U.S. Pat. No. 7,837,543
REWARD-DRIVEN ADAPTIVE AGENTS FOR VIDEO GAMES
AssigneeMicrosoft Corporation
Issue DateApril 30, 2004
Illustrative Figure
Abstract
Adaptive agents are driven by rewards they receive based on the outcome of their behavior during actual game play. Accordingly, the adaptive agents are able to learn from experience within the gaming environment. Reward-driven adaptive agents can be trained at either or both of game-time or development time. Computer-controlled agents receive rewards (either positive or negative) at individual action intervals based on the effectiveness of the agents' actions (e.g., compliance with defined goals). The adaptive computer-controlled agent is motivated to perform actions that maximize its positive rewards and minimize is negative rewards.
Description
DETAILED DESCRIPTION FIG. 1illustrates two game characters100and102with associated action sets104and106, respectively. The game characters100and102represent computer-controlled adaptive agents in one-on-one, hand-to-hand combat in a video martial arts game. Human-controlled characters may also select actions from a predefined set of actions. Furthermore, alternative adaptive agents may include a variety of different game play entities, including individual and team sport competitors (e.g., soccer players, tennis players), racing vehicles, military forces, and other interactive entities within a game environment. InFIG. 1, each character is designated as a computer-controlled adaptive agent, and each character is capable of behaving according to a selection from a predefined set of available actions, although as shown, the predefined set of actions may differ between different characters. The illustrated actions sets104and106list offensive actions (e.g., kick and punch), neutral actions (e.g., wait), and defensive actions (e.g., block). Alternative action sets for different types of characters may include without limitation character movements; vehicle steering, braking, and acceleration changes; shots on goal; passes; tackles; baseball pitches; tennis serves and volleys, conversations, reaching target positions on virtual maps, etc. During game play, each character selects an action from its action list based at least on the current game state. However, some actions in the action list may not be available in a given game interval. For example, an agent may not be capable of punching an opponent if the agent is deemed tied up, handcuffed, or unconscious. Likewise, an agent may be unable to change from one action to another in the middle of the first action. For example, an agent that is in the air (e.g., in the process of leaping) may be unable to change immediately to a different action that requires the agent to fall to the ground (e.g., a low tripping move). Accordingly, whether a new action can be executed ...
DETAILED DESCRIPTION
FIG. 1illustrates two game characters100and102with associated action sets104and106, respectively. The game characters100and102represent computer-controlled adaptive agents in one-on-one, hand-to-hand combat in a video martial arts game. Human-controlled characters may also select actions from a predefined set of actions. Furthermore, alternative adaptive agents may include a variety of different game play entities, including individual and team sport competitors (e.g., soccer players, tennis players), racing vehicles, military forces, and other interactive entities within a game environment.
InFIG. 1, each character is designated as a computer-controlled adaptive agent, and each character is capable of behaving according to a selection from a predefined set of available actions, although as shown, the predefined set of actions may differ between different characters. The illustrated actions sets104and106list offensive actions (e.g., kick and punch), neutral actions (e.g., wait), and defensive actions (e.g., block). Alternative action sets for different types of characters may include without limitation character movements; vehicle steering, braking, and acceleration changes; shots on goal; passes; tackles; baseball pitches; tennis serves and volleys, conversations, reaching target positions on virtual maps, etc.
During game play, each character selects an action from its action list based at least on the current game state. However, some actions in the action list may not be available in a given game interval. For example, an agent may not be capable of punching an opponent if the agent is deemed tied up, handcuffed, or unconscious. Likewise, an agent may be unable to change from one action to another in the middle of the first action. For example, an agent that is in the air (e.g., in the process of leaping) may be unable to change immediately to a different action that requires the agent to fall to the ground (e.g., a low tripping move). Accordingly, whether a new action can be executed depends on both the current game state and the nature of the current action. The interval between the start of a first action and the start of a second action is termed an “action interval” and differs from a game interval, as described below.
