or receives services from other virtual characters. Instead of using conventional input methods such as pressing a buttons or keys on a computer keyboard, a real action can be used to participate in those activities to add reality to the action. For example, a handshaking motion may be used to exchange handshakes with other virtual characters.
According to yet another embodiment, system150,650or the combination of systems150and/or650may be used for virtual exercises, computer augmented virtual environment (CAVE) or virtual training programs.
According to one embodiment, a set of distributed wall or ceiling mounted sensors is provided to enhance the resolution and widen the sensor space, as well as facilitate distributed vision algorithms applied to the sensor. For example, multiple sensors600or601are positioned in a grid pattern so that inter-sensory interference is minimized. The grid of sensors provides computer620with information necessary to construct a virtual interactive space surrounding user630. User630is free to move within the sensor space and the motions of user630are captured by the plurality of sensors. The locations of the sensors and the coverage space by those sensors are known.
Each sensor600or601is calibrated based on user630's bio-metrics and orientation with respect to display610. Once the calibration is done, computer620projects an initial three-dimensional image associated with the application to display610, for example user630is immersed under water. The three-dimensional aquatic environment is projected on the surrounding walls. As user630swims underwater, various types of underwater life forms emerge and interact with user630. By performing natural swimming strokes and interacting with surroundings, user630explores the three-dimensional underwater virtual environment.
According to another embodiment, virtual reality system150or650may be used for psychological treatment purposes. For example, a patient with height phobia may be initially placed in a virtual space that causes no fear. Depending on the progress of the therapy, the patient can be placed at increasing heights.
According to yet another embodiment, virtual reality system150or650may be used for occupational training purposes. For example, a soldier is placed in a virtual war zone. The soldier may be given a mission or a task to successfully finish the training program. Since the training requires physical action and reaction with the environment, the training program offers close-to-real experiences. The training program can also be easily switched without physically transporting the trainee to a different environment.
According to one embodiment, a network interface may be used to link a local station (i.e. system150or650) with one or more remote stations. Objects located in the sensor space of the remote stations may be transferred over the network to be displayed as virtual objects at the local station, therefore the sensor spaces of multiple stations can be overlapped or intertwined to create a networked and collaborated virtual space.
FIG. 9illustrates an exemplary data processing flowchart for a networked virtual reality system, according to one embodiment. The system's coordinates are mapped to the virtual environment's coordinate system to register user interactions with a virtual environment (902). A predefined or simplified mapping scheme may be used or a mapping or registration session starts to correlate the coordinate systems from the real world to the virtual world. Typically, three-dimensional coordinates and three-dimensional orientations are required to uniquely and completely map from a space to another space. After the mapping is completed, the initial content of the application is rendered on display610(903). If system150or650is connected to other remote stations through the network interface, the objects on the remote stations are also rendered on the local station as virtual objects (904). The local and remote objects might be rendered simultaneously. After the objects within the virtual space are rendered, system150or650receives data from one or more sensors600and/or601equipped therein (905) and processes and analyze the data from the sensors (906). Pertinent information caused by the user's interactions with the virtual space on the local station is transferred to all the other remote stations through the network interface and updated on the remote stations (907). The display on the local station is also updated by the user interactions on both local and remote stations (909). Same processes repeat (906-910) to continue the virtual real-time experiences.
A software development kit (SDK) may be provided to the developers of the present system. No specific machine vision or computer gaming knowledge is required to use SDK to develop an application. Using an intuitive graphical user interface, SDK allows application developers to define certain body actions and gestures, and create custom events.
The SDK is aimed for software developers of game controls. The SDK provides game developers with a set of tools to perform motion capture and analysis. According to one embodiment, the SDK takes into account the user's anatomical constraints, real-time constraints, sensor resolution, a total number of sensors, and pixel depth. The SDK identifies and tracks key segments during motion capture in three dimensions. Examples include head, shoulders, hands, feet, elbows and knees. Such segments are applicable to many games and help produce a deformable three-dimensional avatar that is capable of closely mirroring a user's physical movements. Body segments are simplified into a set of key points and are linked together to create a basic skeletal structure of the avatar. Training can then be accomplished to improve tracking and recognition accuracy by tracking the key points. To facilitate fast implementation into computer games, a visual development environment (VDE) exists for the SDK that optimizes the SDK for a particular application by graphically selecting body segments to track. For example, spheres are placed at key segments on the avatar and the paths thereof are tracked as a part of the training process. Clicking on the spheres will highlight the corresponding body segment and toggle the tracking state. This graphical feature provides a way for developing games faster and more intuitively. The resulting interface compiles into a dynamic link library to easily integrate with other code.
