U.S. Pat. No. 12,322,177
AUTOMATIC CONTENT RECOGNITION AND INFORMATION IN LIVE STREAMING SUITABLE FOR VIDEO GAMES
AssigneeNVIDIA Corporation
Issue DateSeptember 28, 2023
Illustrative Figure
Abstract
In various examples, one or more Machine Learning Models (MLMs) are used to identify content items in a video stream and present information associated with the content items to viewers of the video stream. Video streamed to a user(s) may be applied to an MLM(s) trained to detect an object(s) therein. The MLM may directly detect particular content items or detect object types, where a detection may be narrowed to a particular content item using a twin neural network, and/or an algorithm. Metadata of an identified content item may be used to display a graphical element selectable to acquire the content item in the game or otherwise. In some examples, object detection coordinates from an object detector used to identify the content item may be used to determine properties of an interactive element overlaid on the video and presented on or in association with a frame of the video.
Description
DETAILED DESCRIPTION Systems and methods are disclosed related to automatic content recognition and information in live streaming suitable for video games. The disclosure provide approaches for using trained machine learning models to recognize objects in gameplay video streams and determining content for which information can be presented to assist a viewer of the stream in acquiring the content. In contrast to conventional systems, disclosed approaches may use a Machine Learning Model(s) to identify particular content items in video streams (e.g., game streams) and present information associated with the content items to assist viewers of the video streams in acquiring the content items. Using disclosed approaches, information regarding content items and/or services to acquire the content items or links thereto may be dynamically presented based on the content of a live video stream. In various examples, video (e.g., a live stream) of a game may be streamed to any number of user devices (e.g., smartphones, game consoles, personal computers, etc.). The gameplay video may be presented in user interfaces of the user device(s) for viewing. For example, one or more of the user interfaces may be provided, at least in part, by a service and/or video platform that hosts video streams (e.g., YouTube, Netflix, Twitch, etc.). The video may comprise a live stream that is broadcast in real-time or near real-time, or may be previously recorded or re-broadcasted. A device(s), such as a server, a network device, or user device may apply the video to an MLM(s) trained to detect one or more objects (e.g., player characters, vehicles, game items, player skins, environmental elements, etc.) within a gameplay video. The MLM may be trained to detect objects that may appear within a single game or application (e.g., using training data from the game or application), or may be trained to detect ...
DETAILED DESCRIPTION
Systems and methods are disclosed related to automatic content recognition and information in live streaming suitable for video games. The disclosure provide approaches for using trained machine learning models to recognize objects in gameplay video streams and determining content for which information can be presented to assist a viewer of the stream in acquiring the content.
In contrast to conventional systems, disclosed approaches may use a Machine Learning Model(s) to identify particular content items in video streams (e.g., game streams) and present information associated with the content items to assist viewers of the video streams in acquiring the content items. Using disclosed approaches, information regarding content items and/or services to acquire the content items or links thereto may be dynamically presented based on the content of a live video stream.
In various examples, video (e.g., a live stream) of a game may be streamed to any number of user devices (e.g., smartphones, game consoles, personal computers, etc.). The gameplay video may be presented in user interfaces of the user device(s) for viewing. For example, one or more of the user interfaces may be provided, at least in part, by a service and/or video platform that hosts video streams (e.g., YouTube, Netflix, Twitch, etc.). The video may comprise a live stream that is broadcast in real-time or near real-time, or may be previously recorded or re-broadcasted. A device(s), such as a server, a network device, or user device may apply the video to an MLM(s) trained to detect one or more objects (e.g., player characters, vehicles, game items, player skins, environmental elements, etc.) within a gameplay video. The MLM may be trained to detect objects that may appear within a single game or application (e.g., using training data from the game or application), or may be trained to detect objects that appear in multiple games or contexts (e.g., using a more general training dataset). For example, the MLM(s) may have been trained to detect objects in multiple games, collections or series of games, and/or in one or more versions or expansions of a game.
Based on an MLM(s) detecting one or more objects within a gameplay video, one or more content items within the video may be determined. The content items may be any of a number of virtual or real-life items that may appear within a gameplay video (e.g., player skins, items, weapons, gear, vehicles, etc.) and which may be acquired in-game or otherwise.
In some embodiments, the MLM(s) may be trained using annotated images of content items that the MLM is to detect. For example, an MLM may be trained using gameplay video of a game that includes the content items. In some examples, output classes of an object detector may correspond to one or more particular content items. In further examples, a first MLM may be used to detect or identify one or more objects in a region(s) of a video, for example, using an object detector. A second MLM and/or algorithm may then be used to identify a particular content item(s) from the detected objects.
In one or more embodiments, an MLM (e.g., the second MLM) used to identify content items may comprise a twin neural network. The twin neural network may be trained to encode representations of particular content items using positive and/or negative examples of the content items. In order to identify a content item, image data corresponding to a detected object (e.g., the region of the video) may be applied to the twin neural network to generate an encoding of the detected object. The encoding of the detected object may be compared to encodings produced by the twin neural network for one or more other content items to determine which content item (if any) is represented in the image data. For example, the comparison may be used to determine the similarity between the encodings and select a content item based on the similarity. In one or more embodiments, the content item may be selected based on the similarity exceeding a threshold value and/or based on being highest amongst the potential content items. It is noted that any number of frames may be used to identify one or more content items. Further, disclosed approaches may be suitable for identifying different instances of a content item in video despite variable viewing angles (front, back, etc.), sizes, lighting, and/or occlusions (e.g., images may be selected for the training dataset to include these variations).
In further respects, once a content item has been determined to be present in the video, metadata of the content item may be used to display information associated with the content item, such as one or more graphical elements selectable to acquire the content item in the game or otherwise. As various examples, the metadata may comprise various information that may be used to determine and/or present the information. Examples include a content identifier of the content item, a name of the content item, one or more frame identifiers associated with the content item (e.g., in which the content item was identified and/or in which to present the information), a link (e.g., a URL or URI) to a webpage or service that includes the information or enables a user to add the content item to a user account (e.g., of the game or service), and/or one or more portions of the information (e.g., textual and/or image based content). For example, the metadata may be used to present the link (e.g., via the graphical element(s)) or other information in the user interface of one or more viewers of the video, or may provide the information via e-mail, text, or some other means.
Where a link to a service is provided, the service may be hosted on a different server and/or system than the device(s) used to analyze the video for content items or many be hosted on the same server and/or system. Selection of an option corresponding to a link may directly or indirectly (e.g., via a further option or prompt) redirect a user device to the service. In at least one embodiment, selecting the option causes presentation of a second user interface (e.g., in a browser on the user device) that presents (e.g., from the service) information associated with the content item and one or more graphical elements selectable to acquire the content item in the game.
In some examples, the metadata for one or more content items may be provided (e.g., by a server) to the user devices. For example, one or more portions of the metadata for one or more content items may be transmitted to a user device in response to or based on identifying the content item(s) in one or more frames of the video. Transmitting the metadata may cause the user device to present the information and/or indicate that the content item(s) were identified. As further examples, one or more portions of the metadata for one or more content items may be transmitted to a user device prior to identifying the content item(s) in one or more frames of the video. For example, the metadata may be provided to the user device prior to or during viewing the video (e.g., based on determining the game or other media being viewed and possible content that may appear therein). In various examples, a server or other device may detect and/or identify the content item(s) in the video and/or the user device (e.g., user interface) may detect and/or identify the content item in the video (using the MLM(s)) and provide corresponding metadata to the user device. In embodiments where identification occurs at the user device, the metadata may be provided from the server and used to determine (e.g., request or access) or present the information for each identified content item.
Information associated with a content item(s) may be presented during and/or after the video used to identify the content item(s). In one or more embodiments, in response to or based on identifying a content item, the information (e.g., the graphical element(s)) may be displayed to the viewer (e.g., in the user interface). For example, object and/or region detection coordinates from the object detector that was used to identify the content item may be used to determine a size, shape, and/or location of an interactive (e.g., graphical) element (e.g., a polygon). The interactive element (an option) may be overlaid on the video and may be presented on or in association with a frame of the video used to detect the object (e.g., as the video continues to play or while the video is paused). Additionally or alternatively, the interactive element(s) may be presented for one or more other frames, such as using object tracking and one or more object detection regions. In one or more embodiments, information regarding a content item(s) may additionally or alternatively be presented outside of a video display region (e.g., in the user interface or a different user interface).