FIG. 2illustrates a portion of a gaming system200supporting an adaptive agent202. The adaptive agent202may represent any computer-controlled agent in a video game, such as a combatant in a one-on-one, hand-to-hand combat game. Generally, adaptive agents have explicitly defined goals. Adaptive agents can sense aspects of their environments and can choose actions according to a policy to influence their environments. Moreover, it is usually assumed from the beginning that an adaptive agent operates despite significant uncertainty about the environment it faces.
The adaptive agent202seeks a goal, which is typically defined at development time, although the goal may be modified in some manner during runtime. For example, in a typical one-on-one, hand-to-hand combat game, a goal may be defined for the adaptive agent202as “inflicting a maximum amount of damage on an opponent while suffering a minimum amount of damage itself”.
A game engine204provides a model of the gaming environment. Generally, given a state stand an action atat a game interval t, the game engine predicts the next state st+1resulting from application of the action at(and possibly other actions206from other entities) in the gaming environment. A game interval may be defined at development time to represent a fundamental time period within the game environment. For example, a game interval may represent the time between video frames, a predefined period of time in a real-time simulation, or some other uniform interval.
A policy defines the adaptive agent's way of behaving at a given time within the gaming environment. Generally, a policy π is a mapping from perceived game states s ε S of the gaming environment to actions a ε A (s) to be taken in those game states. The symbol S represents the set of all possible game states that can be considered by the adaptive agent. The symbol A(s) represents the set of all possible actions that can be taken in the presence of the game state s. Metaphorically, a policy might approximate a set of stimulus-response rules or associations, in which states represent stimuli and actions represent responses
It is possible to represent an exemplary policy as a simple function or lookup table, whereas other policies may involve extensive computation, such as a search process. Policies may also be stochastic in nature. In an exemplary implementation, a policy π may be represented as the probability π(s,a) of taking an action a when the gaming environment is in a game state s.
In some implementations, a policy may be adapted according to a training session based on the same policy (i.e., “on-policy learning”). In other implementations, the agent's behavior is driven during the training session by one policy, but the adaptive updates during the training session are applied to a different policy (i.e., “off-policy learning”).
In light of the combat nature of the gaming scenario illustrated byFIG. 2, a policy208is shown. The policy208selects offensive (e.g., kick, throw, punch, etc.), neutral (e.g., stand still), and defensive (e.g., block, duck, retreat, etc.) actions for the adaptive agent202. The policy208of the adaptive agent202adapts according to the adaptive agent's experience in the gaming environment. A reward module212modifies the policy208according to the effectiveness of selected actions in seeking the defined goal from a given game state.
The reward module212typically defines the goal, which is typically specified at development time, or has access to the goal definition. Generally, the reward module212is synchronized with action intervals n, instead of game intervals t (see the description ofFIG. 6). The reward module212maps perceived states (or state-action pairs) of the gaming environment to a reward parameter rnthat indicates the intrinsic desirability of the application the action a, to the state sn, which leads to the state sn+1within the gaming environment. An adaptive agent strives to maximize the total reward received over the course of multiple actions in accordance with a predefined goal.
The reward module212is synchronized on action intervals and evaluates a state resulting from a given action performed in response to a previous state to assign a positive or negative reward to the previous state-action pair. In one implementation, the reward module212is defined at development time, although some runtime modifications to the reward module212are also contemplated. Reward parameters generated by a reward module212may be used as a basis for adapting the policy208. For example, if an action selected by the policy is followed by low reward relative to a given state, then the policy may be changed to select (or to be more likely to select) a different action in that state in the future. Reward functions may be deterministic or stochastic.
FIG. 3illustrates a table-based policy300(denoted as π) for an adaptive agent302. The adaptive agent302is fighting with an opponent304. For ease of description, the policy300designates a limited list of state features (in the first column) that it supports. However, it should be understood that a policy may support a rich variety of state features. In addition, policies may be implemented in non-tabular forms, including without limitation neural networks, stochastic models, and other algorithmic systems.
