U.S. Pat. No. 12,311,268
Automated Validation of Video Game Environments
AssigneeELECTRONIC ARTS INC.
Issue DateNovember 8, 2022
Illustrative Figure
Abstract
This specification provides a computer-implemented method comprising providing, by a user, one or more demonstrations of a video game entity interacting with a video game environment to achieve a goal. The method further comprises generating, from the one or more demonstrations, one or more training examples. The method further comprises training an agent to control the video game entity using a neural network. The training comprises generating one or more predicted actions for each training example by processing, using the neural network, input data derived from the training example, and updating parameters of the neural network based on a comparison between the one or more predicted actions of the training examples and the one or more corresponding target actions of the training examples. The method further comprises performing validation of the video game environment, comprising controlling the video game entity in the video game environment using the trained agent.
Description
DESCRIPTION General Definitions The following terms are defined to aid the present disclosure and not limit the scope thereof. A “user” or “player”, as used in some embodiments herein, refers to an individual and/or the computing system(s) or device(s) corresponding to (e.g., associated with, operated by) that individual. A “client”, as used in some embodiments described herein, is a software application with which a user interacts, and which can be executed on a computing system or device locally, remotely, or over a cloud service. A “server”, as used in some embodiments described here, is a software application configured to provide certain services to a client, e.g. content and/or functionality. A “video game”, as used in some embodiments described herein, is a virtual interactive environment in which players engage. Video game environments may be facilitated through a client-server framework in which a client may connect with the server to access at least some of the content and functionality of the video game. A “video game entity”, as used in some embodiments described herein, is a video game controllable entity or game asset capable of performing actions, or otherwise interacting, in a video game environment of a video game that may or may not be controlled by a player of the video game and/or may be computer-controlled. A video game entity may include, without limitation, a player character, a player vehicle or other game entity, a non-player character, a non-player vehicle or other game entity and the like and/or any other aspect of a game asset/entity within the video game environment. This specification describes systems and methods for performing validation of video game environments using a trained neural network. In particular, the systems and methods described herein can be used to efficiently perform automated validation/playtesting of video game environments in an easily ...
DESCRIPTION
General Definitions
The following terms are defined to aid the present disclosure and not limit the scope thereof.
A “user” or “player”, as used in some embodiments herein, refers to an individual and/or the computing system(s) or device(s) corresponding to (e.g., associated with, operated by) that individual.
A “client”, as used in some embodiments described herein, is a software application with which a user interacts, and which can be executed on a computing system or device locally, remotely, or over a cloud service.
A “server”, as used in some embodiments described here, is a software application configured to provide certain services to a client, e.g. content and/or functionality.
A “video game”, as used in some embodiments described herein, is a virtual interactive environment in which players engage. Video game environments may be facilitated through a client-server framework in which a client may connect with the server to access at least some of the content and functionality of the video game.
A “video game entity”, as used in some embodiments described herein, is a video game controllable entity or game asset capable of performing actions, or otherwise interacting, in a video game environment of a video game that may or may not be controlled by a player of the video game and/or may be computer-controlled. A video game entity may include, without limitation, a player character, a player vehicle or other game entity, a non-player character, a non-player vehicle or other game entity and the like and/or any other aspect of a game asset/entity within the video game environment.
This specification describes systems and methods for performing validation of video game environments using a trained neural network. In particular, the systems and methods described herein can be used to efficiently perform automated validation/playtesting of video game environments in an easily accessible manner. For example, the described systems and methods may assist video game designers to validate that, during the design/development phase of the video game, the video game plays as intended. As another example, the described systems and methods may be used in video games where video game environments can be generated or otherwise modified by players of the video game. In this way, player-generated video game environments can easily be validated by players themselves to ensure that their generated video game environment (e.g. levels, maps, etc.) plays as intended.