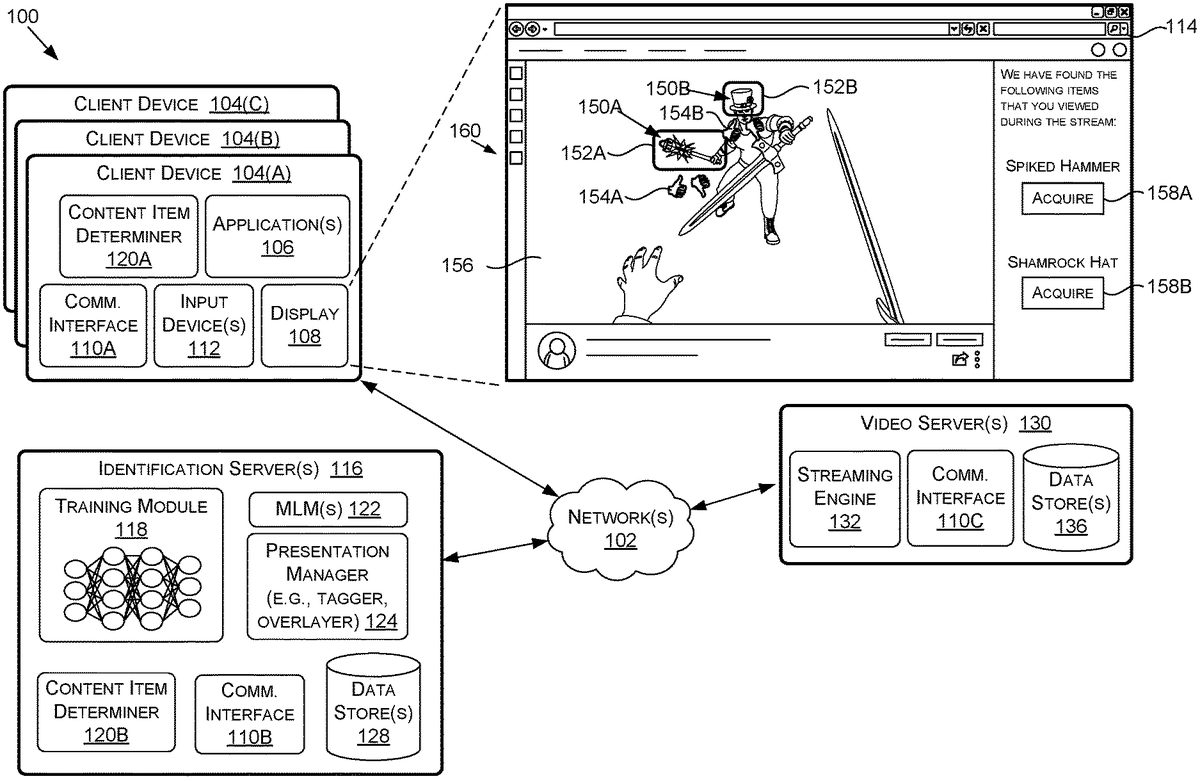
With reference toFIG.1,FIG.1is an example system diagram of a content item identification and presentation system100(also referred to as “system100”), in accordance with some embodiments of the present disclosure. It should be understood that this and other arrangements described herein are set forth only as examples. Other arrangements and elements (e.g., machines, interfaces, functions, orders, groupings of functions, etc.) may be used in addition to or instead of those shown, and some elements may be omitted altogether. Further, many of the elements described herein are functional entities that may be implemented as discrete or distributed components or in conjunction with other components, and in any suitable combination and location. Various functions described herein as being performed by entities may be carried out by hardware, firmware, and/or software. For instance, various functions may be carried out by a processor executing instructions stored in memory.
The system100may include, among other things, one or more client devices104(A),104(B), and104(C) (referred to collectively herein as “client devices104”), identification server(s)116, and/or a video server(s)130. Although the client devices104(A),104(B), and104(C) are illustrated inFIG.1, this is not intended to be limiting. In examples, there may be any number of client devices104. The system100(and the components and/or features thereof) may be implemented using one or more computing devices, such as the computing device700ofFIG.7, described in more detail below.
The client devices104may include a content item determiner120A, an application106, a communication interface110A, an input device(s)112, and/or a display108. Although only a few components and/or features of the client device104are illustrated inFIG.1, this is not intended to be limiting. For example, the client devices104may comprise additional or alternative components, such as those described below with respect to the computing device700ofFIG.7.
The identification server(s)116may include, among other things, a training module118, MLM(s)122, a content item determiner120B, a presentation manager124, a communication interface110B, and/or data store(s)128. Although only a few components and/or features of the identification server(s)116are illustrated inFIG.1, this is not intended to be limiting. For example, the identification server(s)116may comprise additional or alternative components, such as those described below with respect to the computing device700ofFIG.7.
The video server(s)130may include, among other things, a streaming engine132, a communication interface110C, and/or one or more data store(s)136. Although only a few components and/or features of the video server(s)130are illustrated inFIG.1, this is not intended to be limiting. For example, the video server(s)130may comprise additional or alternative components, such as those described below with respect to the computing device700ofFIG.7.
As an overview, one or more content item determiners, such as a content item determiner120A and/or120B (referred to herein as “content item determiner(s)120”) may include one or more components and features for determining one or more content items, such as content items150, in video and may be located, at least partially on any combination of a client device104and/or the identification server(s)116. An application106may include one or more components and features for displaying gameplay video or other video content in one or more user interface(s)160on the display108of a client device104. The gameplay video or other video content may be received from the video server(s)130and/or the identification server(s)116over the network(s)102using the communication interface110A for presentation in the user interface160.
The training module118may include one or more components and features for training the MLM(s)122to detect objects and/or identify content items in video. Once trained, a content item determiner120may apply video data to the MLM(s)122to detect objects and identify content items in the video data. The presentation manager124may generate and/or determine content to display on a client device(s)104such as annotations and overlays which may be communicated to an application106of a client device(s)104over the network(s)102. It at least one embodiment, the display of content in, for example, the user interface160, may be effectuated based at least on metadata (e.g., associated with particular video frames and/or times tamps) provided and/or generated by the presentation manager124.
The streaming engine132may include one or more components and features for generating, distributing, and managing streaming data such as video streams, audio streams, and/or other types of data streams that may be used by a streaming platform and presented in a user interface, such as the user interface160. Streaming data may be located on one or more data store(s)136, retrieved by the streaming engine132, and communicated over one or more network(s)102using a communication interface110C to transmit streaming data to the identification server(s)116and/or client device(s)104. As further examples, the streaming engine may receive the streaming data from one or more external devices, such as a client device104, and relay the stream to one or more other external devices, such as one or more other client devices104or the identification server116.
Components of the system100may communicate over a network(s)102. The network(s)102may include a wide area network (WAN) (e.g., the Internet, a public switched telephone network (PSTN), etc.), a local area network (LAN) (e.g., Wi-Fi, ZigBee, Z-Wave, Bluetooth, Bluetooth Low Energy (BLE), Ethernet, etc.), a low-power wide-area network (LPWAN) (e.g., LoRaWAN, Sigfox, etc.), a global navigation satellite system (GNSS) network (e.g., the Global Positioning System (GPS)), and/or another network type. In any example, each of the components of the system100may communicate with one or more of the other components via one or more of the network(s)102.
The client devices104may include a smart phone, a laptop computer, a tablet computer, a desktop computer, a wearable device, a game console, a virtual reality system (e.g., a headset, a computer, a game console, remote(s), controller(s), and/or other components), an NVIDIA SHIELD, a smart-home device that may include an intelligent personal assistant (e.g., an AMAZON ECHO, a GOOGLE HOME, etc.), and/or another type of device capable of supporting streaming of video.
An application106may be a mobile application, a computer application, a console application, a web browser application, a video streaming platform application, and/or another type of application or service. In some embodiments, multiple applications106may be employed. For example, the user interface ofFIG.1may be displayed in one application and the GUI200ofFIG.2may be displayed in another application106. An application106may include instructions that, when executed by a processor(s), cause the processor(s) to, without limitation, receive input data representative of user inputs to the one or more input device(s)112, transmit the input data to the video server(s)130and/or the identification server(s)116, in response receive a video stream from the video server(s)130and/or the identification server(s)116using the communication interface110A, and cause display of the video on the display108. In other words, the application106may operate as a facilitator for enabling streaming of video156of gameplay or other content associated with the application on the client devices104. In some examples, the application106may receive metadata (e.g., content item data) from the identification server(s)116using the communication interface110A and may cause display of content item information152derived using and/or directed by the metadata on the display108. In some examples, the metadata includes an indication of one or more frames of the video156and content item information152, and/or graphical feedback element(s)154associated with the one or more frames of the video156. The application106may determine how, when, and/or where to display content according to the metadata.
In some examples, the client devices104may use the application106to display the gameplay video or other video content on the display108. In some examples, a first client device, such as the client device104(A), may display the video while a second client device, such as client device104(B), may present information associated with the content item(s) identified in the video. In examples where the display data is received by the client device104, the system100may be part of a game streaming system, such as the game streaming system8ofFIG.8, described in more detail below.
The client device104(A) may display, via the display108, a video stream114. The video stream114may include any number of gameplay video streams presented to the user of the client device104(A). Similarly, users of each of the client devices104, in addition to the client device104(A), may view streams of any number of video streams114. As described herein, a video stream114may be a live or real-time broadcast stream. In some examples, the video stream114may be a previously recorded or re-broadcast of a video.
The video stream114may be presented in relation to one or more interfaces such as the user interface160. The user interface(s)160may also include elements that allow a user to control the playback or presentation of the video156. For example, the user interface(s)160may allow a user selectively pause or resume a live stream. In some embodiments, the user interface(s)160may contain information and interactive elements in addition to the video156. For example, the user interface(s)160may contain the video156and content that leverages user account information. In some examples, the user interface(s)160may contain the video156and interactive elements such as a chat or messaging interface.