The policy300supports three actions for adaptive agent302: “throw”, “kick”, and “stand” (in the second through fourth columns). Again, it should be understood that a rich variety of actions may be supported by a given policy. The internal cells of the policy300hold action values (denoted by the symbol Q).
Exemplary Q values are given for the three actions in the state “3 ft/stand”, which corresponds to the states illustrated by the characters302and304in the current action interval n (the “stand” feature referring to the status of the opponent304). It should be understood that the actual game state may include a rich set of state features; however, in the illustrated example, the policy300considers only the two-element condition state of the agent302(i.e., STAND or KNOCKED, as in “knocked down”) and the physical separation (or distance) of the agent302from its opponent304. In one implementation, these features of interest are filtered from the general game state and presented to the policy300.
In the example ofFIG. 3, the state features set of “3 ft/stand” is detected by the policy300. The corresponding Q values associated with three possible actions are evaluated to select the action having the highest Q value for that state feature set. In the illustrated scenario, the evaluation results in selection of a “throw” action. It should also be noted that, prior to application of the action within the gaming environment, both characters possess 100 hit points. Furthermore, while some implementations may strictly seek the highest Q value, this approach may find only local maxima in certain circumstances. Therefore, other implementations may also search for locally non-optimal actions (e.g., by some deterministic or random manner) in order to find a globally optimal solution.
The defined goal of the adaptive agent302is to maximize damage to the opponent302. However, generally, defined goals may take many different forms. For example, goals may be set differently for different agents to provide additional variability of game play (e.g., a defensive agent may aim to minimize the amount of damage it suffers, while an offensive agent may aim to maximize the amount of damage it inflicts on its opponent). In addition, a goal may be compound in nature (e.g., such that an adaptive agent inflicts maximum damage on an opponent while suffering minimum damage itself).
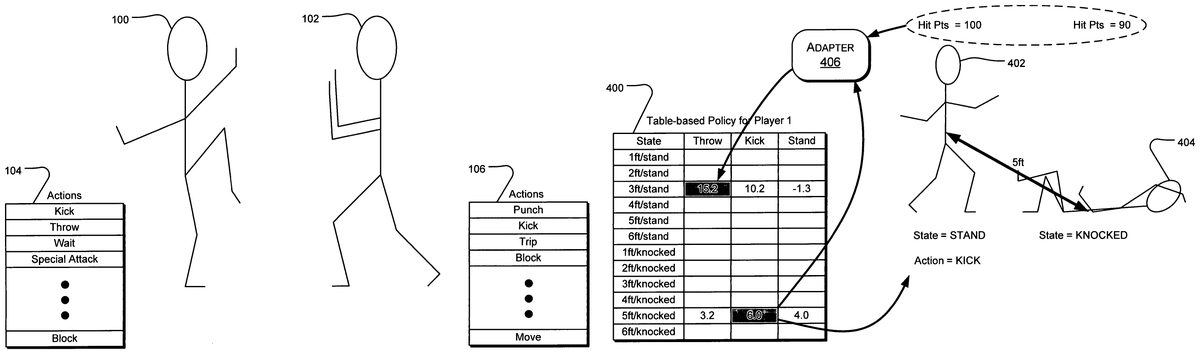
FIG. 4illustrates a table-based policy400(denoted as π) for an adaptive agent402, including selected actions in two action intervals n and n+1. The adaptive agent402is fighting with an opponent404, which has been knocked down as a result of the previously selected “throw” action of the adaptive agent402. As a result of the previous “throw” action, the opponent404has also suffered10hit points of damage, which results in a positive reward parameter rt. The positive reward parameter is input to the adapter406, which adjusts the action value of the previous action interval n from 13.2 to 15.2. This adjustment represents recognition that a “throw” action executed in a “3 ft/stand” state produces a “good” result toward the defined goal of inflicting damage on the opponent404.