Existing approaches of performing automated validation are often time-consuming and/or require specialized knowledge by the validators in different domains (e.g. programming, machine learning, etc.). For example, many approaches to performing automated validation/playtesting of video game environments often involve the use of hand-scripted computer-controlled agents and/or the use of reinforcement learning. The resulting computer-controlled agents may be configured to automatically control one or more game entities and/or assets and the like within the video game environment. Hand-scripting computer-controlled agents is time-consuming, requires the user to have programming knowledge, and often these computer-controlled agents do not generalize well to changes in the video game environment. Approaches involving reinforcement learning for generating a computer-controlled agent, which are referred to herein as a machine learning (ML) agent, generally require hours/days of demonstrations to suitably train the ML agent to control video game entities and/or assets in video game environments, require long training times (e.g. days of training) and often require the user to have machine learning knowledge and expertise (e.g. in order to shape reward functions so that the trained ML agent exhibits desired behaviors).
The systems and methods described herein use imitation learning to train ML agents that control video game entities and/or assets in the video game environment. In imitation learning, a number of demonstrations (also referred to herein as trajectories) are provided by a user (e.g. a game designer, a player of the video game, etc.) controlling one or more video game entities, and the ML agent(s) are trained using the demonstrations such that when trained, the ML agent(s) control the video game entity to generally imitate the actions performed by the user in the demonstrations. Demonstrations may be provided by users in the same manner as how players would play the video game (e.g. using the same input and control mechanisms). In this way, automated validation of the video game environment can be performed, e.g. by controlling the video game entity in the video game environment using the trained ML agent(s), without the user requiring specialized knowledge in different domains.
Furthermore, the use of imitation learning to train ML agents in the described systems and methods greatly increases sample efficiency when compared to approaches involving reinforcement learning, reducing the time and amount of data needed to train agents to interact in video game environments from hours/days down to minutes. The reduction in set up time/data requirements by the methods and systems described herein allows automated validation to be used as part of the game design/development process, providing a feedback loop for game designers to iteratively design and validate the video game environment. The reduction in set up time/data requirements also enable the described systems and methods to be provided as part of a video game application for use by players of video games to validate player-generated environments. In addition, ML agents trained using the methods and systems described herein can be easily updated/retrained, e.g. in order to correct mistakes in the behavior of the initially trained ML agent, by the user providing a small number of corrected demonstrations demonstrating the correct behavior. The ML agents trained using the systems and methods described herein can adapt to changes in the video game environment without requiring retraining, or with minimal retraining if needed for major changes to the video game environment. This provides increased interactivity for game designers when the described systems and methods are used in the game design process.
FIG.1is a schematic block diagram illustrating an example100of a computing system101configured to perform automated validation of video game environments. The computing system101is configured to receive one or more demonstrations of a user controlling a video game entity105in the video game environment, and to train an ML agent107to control the video game entity105using training examples111generated from the one or more demonstrations. For the sake of clarity, the computing system101is illustrated as comprising a specific number of components. Any of the functionality described as being performed by a specific component of the system may instead be performed across a number of components, and/or functionality described as being performed by multiple components may be performed on a single component. For example, one or more of the video game environment designer component106, ML agent107and neural network108, and training system109may be provided as part of the gaming application102.
The computing system101includes gaming application102configured to provide a video game. Gaming application102includes a game engine103. The game engine103can be configured to execute aspects of the operation of the gaming application102according to game rules. Examples of game rules can include rules for scoring, possible inputs, actions/events, movement in response to inputs, and the like. The game engine103may receive inputs (provided by a user and/or by other components of the system tot) and determine in-game events, such as actions, jumps, runs, throws, attacks, and other events appropriate for the gaming application102. During runtime operation, the game engine103can read user inputs, in-game data, and game state information to determine the appropriate in-game events.