According to one embodiment, the networked virtual reality system may be used in a video game where each player is physically remote and connected by the network. Each player's action is locally processed and an appropriate command or update is transferred to the other's station to locally interpret the action. Alternatively, each player's local station may be connected to a central station to collect, process and distribute data to relieve the computational burden in each local station.
According to another embodiment, a user's non-photo-real image is integrated into the virtual environment. A non-photoreal avatar resembling the user is integrated and rendered into the game. This feature differentiates system150or650from other camera-based virtual reality systems (e.g., EyeToy® by Sony Computer Entertainment) in which the user's true visual data is applied to the game. An effective approach is taken to warp the user's data to best match a non-photoreal color-space associated with the game. Users can populate different characters, moods and facial expressions in the game. With different skill levels and characteristics, a user's character is allowed to change and evolve. Such character evolution represents a nonlinear transformation, such as eigen faces fusion or landmarking between the avatar and the user.
According to one embodiment, the networked virtual reality system might be used in a virtual tele-presense application such as virtual tele-conferencing. A user is immersed in a virtual environment in a virtual conference room, for example, to conduct a job interview. Remote users, for example, interviewers, are shown as virtual objects in a virtual environment whose actions and gestures are updated on the user's display610. The interactions among the users are observable to any party participating in the tele-conferencing since they are projected and updated on all the participant's display610, thus providing a pure virtual experience.
According to one embodiment, the networked virtual reality system might be used in a virtual collaboration workspace. For example, two or more users participate in a computer aided design (CAD) project. Components of the design may be manipulated by each user's gestures and actions. Users may utilize virtual pointing devices such are rulers, pencils or sticks for accurate manipulation of delicate components. All changes performed at one station by a user are updated and transferred on all other networked stations.
Common to all of the exemplary applications is the capability of two or more users to interact in a virtual space. Remote users are displayed as virtual objects, however, the virtual objects are derived from the real data at remote stations, thus the real world characteristics of the remote users are preserved. The interaction among users, therefore, becomes as natural and intuitive as if the remote users are physically present in the same place.
The usage of TOF sensors allows robust data acquisition under various lighting conditions. If a stereoscopic camera systems are used, the reconstruction of three-dimensional object data from captured images depends significantly on external lighting conditions. Since the independent light source is used to measure the depth information, system150or650provides robust data acquisition irrespective of external lighting conditions.
Another advantage of using TOF sensors is the capability of real-time data processing. The refresh rate of typical TOF sensors is 40 Hz, which is sufficiently fast for a user to sense no latency for the visual update. The biggest advantage of the present virtual reality system is the elimination of peripheral devices for controlling or providing inputs to the system. Without the need for such peripheral devices, the user's experience with the virtual environment is more natural, interactive and realistic.
Although the preferred embodiments of the present invention have been illustrated and described in detail, it will be readily apparent to those skilled in the art that various modifications may be made therein without departing from the spirit of the present invention or from the scope of the appended claims.
Claims
- A system for tracking movement of motion features of a plurality of subjects for operating a video game, comprising: a plurality of fixed position sensors comprising a distributed network of camera sensors including one or more emitted light sources associated with one or more of the one or more camera sensors, the plurality of fixed position sensors capturing data and generating a volumetric three-dimensional representation for a first subject and a second subject;a processor for identifying one or more motion features of each of the first and second subjects within the three-dimensional representation indicative of motion of one or more motion features of the first subject relative to the fixed position sensors, one or more other portions of the first subject, and one or more portions of the second subject;one or more three dimensional displays for presenting the generated volumetric three-dimensional representation for the first subject and for the second subject;and the processor further using the plurality of fixed position sensors to track motion of the one or more motion features of the first subject to determine interaction of the one or more motion features of the first subject and one or more portions of the second subject on one or more of the one or more three dimensional displays.
- The system of claim 1 , wherein the one or more three dimensional displays presents one or more objects;and wherein the plurality of fixed position sensors track motion of the one or more motion features of the first subject to determine interaction of the one or more motion features of the first subject and the one or more objects on one or more of the one or more three dimensional displays.