In the example ofFIG. 4, the state feature set of “5 ft/knocked” is detected by the policy400in the subsequent action interval n+1. The corresponding Q values associated with three possible actions are evaluated to select the action having the highest Q value for that state feature set, resulting in selection of a “kick” action, which has the highest action value at 6.0.
To this point, parameters from two action intervals n and n+1 have been computed: sn=“3 ft/stand”, an=“throw”, sn+1=“5 ft/knocked”, an+1=“kick”, and rt=“+10”. In addition, the previous action value of Q−1π(sn,an) is known (i.e., 13.2). The new action value (e.g., 15.2) is computed from an action-value function Qπ(sn, an), which predicts an expected long-term reward when starting in state st, taking the action at, and following policy π thereafter.
In one implementation, an action-value function takes the form:
Qπ(sn,an)=Q-1π(sn,an)+α[rn+γmaxan+1Q-1π(sn+1,an+1)-Q-1π(sn,an)](1)
where Q−1π(sn,an) represents the magnitude of the action value prior to its adaptation, α represents a predefined weighting factor, rnrepresents the reward value computed for the current action interval, and γ represents a discount rate, which determines the present value of future rewards—a reward received k action intervals in the future is worth only γk−1times what it would be worth if it were received immediately. If γ<1, the infinite sum has a finite value as long as the reward sequence {rn} is bounded.
Action values Qπcontribute to defining what is “good”, relative to the defined goal, in the long run. Generally, the action value associated with a given game state, as defined by an action-value module, represents the total amount of reward that an adaptive agent can expect to accumulate over multiple cycles starting from that game state and applying the action associated with the action value. Whereas rewards determine the,immediate, intrinsic desirability of environmental states, action values indicate the long-term desirability of states after taking into account the states that are likely to follow and the rewards that are available in those states. For example, a game state might always yield a low immediate reward, but still have a high value because the state is regularly followed by other game states that yield high rewards. Or the reverse could be true. To make a human analogy, rewards are like pleasure (if high) and pain (if low), whereas values correspond to a more refined and far-sighted judgment of how pleased or displeased one should be that the gaming environment is in a particular state.
FIG. 5illustrates a policy500implemented by a neural network502. A game state is received and filtered by a state feature extractor504. The extracted state features are input to the neural network502that acts as a functional representation of the policy. The neural network502consists of an input layer506and subsequent layers508and510of computational units referred to as “neurons”, which calculate a weighted sum of their inputs from the previous layer, weighted by a number wkij(weight from ithneuron in the kthlayer to the jthneuron in the (k+1)thlayer) as represented by the incoming edges (examples w1,5,3and w2,3,5are shown). The neurons output an activation value by applying a squashing function to the weighted sum, e.g., according to exemplary function:
f2,2=tanh(∑iwi,2fi,1).
Activations of the previous layer are passed on to the next layer until an output layer is reached. The neural network502has an output layer510with as many outputs as there are available actions. An action selector512uses the output510of the neural network502to select an action, typically by choosing the action with the highest associated output. Other neural network implementations are also contemplated.
The policy represented by the neural network502may be updated to adapt to the agent's experience by changing the weights wkijof the neural network502. In one implementation, the update equation represents a gradient descent optimization on the squared discrepancy between the predicted Q value Q(sn,an) and the sum of the observed reward rnand the best possible Q-value γ maxaQ(sn+1,a) (compare to Equation (1)).
FIG. 6illustrates update triggering based on action intervals. A game timeline600includes a sequence of game intervals (represented by the intervals delineated by the hash marks along the timeline600). As previously described, game intervals represent fundamental intervals recognized by the game engine, such as real-time simulation intervals, video frame intervals, etc. However, an adaptive agent is rewarded (positively or negatively) based on the changes in game state detected between applied actions within the game environment. As such, a policy is generally not subject to reward-driven adaptation with each game interval—only with each action interval. Accordingly, policy updates are properly synchronized with action intervals, which delineate transitions between one action and the next.