Furthermore, the game engine103is configured to determine the state of a video game environment of the video game as it is being played. For example, in a shooter or action-based adventure video game, the video game environment may be of a particular battlefield or adventure region/area that is being navigated by one or more players and the like. In this example, the state of the video game environment may include the positions of the various video game entities105participating in the shooter battlefield or adventure region/area, the status, health, or any other attribute of the video game entities105, the time in the shooter game or adventure game (e.g. the amount of game time that has elapsed). The game engine103may determine the state of the video game environment of the video game continually (e.g. periodically, such as before the rendering of each video frame, multiple frames, etc.). It should be noted that the above-described example of the video game being a shooter or action-based adventure video game is an illustrative example. For example, the video game may be any type of video game in which one or more video game entities may be controlled by the video game such as, without limitation, for example a real-time strategy game; an action-adventure game; survival and/or horror game; a first person and/or third person shooter game; simulation, racing and/or sports game; multiplayer online battle arena (MOBA) game; music game; sandbox and/or simulation game; role-playing game (e.g. RPG, Action RPG, massively multiplayer online RPGs, tactical RPGs and the like, etc.); platformer game; and/or any other type of video game with video game entities controllable using one or more trainable ML agents.
Gaming application102includes game assets104which contain data/objects that are accessed as the video game is being played. The game assets104include game entities105in addition to other assets such as image files, audio files, etc. The game entities toy are video game controllable entities or game assets capable of performing actions, or otherwise interacting, in a video game environment of a video game that may or may not be controlled by a player of the video game such as, without limitation, a player character, a player vehicle or other game entity, a non-player character, a non-player vehicle or other game entity and the like and/or any other aspect of a game asset/entity within the video game environment. At least one game entity of the game entities105is controllable by ML agent107.
The computing system101includes a video game environment designer component106(or video game environment designer106) that is used for designing the video game environment. The video game environment designer106may be an application that can be used by game designers and/or may be a component of the gaming application102that can be used/accessed by players of the video game. The video game environment designer106configures the game engine103and/or game assets104based on received user inputs. For example, the user may provide an input to the video game environment designer106specifying the configuration of various game assets104, such as game entities105, obstacles, goals and intermediate goals for an entity controllable by the ML agent107to achieve, and configures the game engine103and/or game assets104to provide a video game environment in accordance with the user input. As an example, in an action-based adventure video game, the user may use the video game environment designer106to design a video game environment specifying the spawn location for a game entity controllable by the ML agent107, the spawn location of enemy game entities, the layout of the video game environment, the location of dynamic objects, the location of an intermediate goal, the location of a goal and so on.
The computing system101includes an ML agent107used to control one or more game entities105. Although for illustrative purposes a single ML agent107is illustrated inFIG.1, it will be appreciated that any number of ML agents107may be provided as part of the computing system101. For example, there may be different ML agents for different game entities105, different ML agents for different playing styles/personas of the same game entity toy, etc. The ML agent107interacts with the video game environment by sending actions/game inputs to game engine103for controlling the one or more game entities. The ML agent107also obtains data from the game engine103and/or game assets104for use in generating actions for the one or more game entities105to perform. For example, the ML agent107can receive representations of the state of the video game environment continually (e.g. periodically, such as before the rendering of each video frame, multiple frames, etc.). As an example, in a shooter video game, the ML agent107can continually receive information regarding the location of the one or more game entities105being controlled by the ML agent107, the location of enemy game entities105, attributes for the one or more ML agent-controlled game entities105(e.g. health status, ammunition amount, etc.), the current score of a match being played, and so on, and use this information to generate actions for the ML agent-controlled game entities105. In this example, the various actions may include moving in various directions, running, jumping, shooting, reloading, and so on, and one or more actions may be generated at the same time.
The ML agent107comprises a neural network108used to generate actions for the one or more ML agent-controlled game entities105. An example neural network108is described in more detail in relation toFIG.3. The neural network108receives inputs continually (e.g. periodically, such as before the rendering of each video frame, multiple frames, etc.) relating to the current state of the video game environment, and processes the inputs to generate actions for the one or more ML agent-controlled game entities105to perform at a particular time step (e.g. a time step immediately following a time step relating to the received inputs). The neural network108comprises a plurality of neural network layers, each neural network layer associated with a set of parameters/weights.