The video stream114may include the video156of gameplay of a game (e.g., gameplay that is being broadcasted) or other content. The video156may additionally include objects (e.g., of a game, such as player characters, vehicles, game items, player skins, environmental elements, etc.). Objects in the video156include one or more content items, such as a content item150A and a content item150B (referred to herein as “content item(s)150”). Although the content item(s)150are illustrated inFIG.1, this is not intended to be limiting. In any example, there may be any number of content items150. The content items150may correspond to any of a number of virtual or real-life items that may appear within the video156(e.g., player skins, items, equipment, weapons, gear, vehicles, etc.) and which may be acquired in-game or otherwise.
In some examples, the video stream114may include content information, such as content item information152A and152B (referred to herein as “content item information152”), such as graphical elements that provide information about one or more of the content items150. The content item information152may be visually represented, for example, as a bounding region(s) of the object(s). Although, bounding region(s) are illustrated inFIG.1, this is not intended to be limiting. In some examples, there may be any of a number of content item information152related to the content items150, which may take any of a variety of different forms. Examples include overlays, annotations, arrows, color changes, highlighted appearance, text, and/or any other indication or information related to the content items150.
In at least one embodiment, the content item information152may rely on object tracking to track one or more object on the display108over a number of frames based on movement of an associated content item(s)150. In some examples, the content item information152about the content items150, may be presented in same user interface160that presents the video156. The content item information152about the content items150, may be presented in, over, or with a same frame(s) as the video156in which the content item(s)150was identified. In other examples, the content item information152may be presented in one or more other user interfaces on the display108or a different display, or may be presented after a frame in which the content item(s)150was identified (e.g., at the end of the video156). In some examples, the content item information152may be presented on a different client device104than displays the video stream114.
In further examples, the video stream114may include one or more graphical feedback elements, such as a graphical feedback elements154A and/or154B (referred to herein as “graphical feedback element(s)154”) that allow a user to interact with or provide input or feedback regarding the content items150. A graphical feedback element154may be represented in the user interface(s)160as an option or other selectable interface element with which a user may interact using an input device(s)112of the client device(s)104(e.g., a thumbs up/down button, like/dislike selection, option to save, etc.). In some examples, the graphical feedback element(s)154may be presented at a location that corresponds to a region of the video156in which content item(s)150have been identified. User input and/or interaction with the graphical feedback element(s)154, may cause the content item information152about the content items150to be presented in one or more user interface(s)160.
User input provided to the graphical feedback element(s)154may, for example, be used to determine for which of the content items150the related content item information152is presented. For example, if a user selects a “thumbs up” option as part of the graphical feedback element154A in the video stream114, content item information152A may be provided in the user interface(s)160about the content items150A, while if a “thumbs down” option is selected, the content item information152A may not be presented, alternative information may be presented in its place, or the content item information152A may be removed from the user interface160. As further examples, the graphical feedback elements may similarly impact the presentation of acquisition link158A or158B, described in further detail herein. In some embodiments, feedback received from the graphical feedback element(s)154may be provided to the presentation manager124to refine graphical feedback element(s)154and/or content item information152that are generated and presented in subsequent video streams.
The video stream114may include additional graphical elements that provide one or more acquisition links, such as acquisition links158A and158B (referred to herein as “acquisition link(s)158”), that are selectable by a user to acquire one or more corresponding ones of the content items150. In at least one embodiment, acquisition link(s)158may be selectable by a user to access one or more user interface(s)160. For example a user can select the acquisition link158B in the user interface160to acquire the “Shamrock Hat” identified as the content item150B in the video stream114and may be presented with the GUI200ofFIG.2in the user interface160or a different user interface. The acquisition link(s)158may be represented, for example, as a selectable button, link, or any other selectable element. Although, the acquisition link(s)158are illustrated as buttons inFIG.1, this is not intended to be limiting. In some examples, there may be any of a number of acquisition links158related to one or more of the content items150. In some examples, a user selecting an acquisition link158may immediately acquire a content item(s)150. This may include adding the item to the user's in-game account. In other examples, a user selecting an acquisition link158may provide information on how to acquire the content item(s)150(e.g., providing a link or redirect to the item page at store, adding the item to a user's cart, or providing information on steps to acquire the item, availability of the item, or a location of the content item(s)150, etc.). In further examples, the content item acquisition link(s)158may be presented on a content device(s)104and/or user interface(s)160different from one displaying the video stream114(e.g., in an e-mail, text message, notification, pop-up, etc.). In at least one embodiment, one or more of the content item information152A or152B may comprise an acquisition link, similar to the acquisition links158A or158B. In such examples, a content item information152may be presented using an interactive element.
The display108may include any type of display capable of displaying the video (e.g., a light-emitting diode display (LED), an organic LED display (OLED), a liquid crystal display (LCD), an active matrix OLED display (AMOLED), a quantum dot display (QDD), a plasma display, an LED/LCD display, and/or another type of display). In some examples, the display108may include more than one display (e.g., a dual-monitor display for computer gaming, a first display for configuring a game and a virtual reality display for playing the game, etc.). In some examples, the display is a touch-screen display, such as a touch-screen of a smart phone, tablet computer, laptop computer, or the like, where the touch-screen is at least one of the input device(s)112of the client device104.
The input device(s)112may include any type of devices that are capable of providing user inputs to the game. The input device(s) may include a keyboard, a mouse, a touch-screen display, a controller(s), a remote(s), a headset (e.g., sensors of a virtual reality headset), and/or other types of input devices.
The communication interfaces such as communication interface110A, communication interface110B, and communication interface110C (referred to collectively or individually herein as “communication interface(s)110”) may include one or more components and features for communicating across one or more networks, such as the network(s)102. The communication interface(s)110may be configured to communicate via any number of network(s)102, described herein. For example, to communicate in the system100ofFIG.1, the client devices104may use an Ethernet or Wi-Fi connection through a router to access the Internet in order to communicate with the identification server(s)116, the video server(s)130, and/or with other client devices104.
The identification server(s)116may include one or more servers for generating, training, managing, storing, and/or using components for detecting and identifying content items in video, such as the video156. Although only a few components and/or features of the identification server(s)116are illustrated inFIG.1, this is not intended to be limiting. For example, the identification server(s)116may include additional or alternative components, such as those described below with respect to the computing device700ofFIG.7.
As further illustrated inFIG.1, the identification server(s)116may be separate or distinct from the video server(s)130and/or a client device104; however, this is not intended to be limiting. For example, the identification server(s)116may be the same or similar servers to the video server(s)130and/or one or more components thereof may be at least partially on a client device(s)104. In some examples, the identification server(s)116may be operated or hosted by a first entity (e.g., a first company) and the video server(s)130may be operated or hosted by a second entity (e.g., a second, different company). In such examples, the second entity may be a video streaming service, and the first entity may develop training datasets from data (e.g., video data) received from the second entity. In other examples, the identification server(s)116and the video server(s)130may be operated or hosted, at least partially, by the same entity.
The identification server(s)116may comprise the communication interface110B that may include one or more components and features for communicating across one or more networks, such as the network(s)102. The communication interface110B may be configured to communicate via any number of network(s)102, described herein. For example, to communicate in the system100ofFIG.1, the identification server(s)116may use an Ethernet or Wi-Fi connection through a router to access the Internet in order to communicate with the client device(s)104, the video server(s)130, and/or with other identification server(s)116.
The identification server(s)116may include one or more application programming interfaces (APIs) to enable communication of information (e.g., video data, game information, user account information, etc.) with the video server(s)130. For example, the identification server(s)116may include one or more game APIs that interface with a streaming engine132of the video server(s)130to receive video data for training an MLM(s)122using a training module118, and/or detecting content item(s) in video using the content item determiner120B. As a further example, the identification server(s)116may include one or more APIs that interface with the application106(and/or the content item determiner120A) of a client device104for transmitting information relating to a content item (e.g., in response to detecting a content item in gameplay video) to enable the application106of a client device104to provide the information associated with the content item in a display108. Although different APIs are described herein, the APIs may be part of a single API, two or more of the APIs may be combined, different APIs may be included other than those described as examples herein, or a combination thereof.
The identification server(s)116may include a training module118for learning objects that may be detected within gameplay video. AlthoughFIG.1includes an illustration of a neural network, this is not intended to be limiting. For example, the training module118may be used to train machine learning model(s)122of any type, such as machine learning models using linear regression, logistic regression, decision trees, support vector machine (SVM), Naïve Bayes, k-nearest neighbor (Knn), K means clustering, random forest, dimensionality reduction algorithms, gradient boosting algorithms, neural networks (e.g., auto-encoders, convolutional, recurrent, perceptions, long/short terms memory, Hopfield, Boltzmann, deep belief, deconvolutional, generative adversarial, liquid state machine, etc.), twin neural networks, and/or other types of machine learning models.
Video data may be applied to the MLM(s)122by the training module118, where the MLM(s)122learns to detect one or more objects in a video and/or content items presented in video data. In some examples, the video data may be applied to one or more MLM(s)122(e.g., neural networks) to be trained using reinforcement learning or inverse reinforcement learning. For example, to learn to detect or identify objects in video, inverse reinforcement learning may be used to observe objects and content items through many video streams and learn to detect objects from any number of angles, scales, and/or occlusions (e.g., blocked visibility, low resolution, etc.). The video data may be stored in a data store(s)128. In addition, the data used by, and generated by the training module118to train the MLM(s)122may be stored in the data store(s)128.