In one implementation, an update trigger module602monitors a set of available actions (not shown) at each game interval. If no actions are available, the update trigger module602does not trigger a new action interval. However, if at least one action is available at the end of a game interval and that action is applied to the current game state within the game environment, the update trigger module602triggers a new action interval, thereby triggering an update to the policy604. Alternative methods of detecting the end of an action interval and triggering the start of a new action interval may be employed. For example, a game engine can announce the end of an action interval or the pending application of a new action to the update trigger module604.
As suggested by Equation (1), policy updates are synchronized on action intervals. At the end of each action interval, the reward parameter rnfor that action interval is computed by a reward module606(on the basis of the resulting game state sn+1and its compliance with the defined goal) and is passed to a value module608, which computes the new action value Qπ(sn,an) based on the input parameters of Equation (1). An adapter module610modifies the policy604with the new action value (e.g., replaces the old action value with the newly computed action value).
Adaptive agents can be used both in game development and game play. During development, adaptive agents can find unintended weaknesses and errors in existing computer-controlled agents by adaptively learning to exploit programming and configuration errors of such agents during pre-release testing. In addition, a game can be populated at development time with selections of adaptive agents having differently defined goals and/or action sets to provide a rich variety of adaptive computer-controlled agents (e.g., defensive opponents, aggressive opponents, cowardly teammates, etc.) during game play.
Importantly, at game time, adaptive agents provide exciting computer-controlled characters that dynamically adapt to the actions performed by other characters (both human-controlled and computer-controlled) within the gaming environment. As such, human players cannot merely optimize their strategies once and for all with or against a given computer-controlled adaptive agent because the adaptive agent will adapt to the changes in the human player's behavior as the adaptive agent seeks to make progress toward the agent's defined goal.
The exemplary hardware and operating environment ofFIG. 7for implementing the invention includes a general purpose computing device in the form of a computer20, including a processing unit21, a system memory22, and a system bus23that operatively couples various system components include the system memory to the processing unit21. There may be only one or there may be more than one processing unit21, such that the processor of computer20comprises a single central-processing unit (CPU), or a plurality of processing units, commonly referred to as a parallel processing environment. The computer20may be a conventional computer, a distributed computer, or any other type of computer. For example, implementations of the described system are well-suited for desktop computers, laptop computers, set top boxes, video game consoles, handheld video game devices, etc.
The system bus23may be any of several types of bus structures including a memory bus or memory controller, a peripheral bus, a switched fabric, point-to-point connections, and a local bus using any of a variety of bus architectures. The system memory may also be referred to as simply the memory, and includes read only memory (ROM)24and random access memory (RAM)25. A basic input/output system (BIOS)26, containing the basic routines that help to transfer information between elements within the computer20, such as during start-up, is stored in ROM24. The computer20further includes a hard disk drive27for reading from and writing to a hard disk, not shown, a magnetic disk drive28for reading from or writing to a removable magnetic disk29, and an optical disk drive30for reading from or writing to a removable optical disk31such as a CD ROM or other optical media.
The hard disk drive27, magnetic disk drive28, and optical disk drive30are connected to the system bus23by a hard disk drive interface32, a magnetic disk drive interface33, and an optical disk drive interface34, respectively. The drives and their associated computer-readable media provide nonvolatile storage of computer-readable instructions, data structures, program modules and other data for the computer20. It should be appreciated by those skilled in the art that any type of computer-readable media which can store data that is accessible by a computer, such as magnetic cassettes, flash memory cards, digital video disks, random access memories (RAMs), read only memories (ROMs), and the like, may be used in the exemplary operating environment.