The input data for the neural network108is provided in the form of vectors, matrices and/or tensors. For example, the ML agent107may receive information relating to a current state of the video game environment, and format this information as vectors, matrices, and/or tensors for input to the neural network108.
Entity data for each of various game entities toy may be formatted as a vector with each element of the vector representing a different feature/characteristic for the current state of the game entity105. For example, the entity data may comprise a vector representation of the position of the game entity105of the video game environment. The positions may be indicated by absolute position (e.g. co-ordinates of the entities with respect to an origin of a co-ordinate system) and/or by relative position (e.g. co-ordinates with respect to a particular entity or goal location of the video game environment). The entity data may comprise a representation of characteristics/attributes for the game entity toy. For example, the characteristics/attributes may include a current status of the game entity toy (e.g. health, ammunition), an indicator indicating whether the game entity105has acquired a certain game item, and so on. Additionally, the input data may comprise further data used for generating actions. For example, in the case that the neural network108is used to generate actions for a plurality of game entities105, a selection of a particular game entity toy for which actions are to be generated may be provided in the input data. The input data may comprise indicators of the various game entities105of the video game environment and/or their characteristics. The input data may comprise data relating to one or more objects of the video game environment, e.g. the position of a ball in a football video game, or the positions of enemy fighters in a shooter game, or the positions of race participants/entities in a racing game etc.
The input data may comprise a representation of a particular region of the video game environment. For example, the ML agent107may be used to control a particular game entity105and the input data to the neural network108may comprise a representation of a region of the video game environment comprising the ML agent-controlled game entity105. The representation may be a semantic map of the region comprising a map that is segmented according to the characteristics of different sub-regions in the region. For example, the semantic map may distinguish between obstacles and unobstructed areas by representing unobstructed areas with a particular value, and obstacles with another value. The region represented by the semantic map may be gridded and the semantic map may indicate characteristics of the video game environment at each grid position. The semantic map may be two-dimensional (e.g. for a platformer video game) and the input data to the neural network108representing the semantic map may be in the form of a matrix. The matrix may represent subregions of the region that share characteristics/that are of the same type using the same value (e.g. a same integer). Alternatively, the semantic map may be three-dimensional (e.g. for an action-adventure video game) and the input data to the neural network108representing the semantic map may be in the form of a tensor. The tensor may represent subregions of the region that share characteristics/that are of the same type using the same value (e.g. a same integer). Any suitable number of different subregion types may be represented in the semantic map.
The computing system101includes a training system109that is used to train the ML agent107to control ML agent-controlled game entities105. The training system109receives one or more demonstrations of a user/player controlling a game entity105in the video game environment, generates training examples iii from the one or more user demonstrations, and trains the ML agent107by updating parameters of the neural network108using the training examples tn. The training of the ML agent107is described in greater detail in relation toFIG.4.
The training system109includes a demonstration recorder110which records demonstrations of a user controlling a game entity105using data obtained from the game engine103and/or game assets104. Users can provide demonstrations of controlling game entities105in the same manner as players would control game entities105, e.g. by using the same input and control mechanisms. During each demonstration provided by the user, the demonstration recorder110continually (e.g. periodically, such as before the rendering of each video frame, multiple frames, etc.) obtains data relating to the state of the video game environment at the current time step and associates this with actions performed by the user at a subsequent time step (e.g. the time step immediately following the current time step).
The data relating to the state of the video game environment at the current time step is used to form a training input of a training example iii and the actions performed by the user at the subsequent time step is used to form the target output for the training example tn. The demonstration recorder110may process the data relating to the state of the video game environment at the current time step to form a training input that is suitable for input and subsequent processing by the neural network108. Similarly, the demonstration recorder110may process the action(s) performed by the user at the subsequent time step to form a target output that is suitable for training the neural network108.