The video data may include gameplay video data, game data, user account data, image data, audio data, and/or other data representing or capturing one or more portions of a game or other content. For example, the video data may include video frames of gameplay and the audio data associated of that gameplay. In some examples the video data may include information such as user account information (e.g., an account of a user that is viewing streaming video) and/or game information (e.g., information indicating name of game, version of game, etc.). The video data may capture the environment, the objects, the values, and/or other information of a video stream114. The video data may be stored with associated annotated or tagged images of content items that the MLM(s)122is trained to detect.
The MLM(s)122may be trained by the training module118, to detect one or more objects in a video and/or content items presented in video data. The MLM(s)122may be trained to detect objects in certain contexts (e.g., trained to detect objects within a single game title) or may be trained to detect objects over any of a number of video contexts (e.g., multiple game titles, versions, expansions, DLC, genres, game systems, etc.). For example, the MLM(s)122may be trained by the training module118and used by the content item determiner120B to detect objects in gameplay video of multiple games or a specific genre or type of gameplay (e.g., first person shooter, strategy, sports, puzzle, etc.). Training an MLM122to detect objects for a context may include using image data from the context as training data.
The MLM(s)122may be trained to determine that an object detected in a gameplay video is a particular content item(s)150. The content items150may be any of a number of virtual or real-life items that may appear within a gameplay video (e.g., player skins, items, sport equipment, clothes, weapons, gear, vehicles, etc.). The MLM(s)122may be trained with annotated or labeled training images of content items150or with gameplay video of a game that includes the content items150or similar objects. In some examples, the MLM(s)122may be trained by the training module118to identify different instances of a content item150that may have variable visual properties (e.g., variable viewing angles, sizes, lighting, occlusions, etc.). This may include selecting and providing training images to the MLM(s)122that depict variations to those variables.
The MLM(s)122may be of any suitable type, such as machine learning models using linear regression, logistic regression, decision trees, support vector machine (SVM), Naïve Bayes, k-nearest neighbor (Knn), K means clustering, random forest, dimensionality reduction algorithms, gradient boosting algorithms, neural networks (e.g., auto-encoders, convolutional, recurrent, perceptions, long/short terms memory, Hopfield, Boltzmann, deep belief, deconvolutional, generative adversarial, liquid state machine, etc.), twin neural networks, and/or other types of machine learning models.
In at least one embodiment, the MLM(s)122may comprise a twin neural network that may be trained to encode representations of a content item(s)150using positive and/or negative examples of the content item(s)150. Once deployed, one or more content item determiner(s)120, such as a content item determiner120A and/or120B may use the MLM(s)122to determine one or more content items150in video. As shown, a content item determiner120may be located, at least partially on any combination of a client device104and/or the identification server(s)116, which may vary for different embodiments. For example, some embodiments may include a content item determiner120A and not a content item determiner120B, and vice versa.
A content item determiner(s)120may use the one or more MLMs122to encode an object detected in video data (e.g., detected by an MLM122). The encoding of the object can be used by the content item determiner120to identify a content item(s)150. For example, the encoding of the detected object may be compared to other encodings produced by the twin neural network of the MLM(s)122to determine if a content item(s)150is represented in the video data. In some examples, the content item determiner(s)120may compare the encodings to determine a similarity or matching between the encodings in order select one or more content item(s)150. For example, the content item determiner(s)120may select a content item(s)150based on the similarity between encodings meeting or exceeding a threshold value and/or based on any of a number of methods to score or rank confidences in matchings.
A content item determiner120may use the communication interface100A and/or110B to access the video data being analyzed over the network(s)102and/or from local or remote storage, such as the data store(s)128. A content item determiner120may operate as a facilitator for retrieving and applying video data to an appropriate MLM(s)122, post-processing output of the MLM(s)122, and communicating metadata generated or determined at least on the post-processing (e.g., communicating the metadata to the presentation manager124and/or application106). In some examples, the content item determiner120may apply video data to an MLM(s)122and determine or identify a particular content item(s)150in the video data based on output therefrom. The presentation manager124may then generate overlays and/or information related to the determined content item(s)150for presentation to one or more users and/or viewers associated with a corresponding video stream114.
The presentation manager124may generate and/or determine content to display on a client device(s)104. For example, the presentation manager124may generate and/or determine annotations and overlays which may be communicated to an application106of a client device(s)104. The presentation manager124may, for example, be located on one or more of the identification server(s)116. In some examples, a presentation manager(s)124may be included in an application106or otherwise be hosted on a client device(s)104. While the presentation manager124is shown on the identification server(s)116, in one or more embodiments, the presentation manager124may be located, at least partially, on one or more client devices104and/or the video server(s)130. Other locations of components are may be similarly varied, such as the content item determiner120, the data store(s)128, the MLM(s)122, and/or the training module118, etc. Additionally, in some embodiments, the identification server(s)116may include one or more of the video server(s)130.
Now referring toFIG.2,FIG.2is an example screenshot from a graphical user interface (GUI)200for acquiring a content item, in accordance with some embodiments of the present disclosure. The GUI200as shown inFIG.2may be part of a larger GUI. For example the GUI200as shown may be a GUI region or window presented within an enclosing GUI. In some embodiments, the GUI200may be part of or presented with the application106of the client device(s)104. As further examples, the GUI200may be part of or presented with applications other than the application106. Further, the GUI200may be presented on a client device(s)104that is different from a client device(s)104displaying the video stream114(e.g., in the application106).
The GUI200may present a user with content item information204that may be associated with a content item. For example, the GUI200may prompt a user with the content item information204, such as an option to acquire the content item “Shamrock Hat.” The content item information204may include any information associated with the content item. For example, the content item information204may include a name, attributes, rarity, availability, features, abilities, description, or any other information related to the content item or similar items.
In at least one embodiment, the GUI200may be presented at the same time as the video stream114. In some examples, the GUI200may be presented after the video stream114has completed. For example, the GUI200may be presented on the display108of a client device(s)104at the conclusion of a video stream broadcast or after any duration of time.
In at least one embodiment, the GUI200is presented based at least on user interaction with the application106, content item information152, and/or a graphical feedback element154. For example, the GUI200may be presented if a user interacts an option, such as with the graphical feedback element154B and/or the acquisition link158B associated with the content item150B identified in the video stream114. In such examples, the graphical feedback element154B or the acquisition link158B may comprise a link presented (e.g., via the graphical element(s)) or other information in the user interface ofFIG.1of a viewer of the video). The link may be to a service that provides the GUI200and/or manages a backend thereof. The service may be hosted on a different server and/or system than the device(s) used to analyze the video156for content items (e.g., a client device104and/or an identification server116) or many be hosted on the same server and/or system (e.g., on an identification server116). Selection of the option corresponding to the link may directly or indirectly (e.g., via a further option or prompt) redirect a user device to the service and/or the GUI200. In other examples, selecting the option may interface with the third party or external service without necessarily requiring presentation of a second user interface, such as the GUI200. For example, the option may be used to acquire the content item150directly from the user interface ofFIG.1through the service. The GUI200may contain a region that presents a content item depiction(s)202, which may include graphical elements representative of the content item. For example, the content item depiction202may include an image, video, and/or audio associated with the content item. An image and/or other information presented regarding a content item may be captured by the presentation manager124from the video156, or elsewhere, and may be referenced and/or accessed using a content identifier of the content item. In one or more embodiments, a content item depiction(s) may be stored locally or retrieved from a data store using the content identifier. For example, each content item may be associated with assets that are retrieved from one or more data stores128(e.g., from or by an identification server(s)116). In some cases, the content item depiction202may include a video or series of image frames. For example, the GUI200may present a portion of the gameplay video that contains the content item (e.g., in which the content item was detected using the MLM(s)122), or may present video from a different game session that includes the content item.
In some embodiments, the GUI200may include a graphical element(s)206that is selectable to acquire the content item. The graphical element(s)206may be selectable to allow a user to acquire the presented content item in a particular game. For example, the graphical element206may be selectable by a user to confirm that they would like to acquire the content item such as the “Shamrock Hat.”
Referring now toFIG.3,FIG.3is a block diagram300, showing a process for determining content items in video using machine learning models. It should be understood that this and other arrangements described herein are set forth only as examples. Other arrangements and elements (e.g., machines, interfaces, functions, orders, groupings of functions, etc.) can be used in addition to or instead of those shown, and some elements may be omitted altogether. Further, many of the elements described herein are functional entities that may be implemented as discrete or distributed components or in conjunction with other components, and in any suitable combination and location. Various functions described herein as being performed by entities may be carried out by hardware, firmware, and/or software. For instance, various functions may be carried out by a processor executing instructions stored in memory.
Image data302representative of one or more frames of the video156may be applied to an object detector304of the MLMs122that may detect one or more objects within the image data302. The object detector304may be trained to detect any of a number of distinct objects. Objects may include, by way of example and not limitation, game pieces, clothing, objects, skins, vehicles, buildings, towers, walls, players, crops, animals, etc. Multiple object detectors304and/or codebooks may be employed to detect different content items and/or types of content items. In some examples, the content item determiner120may select and/or determine the object detector(s)304from a plurality of object detectors trained to detect different types of objects. For example, the object detector(s)304that are used may be selected based at least on a game identifier of a game depicted in the video156, content of the video156, a user profile of the viewer of the video stream114and/or a streamer of the video156, metadata associated with the video156and/or the video stream114, etc.