A number of program modules may be stored on the hard disk, magnetic disk29, optical disk31, ROM24, or RAM25, including an operating system35, one or more application programs36, other program modules37, and program data38. A user may enter commands and information into the personal computer20through input devices such as a keyboard40and pointing device42. Other input devices (not shown) may include a microphone, joystick, game pad, satellite dish, scanner, or the like. These and other input devices are often connected to the processing unit21through a serial port interface46that is coupled to the system bus, but may be connected by other interfaces, such as a parallel port, game port, or a universal serial bus (USB). A monitor47or other type of display device is also connected to the system bus23via an interface, such as a video adapter48. In addition to the monitor, computers typically include other peripheral output devices (not shown), such as speakers and printers.
The computer20may operate in a networked environment using logical connections to one or more remote computers, such as remote computer49. These logical connections are achieved by a communication device coupled to or a part of the computer20; the invention is not limited to a particular type of communications device. The remote computer49may be another computer, a server, a router, a network PC, a client, a peer device or other common network node, and typically includes many or all of the elements described above relative to the computer20, although only a memory storage device50has been illustrated inFIG. 7. The logical connections depicted inFIG. 7include a local-area network (LAN)51and a wide-area network (WAN)52. Such networking environments are commonplace in office networks, enterprise-wide computer networks, intranets and the Internet, which are all types of networks.
When used in a LAN-networking environment, the computer20is connected to the local network51through a network interface or adapter53, which is one type of communications device. When used in a WAN-networking environment, the computer20typically includes a modem54, a network adapter, a type of communications device, or any other type of communications device for establishing communications over the wide area network52. The modem54, which may be internal or external, is connected to the system bus23via the serial port interface46. In a networked environment, program modules depicted relative to the personal computer20, or portions thereof, may be stored in the remote memory storage device. It is appreciated that the network connections shown are exemplary and other means of and communications devices for establishing a communications link between the computers may be used. It should also be understood that exemplary video game systems may be coupled across various communications networks, including LANs, WANs, and global communication networks, such as the Internet.
In an exemplary implementation, a value module, a reward module, an adapter module, a policy, an update trigger module, and other modules may be incorporated as part of the operating system35, application programs36, or other program modules37. A policy, agent actions, game states, reward parameters, action values, action intervals, game intervals and other data may be stored as program data38.
The embodiments of the invention described herein are implemented as logical steps in one or more computer systems. The logical operations of the present invention are implemented (1) as a sequence of processor-implemented steps executing in one or more computer systems and (2) as interconnected machine modules within one or more computer systems. The implementation is a matter of choice, dependent on the performance requirements of the computer system implementing the invention. Accordingly, the logical operations making up the embodiments of the invention described herein are referred to variously as operations, steps, objects, or modules.
The above specification, examples and data provide a complete description of the structure and use of exemplary embodiments of the invention. Since many embodiments of the invention can be made without departing from the spirit and scope of the invention, the invention resides in the claims hereinafter appended.
Claims
- A method comprising: causing one or more processing units to perform instructions to: detect a first game state at a first action interval of a gaming environment;select a first action of an adaptive agent for the first game state, wherein to select comprises: evaluating multiple action values corresponding to multiple possible actions of a policy for the active agent, wherein the policy maps the first game state to the possible actions and includes the multiple action values, and wherein individual action values represent a corresponding reward amount that the adaptive agent can expect to accumulate starting from the first game state by applying a corresponding individual possible action;and selecting a possible action corresponding to a highest action value of the multiple action values as the first action of the adaptive agent;apply the first action of the adaptive agent to the first game state in the first action interval to produce a second game state in a second action interval within the gaming environment;determine a reward associated with the first action interval based on compliance with a defined goal within the gaming environment;compute an action value for the first action interval based on the reward;and modify the policy to reflect the computed action value in correspondence with the first state and the first action.
- The method of claim 1 wherein to determine comprises: determining the reward associated with the first action interval based on compliance of the second game state with the defined goal.
- The method of claim 1 wherein to determine comprises: determining the reward associated with the first action interval based on the first game state.
- The method of claim 1 wherein to determine comprises: determining the reward associated with the first action interval based on the first action.