When obtaining data relating to the state of the video game environment at the current time step, the demonstration recorder no obtains data about the game entity105being controlled by the user, in addition to data about other game entities105in the video game environment. For example, the demonstration recorder110may obtain data about other game entities105based on proximity to the game entity105being controlled by the user, e.g. for any game entity105within a certain radius of the user-controlled game entity105, and/or for a number of the closest game entities105to the user-controlled game entity105at the current time step. Additionally or alternatively, particular game entities105may be specified for which data should be obtained by the demonstration recorder110. The demonstration recorder110may process the obtained data to generate entity data for the user-controlled game entity105and the other game entities105. The entity data may specify the location of the game entity105, e.g. by absolute position or relative position with respect to a goal location, and any other attribute/characteristic of the game entity105(e.g. health, status, etc.). The entity data for each of the user-controlled game entity105and the other game entities105may be used to form the training input of a training example111.
When obtaining data relating to the state of the video game environment at the current time step, the demonstration recorder110may also obtain data about a region of the video game environment comprising the user-controlled game entity105. For example, the region of the video game environment may be gridded and the demonstration recorder no may obtain data about the characteristics of the video game environment at each grid position. The demonstration recorder110may process the obtained data to generate a segmented map for the region, wherein the map is segmented according to the characteristics of subregions, e.g. at each grid position. Such a segmented map may be referred to as a semantic map, as the map encodes information about the region. The segmented map may be integer-encoded, e.g. a different integer may represent a different characteristic of subregions. The demonstration recorder110may configure the size, shape, resolution, etc. of the region of the video game environment represented by the segmented map. The segmented map may also be used to form the training input of the training example111.
The demonstration recorder110may record demonstrations of the user controlling different game entities105and/or record demonstrations of the user controlling the same game entity105in different playstyles/personas (e.g. aggressive, defensive, etc.). The training input of training examples111may indicate which game entity105the user was controlling for the training example111. Additionally or alternatively, the training input of training examples111may indicate the playstyle/persona in which the105the user was controlling the game entity105for the training example111.
After training the ML agent107by updating parameters of the neural network108using one or more training examples111, validation of the video game environment is performed using the trained ML agent107. The trained ML agent107controls one or more game entities105for which it was trained to control by continually processing inputs relating to the current state of the video game environment and generating actions for the one or more ML agent-controlled game entities105to perform in a subsequent time step. The user may direct the trained ML agent107to control the one or more ML agent-controlled game entities105to achieve one or more goals or subgoals within the video game environment. The one or more ML agent controlled game entities105may be placed anywhere within the video game environment and the trained ML agent107is configured to control the one or more ML agent-controlled game entities105to achieve one or more goals or subgoals. The behavior of the ML agent-controlled game entities105in the video game environment can be automatically monitored or otherwise observed by the user to validate that the video game plays as intended. For example, the computing system101may automatically validate the video game environment by determining whether any errors (e.g. as determined by the game engine103) were generated as the ML agent-controlled game entities105interact in the video game environment. Trajectories of actions performed by the ML agent-controlled game entities105leading to errors may be surfaced to the user (e.g. by replay/visualization of the actions performed by the ML agent-controlled entity105in the trajectory), enabling the user to easily assess any mistakes/bugs (e.g. an ML agent-controlled game entity105moving through a wall or unseen gap in the video game environment) in the design of the video game environment. As another example, if a goal (or subgoal) has not been achieved by the ML agent-controlled game entities105in a trajectory within a threshold amount of time, the trajectory of the actions performed by the ML agent-controlled game entities105may be surfaced to the user. As another example, the user can observe the behavior of ML agent-controlled game entities105as they interact with the video game environment in real-time.