In some examples, the object detector304may be trained to determine a bounding shape or region (e.g., bounding box) of each detected object, which may include bounding box coordinates. The bounding shape(s) may be captured in an output(s)306of the output detector304. In embodiments, the bounding shape or region may correspond to the content item information152ofFIG.1. For example, a bounding shape may define a location, size, and/or shape of a graphical element of the content item information152.
A content item determiner120may use the output(s)306to determine that one or more content items150are present within the video156that corresponds to the image data302. The output(s)306may comprise, for example, unprocessed output of the object detector304. Where the object detector304is based on a neural network (e.g., a CNN), the output may comprise tensor data indicating one or more detected objects and/or locations thereof (e.g., bounding shape locations). In some examples, an object detector304may be trained to detect particular content items. In such examples, a content item may correspond to an output class of an object detector304. The content item determiner120may determine one or more content items identified by the object detector304based on confidence scores represented by the output(s)306and regarding the content items. For example, where the content item determiner120determines a confidence score exceeds a threshold value, the content item determiner120may identify that content item in the video156. As further examples, an object detector304may be trained to detect a class or type of content item or object. For example, the output(s)306may be representative of confidence scores regarding classes or types of content items or objects. In such examples, the content item determiner120further use a twin neural network314to determine one or more content items150are present within the video156.
In employing the twin neural network314, the content item determiner310may receive reference output(s)308that may be used for comparison against output(s)316of the twin neural network314. A reference output(s)308may, for example, comprise data that represents a specific content item that the system100is to identify. For example, a reference output308may include output of the twin neural network314that represents or is known to correspond to a particular content item. Different reference outputs308may correspond to different content items. As an example, prior to deployment, reference outputs308may be generated by applying known images of content items to the twin neural network314. Outputs generated from one or more examples of a particular content item may be used to generate a reference output308for that content item. As an example, the outputs from different examples may be aggregated or otherwise combined into one or more feature vectors representing the content item from different sizes, angles, under different lighting conditions, or other contexts. A reference output308for a content item may be associated with a content identifier of the content item. For example, content identifiers may be indexed by reference output308to lookup a content identifier when a detected object is matched to the reference output308.
In at least one embodiment, to match a detected object with a reference output308, the content item determiner120may provide object data312that includes at least a portion of detected object as an input(s) to the twin neural network314. The object data312may include an image or representation of a detected object in the image data302. For example, the content item determiner120may crop the detected object out of one or more frames of the image data302and the object data312may include the cropped data. In various examples, a frame may be cropped based at least on the bounding shape determined using the object detector304. In the example shown, the “shamrock hat” object that was detected as an object in the image data302may be cropped and transmitted in the object data312.
Using the object data312, the twin neural network314may encode the object data312to a representation that is based on, for example, positive and/or negative examples of a content item(s)150. The encoding of the object data312may be include in the output(s)316and the content item determiner120may compare the encoding to the reference output(s)308to determine similarities between the encodings or to otherwise match the output(s)316to one or more reference outputs(s)308. Data representing a level similarity, such as a similarity score or confidence score, may be computed by the content item determiner120and used to select one or more corresponding content items150. For example, the content item determiner120may determine that a detected object is a particular content item based at least on a similarly score between the output316associated with the object and the reference output308associated with the content item. In at least one embodiment, the determination may be based at least on the similarity score exceeding a threshold value and/or based on a ranking of similarity score for the detected object and other content items (e.g., based on the similarity score being highest amongst a plurality of similarity scores for different content items). In at least one embodiment, the content identifier of a matched content item and/or metadata thereof—such as a location(s) or coordinates within the image data302—may be provided to the presentation manager124and/or the application106of a client device(s)104for presentation of associated information, as described herein.
Now referring toFIG.4, each block of method400, described herein, comprises a computing process that may be performed using any combination of hardware, firmware, and/or software. For instance, various functions may be carried out by a processor executing instructions stored in memory. The method may also be embodied as computer-usable instructions stored on computer storage media. The method may be provided by a standalone application, a service or hosted service (standalone or in combination with another hosted service), or a plug-in to another product, to name a few. In addition, method400is described, by way of example, with respect to the content item identification system ofFIG.1. However, this method may additionally or alternatively be executed by any one system, or any combination of systems, including, but not limited to, those described herein.
FIG.4is a flow diagram showing a method400for determining a content item, in accordance with some embodiments of the present disclosure. The method400, at block B402, includes receiving image data representative of gameplay video of a game. For example, the identification servers116may receive the image data302representative of the video156associated with the application106of a client device(s)104.
The method400, at block B404, includes applying the image data to a machine learning model(s) trained to detect an object(s) and identify a content item(s) in the image data. For example, the machine learning model(s)122may be trained by the training module118to detect objects in video data and identify content items based on the detections.
The method400, at block B406, includes determining a content item presented within the gameplay video. For example, based at least on detecting, using the MLM(s)122, an object corresponding to the content item150B within the video156, a content item determiner120may determine the content item150B presented within the video156. The method400, at block B408, includes causing display of an option using metadata of the content item, the option being selectable to cause presentation of a second user interface that presents information associated with the content item and one or more graphical elements selectable to acquire the content item in the game. For example, the presentation manager124of the identification server(s)116may transmit data that causes display of an option corresponding to content item information152B using metadata of the content item150B. The option may be selectable to cause presentation of the GUI200that presents information associated with the content item150B and the graphical element(s)206that may be selectable to acquire the content item150B in the game.
Now referring toFIG.5, each block of method500, described herein, comprises a computing process that may be performed using any combination of hardware, firmware, and/or software. For instance, various functions may be carried out by a processor executing instructions stored in memory. The method may also be embodied as computer-usable instructions stored on computer storage media. The method may be provided by a standalone application, a service or hosted service (standalone or in combination with another hosted service), or a plug-in to another product, to name a few. In addition, method500is described, by way of example, with respect to the content item identification system ofFIG.1. However, this method may additionally or alternatively be executed by any one system, or any combination of systems, including, but not limited to, those described herein.
FIG.5is a flow diagram showing a method500for presenting information associated with a content item, in accordance with some embodiments of the present disclosure. The method500, at block B502, includes presenting gameplay video of a game in a first user interface. For example, the application106of a client device(s)104may receive gameplay video data corresponding to the video stream114and present the video156as shown inFIG.1.
The method500, at block B504, includes receiving metadata of a content item detected in a gameplay video using a machine learning model(s). For example, the application106of the client device(s)104may receive metadata from the presentation manager124of the identification server(s)116that is related to a content item150that is detected using the MLM(s)122. In particular, the content item determiner120may apply gameplay video data corresponding to the video stream114to the MLM(s)122to detect one or more of the content item(s)150.
The method500, at block B506, includes causing display of an option that is selectable to cause presentation of a second interface that presents information associated with the content item and graphical elements selectable to acquire the content item. For example, the application106of the client device(s)104may display content item information152, graphical feedback elements154, and/or acquisition link(s)158associated with the video stream114. Any of these may comprise graphical elements selectable to acquire a corresponding content item(s)150. For example, in response to or based on a selection of an option, the GUI200may be presented in a second user interface.
Now referring toFIG.6, each block of method600, described herein, comprises a computing process that may be performed using any combination of hardware, firmware, and/or software. For instance, various functions may be carried out by a processor executing instructions stored in memory. The method may also be embodied as computer-usable instructions stored on computer storage media. The method may be provided by a standalone application, a service or hosted service (standalone or in combination with another hosted service), or a plug-in to another product, to name a few. In addition, method600is described, by way of example, with respect to the content item identification system ofFIG.1. However, this method may additionally or alternatively be executed by any one system, or any combination of systems, including, but not limited to, those described herein.
FIG.6is a flow diagram showing a method600for identification of a content item using a twin neural network, in accordance with some embodiments of the present disclosure. The method600, at block B602, includes receiving image data representative of a video. For example, the identification servers116(or a client device104in some embodiments) may receive the image data302representative of the video156of a game that is being presented in the application106of a client device(s)104. The content item determiner120may retrieve image data302from local and/or remote data store(s)128or may receive image data302from the streaming engine132of a video server(s)130(where the content item determiner120B is employed, the streaming engine132may be providing the video stream114to the client device104and another video stream of the video156to an identification server116).
The method600, at block B604, includes applying the image data to a machine learning model(s) to detect an object(s). For example, the content item determiner120may apply the image data of the video156to the object detector304of the MLM(s)122to detect one or more objects in the image data. In some examples the MLM(s) have been trained by the training module118. The object detector304may detect at least one region of the image data302corresponding to the detected objects. A region detected using the object detector304may correspond to the object data312ofFIG.3.
The method600, at block B606, includes applying a region(s) to a twin neural network. For example, the content item determiner120may apply the region corresponding to the object data312and detected by the object detector304, to the twin neural network314of the MLM(s)122. The twin neural network314may have been trained to encode representations of the content item(s)150using positive and/or negative examples of the content item(s)150.
The method600, at block B608, includes identifying a content item in the video. For example, the twin neural network314of the MLM(s)122may generate the output(s)316comprising an encoding of the object data312that corresponds to the region. The content item determiner may compare the encoding to one or more encodings captured by the reference outputs(s)308to identify a content item150in the video156.