- The method of claim 1 , further comprising causing the one or more processing units to perform instructions to: select by the policy a second action of the adaptive agent for application to the second game state in the second action interval.
- The method of claim 5 wherein the computed action value is a function of the first and second game states and the first and second actions.
- The method of claim 1 , further comprising causing the one or more processing units to perform instructions to: detect a transition between the first action interval and the second action interval, both the first action interval and the second action interval having durations exceeding a single game interval;and trigger the modifying operation, responsive to detecting the transition.
- A method of adapting a policy of an adaptive agent toward a defined goal within a gaming environment executing on a computing device, wherein the policy maps game states to actions of a defined set of available actions, the method comprising: causing one or more processing units to perform instructions to: detect a first game state at a first action interval of the gaming environment;apply a first action of the adaptive agent selected by the policy to the first game state in the first action interval to produce a second game state in a second action interval within the gaming environment;determine a reward value associated with the first action interval based on compliance with the defined goal;compute an action value for the first action interval, wherein to compute comprises: computing an expected reward value based at least in part on the reward value, a predefined weighting factor, and a previous action value;and computing a sum of the expected reward value and the previous action value as the action value;and modify the policy to reflect the computed action value in correspondence with the first game state and the first action.
- The method of claim 8 wherein to determine the reward value is further based on compliance of the second game state with the defined goal.
- The method of claim 8 wherein to determine the reward is further based on the first game state.
- The method of claim 8 wherein to determine the reward is further based on the first action.
- The method of claim 8 further comprising causing the one or more processing units to perform instructions to: select by the policy a second action of the adaptive agent for application to the second game state in the second action interval.
- The method of claim 8 further comprising causing the one or more processing units to perform instructions to: detect a transition between the first action interval and the second action interval, both the first action interval and the second action interval having durations exceeding a single game interval;and trigger the modifying responsive to detecting the transition.
- A system comprising: a game engine configured to apply a first action of the adaptive agent selected by a policy to a first game state in a first action interval of a gaming environment to produce a second game state in a second action interval within the gaming environment, wherein the policy maps game states to individual available actions;a value module configured to compute an action value for the first action interval based at least in part on a reward value and a previous action value, the reward value reflecting a level of compliance with a defined goal within a gaming environment;an adapter configured to modify the policy to reflect the computed action value in correspondence with the first game state and the first action.
- The system of claim 14 wherein the adapter is further configured to determine individual reward values associated with the first action interval based on compliance of the second game state with the defined goal and to modify the policy based on the individual reward values.
- The system of claim 14 wherein the adapter is further configured to determine individual reward values based on individual game states and to modify the policy based on the individual reward values.
- The system of claim 14 wherein the adapter is further configured to determine individual reward values based on individual actions and to modify the policy based on the individual reward values.
- A method comprising causing one or more processing units to perform instructions to: select a first action of an adaptive agent from a plurality of available actions for application to a first state of a gaming environment during a first action interval;apply the first action within the gaming environment to produce a second state of the gaming environment;select a second action of the adaptive agent from the plurality of available actions for application to the second state of the gaming environment during a second action interval;detect a transition between the first action interval and the second action interval, both the first action interval and the second action interval having durations exceeding a single game interval;and modify a policy for the adaptive agent based on compliance with a defined goal, wherein the modifying is triggered in response to detecting the transition, wherein to modify comprises: computing a reward for the first action interval characterizing compliance of the second state with the defined goal;and computing an action value from an action-value function based on the reward, wherein the function predicts a long-term reward for the adaptive agent starting at the first state, taking the first action, and following the policy thereafter.
- The method of claim 18 wherein to modify further comprises: determining the reward based on the first game state, wherein the policy is modified based on the reward.
- The method of claim 18 wherein to modify further comprises: determining the reward based on the first action, wherein the policy is modified based on the reward.
Disclaimer: Data collected from the USPTO and may be malformed, incomplete, and/or otherwise inaccurate.