- The system of claim 1 , the processor further identifying one or more recognized events within the video game corresponding to the tracked motion of the first subject.
- The system of claim 3 , wherein identifying one or more events further comprises matching the motion of the first subject with an event stored in an event library associated with the video game.
- The system of claim 4 , wherein the processor further generates new events for the library associated with the video game taking into account one or more of the anatomical constraints of the first subject, sensor resolution, pixel depth and a total number of sensors.
- The system of claim 1 , wherein the processor further: acquires an image of the face of the first and second subjects playing the video game;and integrates a non-photo-real avatar resembling the acquired image of the first and second subjects into first and second characters in the video game.
- The system of claim 6 , wherein the processor further warps each of the non-photo-real avatars to best match a non-photo-real color space associated with the video game.
- The system of claim 6 , wherein each of the non-photo-real avatars changes according to one or more game conditions.
- The system of claim 8 , wherein the one or more game conditions comprises a change in skill level of a character.
- The system of claim 8 , wherein the changing of the non-photo-real avatar represents a nonlinear transformation.
- The system of claim 10 , wherein the nonlinear transformation comprises eigen faces fusion between the avatar and the subject.
- The system of claim 10 , wherein the nonlinear transformation comprises landmarking between the avatar and the subject.
- The system of claim 1 , wherein the one or more three dimensional displays comprise autostereoscopic displays.
- The system of claim 1 , wherein the one or more three dimensional displays employ a three dimensional viewing device.
- The system of claim 14 , wherein the three dimensional viewing device comprises three dimensional viewing glasses.
- The system of claim 1 , wherein the fixed position sensors are time-of-flight sensors.
- A system for tracking motion of a subject during operation of a video game, comprising: a distributed network of camera sensors employing one or more emitted light sources associated with one or more of the one or more camera sensors, at least data received from the camera sensors being used to generate a volumetric three-dimensional representation of each of a first and second subject;a processor for identifying one or more motion features of each of the first and second subjects within the three-dimensional representation indicative of motion of one or more motion features of the first subject relative to the fixed position sensors, one or more other portions of the first subject and one or more portions of the second subject;one or more three dimensional displays for representing the generated volumetric three-dimensional representations for each of the first and second subjects;and wherein the plurality of fixed position sensors are used to track motion of the one or more motion features of the first subject to determine interaction of the one or more motion features of the first subject and one or more portions of the second subject on one or more of the one or more three dimensional displays.
- The system of claim 17 , wherein the plurality of fixed position sensors comprises a distributed grid of sensors.
- The system of claim 18 , wherein the distributed grid of sensors further comprises a plurality of light sources.
- The system of claim 17 , wherein a representation of the volumetric three-dimensional representation for each of the first and second subjects is displayed on one or more of the three dimensional displays, wherein each of the volumetric three-dimensional representations move according to instructions generated by a software development kit that links the motion features to a skeletal structure.
- The system of claim 20 , wherein the one or more displays display interaction between the representations of the volumetric three-dimensional representations and one or more objects within the video game.
- The system of claim 17 , wherein the processor further identifies one or more recognized events within the video game corresponding to the tracked motion of the first subject.
- The system of claim 22 , wherein identifying one or more events by the processor further comprises matching the motion of the first subject with an event stored in an event library associated with the video game.
- The system of claim 23 , wherein the processor generates new events for the library associated with the video game taking into account one or more of the anatomical constraints of the subject, sensor resolution, pixel depth, location of light source, and a total number of sensors.
- The system of claim 17 , wherein the processor acquires an image of the face of the first and second subjects playing the video game in accordance with at least data received from the camera sensor, and integrates a non-photo-real avatar resembling the acquired image of the first and second subjects into a character in the video game.
- The system of claim 25 , wherein the non-photo-real avatars are warped by the processor to best match a non-photo-real color space associated with the video game.
- The system of claim 25 , wherein the processor changes the non-photo-real avatars according to one or more game conditions.
- The system of claim 27 , wherein the one or more game conditions comprises a change in skill level of a character controlled by one of the first and second subjects.
- The system of claim 27 , wherein the changing of the non-photo-real avatar represents a nonlinear transformation.
- The system of claim 29 , wherein the nonlinear transformation comprises eigen faces fusion between the avatar and the corresponding one of the first and second subjects.
- The system of claim 29 , wherein the nonlinear transformation comprises landmarking between the avatar and corresponding ones of the first and the second subjects.