The method600, at block B610, includes causing display of an option that is selectable to cause presentation of information associated with the content item and graphical elements selectable to acquire the content item. For example, an application106of a client device(s)104may display content item information152, graphical feedback elements154, and/or acquisition link(s)158associated with the video stream114. For example, the presentation manager124may cause display of one or more options corresponding to one or more of the graphical elements shown inFIG.1with respect to the display108.
Example Computing Device
FIG.7is a block diagram of an example computing device(s)700suitable for use in implementing some embodiments of the present disclosure. Computing device700may include an interconnect system702that directly or indirectly couples the following devices: memory704, one or more central processing units (CPUs)706, one or more graphics processing units (GPUs)708, a communication interface710, input/output (I/O) ports712, input/output components714, a power supply716, one or more presentation components718(e.g., display(s)), and one or more logic units720. In at least one embodiment, the computing device(s)700may comprise one or more virtual machines (VMs), and/or any of the components thereof may comprise virtual components (e.g., virtual hardware components). For non-limiting examples, one or more of the GPUs708may comprise one or more vGPUs, one or more of the CPUs706may comprise one or more vCPUs, and/or one or more of the logic units720may comprise one or more virtual logic units. As such, a computing device(s)700may include discrete components (e.g., a full GPU dedicated to the computing device700), virtual components (e.g., a portion of a GPU dedicated to the computing device700), or a combination thereof.
Although the various blocks ofFIG.7are shown as connected via the interconnect system702with lines, this is not intended to be limiting and is for clarity only. For example, in some embodiments, a presentation component718, such as a display device, may be considered an I/O component714(e.g., if the display is a touch screen). As another example, the CPUs706and/or GPUs708may include memory (e.g., the memory704may be representative of a storage device in addition to the memory of the GPUs708, the CPUs706, and/or other components). In other words, the computing device ofFIG.7is merely illustrative. Distinction is not made between such categories as “workstation,” “server,” “laptop,” “desktop,” “tablet,” “client device,” “mobile device,” “hand-held device,” “game console,” “electronic control unit (ECU),” “virtual reality system,” and/or other device or system types, as all are contemplated within the scope of the computing device ofFIG.7.
The interconnect system702may represent one or more links or busses, such as an address bus, a data bus, a control bus, or a combination thereof. The interconnect system702may include one or more bus or link types, such as an industry standard architecture (ISA) bus, an extended industry standard architecture (EISA) bus, a video electronics standards association (VESA) bus, a peripheral component interconnect (PCI) bus, a peripheral component interconnect express (PCIe) bus, and/or another type of bus or link. In some embodiments, there are direct connections between components. As an example, the CPU706may be directly connected to the memory704. Further, the CPU706may be directly connected to the GPU708. Where there is direct, or point-to-point connection between components, the interconnect system702may include a PCIe link to carry out the connection. In these examples, a PCI bus need not be included in the computing device700.
The memory704may include any of a variety of computer-readable media. The computer-readable media may be any available media that may be accessed by the computing device700. The computer-readable media may include both volatile and nonvolatile media, and removable and non-removable media. By way of example, and not limitation, the computer-readable media may comprise computer-storage media and communication media.
The computer-storage media may include both volatile and nonvolatile media and/or removable and non-removable media implemented in any method or technology for storage of information such as computer-readable instructions, data structures, program modules, and/or other data types. For example, the memory704may store computer-readable instructions (e.g., that represent a program(s) and/or a program element(s), such as an operating system. Computer-storage media may include, but is not limited to, RAM, ROM, EEPROM, flash memory or other memory technology, CD-ROM, digital versatile disks (DVD) or other optical disk storage, magnetic cassettes, magnetic tape, magnetic disk storage or other magnetic storage devices, or any other medium which may be used to store the desired information and which may be accessed by computing device700. As used herein, computer storage media does not comprise signals per se.
The computer storage media may embody computer-readable instructions, data structures, program modules, and/or other data types in a modulated data signal such as a carrier wave or other transport mechanism and includes any information delivery media. The term “modulated data signal” may refer to a signal that has one or more of its characteristics set or changed in such a manner as to encode information in the signal. By way of example, and not limitation, the computer storage media may include wired media such as a wired network or direct-wired connection, and wireless media such as acoustic, RF, infrared and other wireless media. Combinations of any of the above should also be included within the scope of computer-readable media.
The CPU(s)706may be configured to execute at least some of the computer-readable instructions to control one or more components of the computing device700to perform one or more of the methods and/or processes described herein. The CPU(s)706may each include one or more cores (e.g., one, two, four, eight, twenty-eight, seventy-two, etc.) that are capable of handling a multitude of software threads simultaneously. The CPU(s)706may include any type of processor, and may include different types of processors depending on the type of computing device700implemented (e.g., processors with fewer cores for mobile devices and processors with more cores for servers). For example, depending on the type of computing device700, the processor may be an Advanced RISC Machines (ARM) processor implemented using Reduced Instruction Set Computing (RISC) or an x86 processor implemented using Complex Instruction Set Computing (CISC). The computing device700may include one or more CPUs706in addition to one or more microprocessors or supplementary co-processors, such as math co-processors.
In addition to or alternatively from the CPU(s)706, the GPU(s)708may be configured to execute at least some of the computer-readable instructions to control one or more components of the computing device700to perform one or more of the methods and/or processes described herein. One or more of the GPU(s)708may be an integrated GPU (e.g., with one or more of the CPU(s)706and/or one or more of the GPU(s)708may be a discrete GPU. In embodiments, one or more of the GPU(s)708may be a coprocessor of one or more of the CPU(s)706. The GPU(s)708may be used by the computing device700to render graphics (e.g., 3D graphics) or perform general purpose computations. For example, the GPU(s)708may be used for General-Purpose computing on GPUs (GPGPU). The GPU(s)708may include hundreds or thousands of cores that are capable of handling hundreds or thousands of software threads simultaneously. The GPU(s)708may generate pixel data for output images in response to rendering commands (e.g., rendering commands from the CPU(s)706received via a host interface). The GPU(s)708may include graphics memory, such as display memory, for storing pixel data or any other suitable data, such as GPGPU data. The display memory may be included as part of the memory704. The GPU(s)708may include two or more GPUs operating in parallel (e.g., via a link). The link may directly connect the GPUs (e.g., using NVLINK) or may connect the GPUs through a switch (e.g., using NVSwitch). When combined together, each GPU708may generate pixel data or GPGPU data for different portions of an output or for different outputs (e.g., a first GPU for a first image and a second GPU for a second image). Each GPU may include its own memory, or may share memory with other GPUs.
In addition to or alternatively from the CPU(s)706and/or the GPU(s)708, the logic unit(s)720may be configured to execute at least some of the computer-readable instructions to control one or more components of the computing device700to perform one or more of the methods and/or processes described herein. In embodiments, the CPU(s)706, the GPU(s)708, and/or the logic unit(s)720may discretely or jointly perform any combination of the methods, processes and/or portions thereof. One or more of the logic units720may be part of and/or integrated in one or more of the CPU(s)706and/or the GPU(s)708and/or one or more of the logic units720may be discrete components or otherwise external to the CPU(s)706and/or the GPU(s)708. In embodiments, one or more of the logic units720may be a coprocessor of one or more of the CPU(s)706and/or one or more of the GPU(s)708.
Examples of the logic unit(s)720include one or more processing cores and/or components thereof, such as Tensor Cores (TCs), Tensor Processing Units (TPUs), Pixel Visual Cores (PVCs), Vision Processing Units (VPUs), Graphics Processing Clusters (GPCs), Texture Processing Clusters (TPCs), Streaming Multiprocessors (SMs), Tree Traversal Units (TTUs), Artificial Intelligence Accelerators (AIAs), Deep Learning Accelerators (DLAs), Arithmetic-Logic Units (ALUs), Application-Specific Integrated Circuits (ASICs), Floating Point Units (FPUs), input/output (I/O) elements, peripheral component interconnect (PCI) or peripheral component interconnect express (PCIe) elements, and/or the like.
The communication interface710may include one or more receivers, transmitters, and/or transceivers that enable the computing device700to communicate with other computing devices via an electronic communication network, included wired and/or wireless communications. The communication interface710may include components and functionality to enable communication over any of a number of different networks, such as wireless networks (e.g., Wi-Fi, Z-Wave, Bluetooth, Bluetooth LE, ZigBee, etc.), wired networks (e.g., communicating over Ethernet or InfiniBand), low-power wide-area networks (e.g., LoRaWAN, SigFox, etc.), and/or the Internet.
The I/O ports712may enable the computing device700to be logically coupled to other devices including the I/O components714, the presentation component(s)718, and/or other components, some of which may be built in to (e.g., integrated in) the computing device700. Illustrative I/O components714include a microphone, mouse, keyboard, joystick, game pad, game controller, satellite dish, scanner, printer, wireless device, etc. The I/O components714may provide a natural user interface (NUI) that processes air gestures, voice, or other physiological inputs generated by a user. In some instances, inputs may be transmitted to an appropriate network element for further processing. An NUI may implement any combination of speech recognition, stylus recognition, facial recognition, biometric recognition, gesture recognition both on screen and adjacent to the screen, air gestures, head and eye tracking, and touch recognition (as described in more detail below) associated with a display of the computing device700. The computing device700may be include depth cameras, such as stereoscopic camera systems, infrared camera systems, RGB camera systems, touchscreen technology, and combinations of these, for gesture detection and recognition. Additionally, the computing device700may include accelerometers or gyroscopes (e.g., as part of an inertia measurement unit (IMU)) that enable detection of motion. In some examples, the output of the accelerometers or gyroscopes may be used by the computing device700to render immersive augmented reality or virtual reality.