- The system of claim 17 , wherein the one or more three dimensional displays comprise autostereoscopic displays.
- The system of claim 17 , wherein the one or more three dimensional displays employ a three dimensional viewing device.
- The system of claim 33 , wherein the three dimensional viewing device comprises three dimensional viewing glasses.
- The system of claim 17 , wherein the fixed position sensors are time-of-flight sensors.
- A non-transitory computer-readable medium having stored thereon a plurality of instructions, the plurality of instructions when executed by a computer coupled to a plurality of fixed position sensors for receiving data and one or more three dimensional displays for presenting one or more objects thereon, causes the computer to track movement of motion features of a subject operating a video game by performing the steps of: receiving data from the plurality of fixed position sensors comprising a distributed network of camera sensors employing one or more emitted light sources associated with one or more of the one or more camera sensors to generate a volumetric three-dimensional representation for a first subject and a second subject;identifying one or more motion features of each of the first and second subjects within the three-dimensional representation indicative of motion of one or more motion features of the first subject relative to the fixed position sensors one or more other portions of the first subject, and one or more portions of the second subject;presenting the generated volumetric three-dimensional representation for the first subject and for the second subjects on the one or more three dimensional displays;and using the plurality of fixed position sensors to track motion of the one or more motion features of the first subject to determine interaction of the one or more motion features of the first subject and one or more portions of the second subject on one or more of the one or more three dimensional displays.
- The computer-readable medium of claim 36 , having stored thereon additional instructions, the additional instructions when executed by the computer coupled to the plurality of fixed position sensors for receiving data and one or more three dimensional displays for presenting one or more objects thereon, cause the computer to further perform the steps of: presenting one or more objects on the one or more three dimensional displays;and using the plurality of fixed position sensors to track motion of the one or more motion features of the first subject to determine interaction of the one or more motion features of the first subject and the one or more objects on one or more of the one or more three dimensional displays.
- The computer-readable medium of claim 36 , having stored thereon additional instructions, the additional instructions when executed by a computer coupled to the plurality of fixed position sensors for receiving data and one or more three dimensional displays for presenting one or more objects thereon, cause the computer to further perform the step of identifying one or more recognized events within the video game corresponding to the tracked motion of the first subject.
- The computer-readable medium of claim 38 , wherein identifying one or more events further comprises matching the motion of the first subject with an event stored in an event library associated with the video game.
- The computer-readable medium of claim 39 , having stored thereon additional instructions, the additional instructions when executed by a computer coupled to the plurality of fixed position sensors for receiving data and one or more three dimensional displays for presenting one or more objects thereon, cause the computer to further perform the step of generating new events for the library associated with the video game taking into account anatomical constraints of the first subject, sensor resolution, pixel depth and a total number of sensors.
- The computer-readable medium of claim 36 , having stored thereon additional instructions, the additional instructions when executed by a computer coupled to the plurality of fixed position sensors for receiving data and one or more three dimensional displays for presenting one or more objects thereon, cause the computer to further perform the steps of: acquiring an image of the face of the first and second subjects playing the video game;and integrating a non-photo-real avatar resembling the acquired image of the first and second subjects into first and second characters in the video game.
- The computer-readable medium of claim 41 , wherein each of the non-photo-real avatars is warped to best match a non-photo-real color space associated with the video game.
- The computer-readable medium of claim 41 , wherein each of the non-photo-real avatars changes according to one or more game conditions.
- The computer-readable medium of claim 43 , wherein the one or more game conditions comprises a change in skill level of a character.
- The computer-readable medium of claim 43 , wherein the changing of the non-photo-real avatar represents a nonlinear transformation.
- The computer-readable medium of claim 45 , wherein the nonlinear transformation comprises eigen faces fusion between the avatar and the subject.
- The computer-readable medium of claim 45 , wherein the nonlinear transformation comprises landmarking between the avatar and the subject.
- The computer-readable medium of claim 36 , wherein the one or more three dimensional displays comprise autostereoscopic displays.
- The computer-readable medium of claim 36 , wherein the one or more three dimensional displays employ a three dimensional viewing device.
- The computer-readable medium of claim 49 , wherein the three dimensional viewing device comprises three dimensional viewing glasses.
- The computer-readable medium of claim 36 , wherein the fixed position sensors are time-of-flight sensors.
Disclaimer: Data collected from the USPTO and may be malformed, incomplete, and/or otherwise inaccurate.