The power supply716may include a hard-wired power supply, a battery power supply, or a combination thereof. The power supply716may provide power to the computing device700to enable the components of the computing device700to operate.
The presentation component(s)718may include a display (e.g., a monitor, a touch screen, a television screen, a heads-up-display (HUD), other display types, or a combination thereof), speakers, and/or other presentation components. The presentation component(s)718may receive data from other components (e.g., the GPU(s)708, the CPU(s)706, etc.), and output the data (e.g., as an image, video, sound, etc.).
Example Content Streaming System
Now referring toFIG.8,FIG.8is an example system diagram for a content streaming system800, in accordance with some embodiments of the present disclosure.FIG.8includes application server(s)802(which may include similar components, features, and/or functionality to the example computing device700ofFIG.7), client device(s)804(which may include similar components, features, and/or functionality to the example computing device700ofFIG.7), and network(s)806(which may be similar to the network(s) described herein). In some embodiments of the present disclosure, the system800may be implemented. The application session may correspond to a game streaming application (e.g., NVIDIA GeFORCE NOW), a remote desktop application, a simulation application (e.g., autonomous or semi-autonomous vehicle simulation), computer aided design (CAD) applications, virtual reality (VR) and/or augmented reality (AR) streaming applications, deep learning applications, and/or other application types.
In the system800, for an application session, the client device(s)804may only receive input data in response to inputs to the input device(s), transmit the input data to the application server(s)802, receive encoded display data from the application server(s)802, and display the display data on the display824. As such, the more computationally intense computing and processing is offloaded to the application server(s)802(e.g., rendering—in particular ray or path tracing—for graphical output of the application session is executed by the GPU(s) of the game server(s)802). In other words, the application session is streamed to the client device(s)804from the application server(s)802, thereby reducing the requirements of the client device(s)804for graphics processing and rendering. In one or more embodiments, video156may be of the application session, which may be streamed to one or more viewers and/or a player of the game. For example, the player may receive a stream of the game in a gaming application that presents the stream, whereas a viewer may receive the stream in a video player application that presents the game (e.g., within a web browser). In various examples, the application server(s)802may comprise the video server(s)130or the video server(s)130may be separate from the application server(s)802.
For example, with respect to an instantiation of an application session, a client device804may be displaying a frame of the application session on the display824based on receiving the display data from the application server(s)802. The client device804may receive an input to one of the input device(s) and generate input data in response. The client device804may transmit the input data to the application server(s)802via the communication interface820and over the network(s)806(e.g., the Internet), and the application server(s)802may receive the input data via the communication interface818. The CPU(s) may receive the input data, process the input data, and transmit data to the GPU(s) that causes the GPU(s) to generate a rendering of the application session. For example, the input data may be representative of a movement of a character of the user in a game session of a game application, firing a weapon, reloading, passing a ball, turning a vehicle, etc. The rendering component812may render the application session (e.g., representative of the result of the input data) and the render capture component814may capture the rendering of the application session as display data (e.g., as image data capturing the rendered frame of the application session). The rendering of the application session may include ray or path-traced lighting and/or shadow effects, computed using one or more parallel processing units—such as GPUs, which may further employ the use of one or more dedicated hardware accelerators or processing cores to perform ray or path-tracing techniques—of the application server(s)802. In some embodiments, one or more virtual machines (VMs)—e.g., including one or more virtual components, such as vGPUs, vCPUs, etc.—may be used by the application server(s)802to support the application sessions. The encoder816may then encode the display data to generate encoded display data and the encoded display data may be transmitted to the client device804over the network(s)806via the communication interface818. The client device804may receive the encoded display data via the communication interface820and the decoder822may decode the encoded display data to generate the display data. The client device804may then display the display data via the display824.
Example Data Center
FIG.9illustrates an example data center900that may be used in at least one embodiments of the present disclosure. The data center900may include a data center infrastructure layer910, a framework layer920, a software layer930, and/or an application layer940.
As shown inFIG.9, the data center infrastructure layer910may include a resource orchestrator912, grouped computing resources914, and node computing resources (“node C.R.s”)916(1)-916(N), where “N” represents any whole, positive integer. In at least one embodiment, node C.R.s916(1)-916(N) may include, but are not limited to, any number of central processing units (“CPUs”) or other processors (including accelerators, field programmable gate arrays (FPGAs), graphics processors or graphics processing units (GPUs), etc.), memory devices (e.g., dynamic read-only memory), storage devices (e.g., solid state or disk drives), network input/output (“NW I/O”) devices, network switches, virtual machines (“VMs”), power modules, and/or cooling modules, etc. In some embodiments, one or more node C.R.s from among node C.R.s916(1)-916(N) may correspond to a server having one or more of the above-mentioned computing resources. In addition, in some embodiments, the node C.R.s916(1)-9161(N) may include one or more virtual components, such as vGPUs, vCPUs, and/or the like, and/or one or more of the node C.R.s916(1)-916(N) may correspond to a virtual machine (VM).
In at least one embodiment, grouped computing resources914may include separate groupings of node C.R.s916housed within one or more racks (not shown), or many racks housed in data centers at various geographical locations (also not shown). Separate groupings of node C.R.s916within grouped computing resources914may include grouped compute, network, memory or storage resources that may be configured or allocated to support one or more workloads. In at least one embodiment, several node C.R.s916including CPUs, GPUs, and/or other processors may be grouped within one or more racks to provide compute resources to support one or more workloads. The one or more racks may also include any number of power modules, cooling modules, and/or network switches, in any combination.
The resource orchestrator922may configure or otherwise control one or more node C.R.s916(1)-916(N) and/or grouped computing resources914. In at least one embodiment, resource orchestrator922may include a software design infrastructure (“SDI”) management entity for the data center900. The resource orchestrator922may include hardware, software, or some combination thereof.
In at least one embodiment, as shown inFIG.9, framework layer920may include a job scheduler932, a configuration manager934, a resource manager936, and/or a distributed file system938. The framework layer920may include a framework to support software944of software layer930and/or one or more application(s)942of application layer940. The software944or application(s)942may respectively include web-based service software or applications, such as those provided by Amazon Web Services, Google Cloud and Microsoft Azure. The framework layer920may be, but is not limited to, a type of free and open-source software web application framework such as Apache Spark™ (hereinafter “Spark”) that may utilize distributed file system938for large-scale data processing (e.g., “big data”). In at least one embodiment, job scheduler932may include a Spark driver to facilitate scheduling of workloads supported by various layers of data center900. The configuration manager934may be capable of configuring different layers such as software layer930and framework layer920including Spark and distributed file system938for supporting large-scale data processing. The resource manager936may be capable of managing clustered or grouped computing resources mapped to or allocated for support of distributed file system938and job scheduler932. In at least one embodiment, clustered or grouped computing resources may include grouped computing resource914at data center infrastructure layer910. The resource manager1036may coordinate with resource orchestrator912to manage these mapped or allocated computing resources.
In at least one embodiment, software944included in software layer930may include software used by at least portions of node C.R.s916(1)-916(N), grouped computing resources914, and/or distributed file system938of framework layer920. One or more types of software may include, but are not limited to, Internet web page search software, e-mail virus scan software, database software, and streaming video content software.
In at least one embodiment, application(s)942included in application layer940may include one or more types of applications used by at least portions of node C.R.s916(1)-916(N), grouped computing resources914, and/or distributed file system938of framework layer920. One or more types of applications may include, but are not limited to, any number of a genomics application, a cognitive compute, and a machine learning application, including training or inferencing software, machine learning framework software (e.g., PyTorch, TensorFlow, Caffe, etc.), and/or other machine learning applications used in conjunction with one or more embodiments.
In at least one embodiment, any of configuration manager934, resource manager936, and resource orchestrator912may implement any number and type of self-modifying actions based on any amount and type of data acquired in any technically feasible fashion. Self-modifying actions may relieve a data center operator of data center900from making possibly bad configuration decisions and possibly avoiding underutilized and/or poor performing portions of a data center.
The data center900may include tools, services, software or other resources to train one or more machine learning models or predict or infer information using one or more machine learning models according to one or more embodiments described herein. For example, a machine learning model(s) may be trained by calculating weight parameters according to a neural network architecture using software and/or computing resources described above with respect to the data center900. In at least one embodiment, trained or deployed machine learning models corresponding to one or more neural networks may be used to infer or predict information using resources described above with respect to the data center900by using weight parameters calculated through one or more training techniques, such as but not limited to those described herein.
In at least one embodiment, the data center900may use CPUs, application-specific integrated circuits (ASICs), GPUs, FPGAs, and/or other hardware (or virtual compute resources corresponding thereto) to perform training and/or inferencing using above-described resources. Moreover, one or more software and/or hardware resources described above may be configured as a service to allow users to train or performing inferencing of information, such as image recognition, speech recognition, or other artificial intelligence services.
Example Network Environments
Network environments suitable for use in implementing embodiments of the disclosure may include one or more client devices, servers, network attached storage (NAS), other backend devices, and/or other device types. The client devices, servers, and/or other device types (e.g., each device) may be implemented on one or more instances of the computing device(s)700ofFIG.7—e.g., each device may include similar components, features, and/or functionality of the computing device(s)700. In addition, where backend devices (e.g., servers, NAS, etc.) are implemented, the backend devices may be included as part of a data center900, an example of which is described in more detail herein with respect toFIG.9.
Components of a network environment may communicate with each other via a network(s), which may be wired, wireless, or both. The network may include multiple networks, or a network of networks. By way of example, the network may include one or more Wide Area Networks (WANs), one or more Local Area Networks (LANs), one or more public networks such as the Internet and/or a public switched telephone network (PSTN), and/or one or more private networks. Where the network includes a wireless telecommunications network, components such as a base station, a communications tower, or even access points (as well as other components) may provide wireless connectivity.
Compatible network environments may include one or more peer-to-peer network environments—in which case a server may not be included in a network environment—and one or more client-server network environments—in which case one or more servers may be included in a network environment. In peer-to-peer network environments, functionality described herein with respect to a server(s) may be implemented on any number of client devices.
In at least one embodiment, a network environment may include one or more cloud-based network environments, a distributed computing environment, a combination thereof, etc. A cloud-based network environment may include a framework layer, a job scheduler, a resource manager, and a distributed file system implemented on one or more of servers, which may include one or more core network servers and/or edge servers. A framework layer may include a framework to support software of a software layer and/or one or more application(s) of an application layer. The software or application(s) may respectively include web-based service software or applications. In embodiments, one or more of the client devices may use the web-based service software or applications (e.g., by accessing the service software and/or applications via one or more application programming interfaces (APIs)). The framework layer may be, but is not limited to, a type of free and open-source software web application framework such as that may use a distributed file system for large-scale data processing (e.g., “big data”).
A cloud-based network environment may provide cloud computing and/or cloud storage that carries out any combination of computing and/or data storage functions described herein (or one or more portions thereof). Any of these various functions may be distributed over multiple locations from central or core servers (e.g., of one or more data centers that may be distributed across a state, a region, a country, the globe, etc.). If a connection to a user (e.g., a client device) is relatively close to an edge server(s), a core server(s) may designate at least a portion of the functionality to the edge server(s). A cloud-based network environment may be private (e.g., limited to a single organization), may be public (e.g., available to many organizations), and/or a combination thereof (e.g., a hybrid cloud environment).
The client device(s) may include at least some of the components, features, and functionality of the example computing device(s)700described herein with respect toFIG.7. By way of example and not limitation, a client device may be embodied as a Personal Computer (PC), a laptop computer, a mobile device, a smartphone, a tablet computer, a smart watch, a wearable computer, a Personal Digital Assistant (PDA), an MP3 player, a virtual reality headset, a Global Positioning System (GPS) or device, a video player, a video camera, a surveillance device or system, a vehicle, a boat, a flying vessel, a virtual machine, a drone, a robot, a handheld communications device, a hospital device, a gaming device or system, an entertainment system, a vehicle computer system, an embedded system controller, a remote control, an appliance, a consumer electronic device, a workstation, an edge device, any combination of these delineated devices, or any other suitable device.
The disclosure may be described in the general context of computer code or machine-useable instructions, including computer-executable instructions such as program modules, being executed by a computer or other machine, such as a personal data assistant or other handheld device. Generally, program modules including routines, programs, objects, components, data structures, etc., refer to code that perform particular tasks or implement particular abstract data types. The disclosure may be practiced in a variety of system configurations, including hand-held devices, consumer electronics, general-purpose computers, more specialty computing devices, etc. The disclosure may also be practiced in distributed computing environments where tasks are performed by remote-processing devices that are linked through a communications network.
As used herein, a recitation of “and/or” with respect to two or more elements should be interpreted to mean only one element, or a combination of elements. For example, “element A, element B, and/or element C” may include only element A, only element B, only element C, element A and element B, element A and element C, element B and element C, or elements A, B, and C. In addition, “at least one of element A or element B” may include at least one of element A, at least one of element B, or at least one of element A and at least one of element B. Further, “at least one of element A and element B” may include at least one of element A, at least one of element B, or at least one of element A and at least one of element B.
The subject matter of the present disclosure is described with specificity herein to meet statutory requirements. However, the description itself is not intended to limit the scope of this disclosure. Rather, the inventors have contemplated that the claimed subject matter might also be embodied in other ways, to include different steps or combinations of steps similar to the ones described in this document, in conjunction with other present or future technologies. Moreover, although the terms “step” and/or “block” may be used herein to connote different elements of methods employed, the terms should not be interpreted as implying any particular order among or between various steps herein disclosed unless and except when the order of individual steps is explicitly described.
Claims
- A method comprising: detecting, using one or more machine learning models (MLMs) and image data representative of a video of a video stream being presented in a user interface, one or more objects within the video;based at least on the detecting of the one or more objects, determining one or more content items presented within the video, at least one content item of the one or more content items corresponding to at least one object of the one or more objects;and causing presentation of information associated with the at least one content item and one or more graphical elements that include at least one link to at least one user interface to perform an acquisition of an instance of the at least one content item based at least on a selection of the one or more graphical elements.
- The method of claim 1, wherein the presentation is based at least on a user input to the user interface being associated with the at least one content item.
- The method of claim 1, further comprising accessing a data store using a content identifier of the at least one content item to retrieve metadata of the at least one content item, wherein the presentation uses the metadata.
- The method of claim 1, wherein the one or more MLMs include a twin neural network, and the determining the one or more content items uses the twin neural network to identify the at least one content item in a region of the video.
- The method of claim 1, wherein the video stream is from a pipeline of a video platform that serves video streams of the video to a plurality of users.
- The method of claim 1, wherein at least one of the one or more MLMs is trained to identify the at least one content item using positive examples of the at least one content item.
- The method of claim 1, wherein the determining the one or more content items includes comparing encoded representations of content items to an encoded representation of one or more portions of the video.
- The method of claim 1, wherein the one or more MLMs detect the at least one object in a region of one or more frames of the video, and an option is presented in the user interface at a location that corresponds to the region.
- The method of claim 1, wherein an option is presented with a plurality of frames of the video based at least on tracking the at least one object across the plurality of frames.
- A system comprising: one or more processors to execute operations comprising: detecting, using one or more machine learning models (MLMs) and image data representative of a video of a video stream being presented in a user interface, one or more objects within the video;based at least on the detecting of the one or more objects, determining one or more content items presented within the video, at least one content item of the one or more content items corresponding to at least one object of the one or more objects;and causing presentation of information associated with the at least one content item and one or more graphical elements that include at least one link to at least one user interface to perform an acquisition of an instance of the at least one content item based at least on a selection of the one or more graphical elements.
- The system of claim 10, wherein the one or more graphical elements are presented in one or more of the user interface, an e-mail, a text message, a notification, or a pop-up.
- The system of claim 10, wherein one or more graphical elements include an overlay to the video in the user interface, the overlay displayed in association with a region of one or more frames of the video.
- The system of claim 10, wherein metadata of the at least one content item comprises an indication of one or more frames of the video and the presentation is in association with the one or more frames based at least on the metadata.
- The system of claim 10, wherein the video comprises one or more of gameplay video of a game or application video of an application session.
- The system of claim 10, wherein the system is comprised in at least one of: a system for performing one or more simulation operations;a system for performing one or more digital twin operations;a system for performing light transport simulation;a system for performing one or more deep learning operations;a system for performing one or more generative AI operations;a system implemented using an edge device;a system incorporating one or more virtual machines (VMs);a system implemented at least partially in a data center;or a system implemented at least partially using cloud computing resources.
- At least one processor comprising: one or more circuits to cause presentation of information associated with at least one content item and one or more graphical elements that include at least one link to at least one user interface to perform an acquisition of an instance of the at least one content item based at least on a selection of the one or more graphical elements, the presentation being based least on: detecting, using one or more machine learning models (MLMs) and image data representative of a video of a video stream being presented in a user interface, one or more objects within the video;and based at least on the detecting of the one or more objects, determining one or more content items presented within the video, the at least one content item of the one or more content items corresponding to at least one object of the one or more objects.
- The at least one processor of claim 16, wherein the determining the one or more content items includes comparing at least a first output of the one or more MLMs that is associated with the at least one content item with at least a second output of the one or more MLMs that corresponds to at least one region in the video.
- The at least one processor of claim 16, wherein the presentation is based at least on a user input to the user interface being associated with the at least one content item.
- The at least one processor of claim 16, wherein the one or more circuits are further to access a data store using a content identifier of the at least one content item to retrieve metadata of the at least one content item, wherein the presentation uses the metadata.
- The at least one processor of claim 16, wherein the processor is comprised in at least one of: a system for performing one or more simulation operations;a system for performing one or more digital twin operations;a system for performing light transport simulation;a system for performing one or more deep learning operations;a system for performing one or more generative AI operations;a system implemented using an edge device;a system incorporating one or more virtual machines (VMs);a system implemented at least partially in a data center;or a system implemented at least partially using cloud computing resources.
Disclaimer: Data collected from the USPTO and may be malformed, incomplete, and/or otherwise inaccurate.