The user may provide one or more corrected demonstrations in response to the validation, which may be used to update/retrain the trained ML agent107. Alternatively or additionally, the user may make changes using the video game environment designer106to the video game environment in response to the validation, where the user identifies mistakes/bugs experienced by an ML agent-controlled game entity105within the design of the video game environment. For example, it may be determined that ML agent-controlled game entities105face difficulty in navigating a certain region of the video game environment. The user may then provide corrected demonstrations of the user controlling the game entity105in the region which are recorded by the demonstration recorder110to generate one or more corrected training examples112. As another example, the user may further modify the video game environment using the video game environment designer106in response to identifying mistakes/bugs/errors within the video game environment based on the difficulties faced by an ML agent-controlled game entity105navigating or interacting within the certain region of the video game environment. As a further example, the user may modify the video game environment using the video game environment designer106such that the video game environment is different to the one that the ML agent107was initially trained to interact within. In some cases (e.g. for minor changes to the video game environment) the ML agent107may generalize well enough to interact successfully (e.g. to achieve a certain goal) within the modified video game environment, thus requiring no retraining of the ML agent107. In other cases, the ML agent107may benefit from retraining using corrected demonstrations of the user controlling the game entities105in the modified video game environment. Similarly, corrected training examples112can be generated from the corrected demonstrations in the modified video game environment.
Corrected training examples112can be used in addition to the initial training examples in for further training the ML agent107, allowing users to easily modify the behavior of ML agent-controlled game entities105by providing a small number of corrected demonstrations.
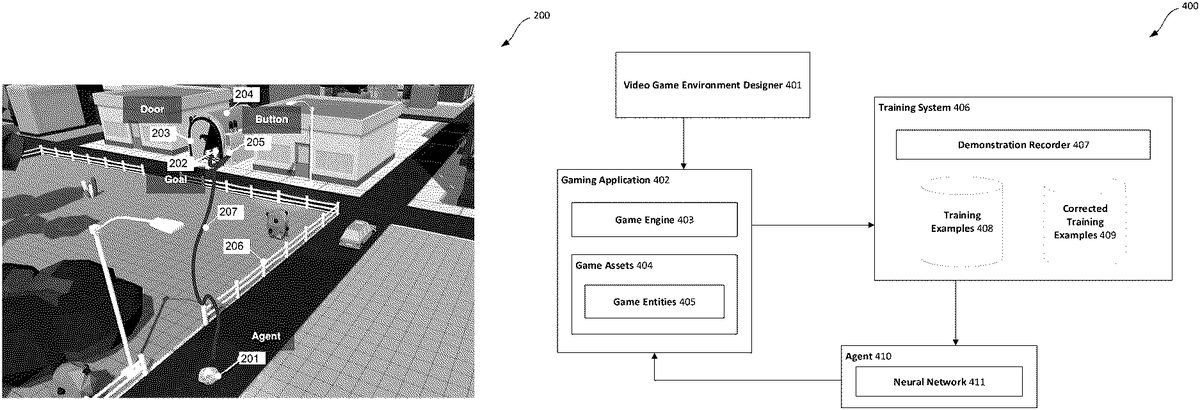
FIG.2illustrates an example video game environment200. As shown in the example video game environment200, an agent is controlling a video game entity201to interact in the video game environment200to reach a goal location202. In this example, the agent is a computer-controlled agent such as an ML agent and is configured and/or trained based on the imitation learning techniques, methods and/or processes as described with reference toFIGS.1and/orFIGS.3to5. The goal location202being behind a closed door203of a round roofed building204that may be opened via a button205. In this example, navigating to the goal location202requires avoiding obstacles (e.g. the fences206), reaching the location of the button205, and interacting with the button205to open the door203so that the game entity201can reach the goal location202behind the door203of the round roofed building204. The trajectory of the game entity201controlled by the ML agent is illustrated as the dark path207from the game entity201to the goal location202.
As the ML agent controls the game entity201to interact in the video game environment200, the ML agent continually obtains information about the current state of the video game environment200. This includes the position of the ML agent-controlled game entity201in the video game environment200, and the position of other game entities or assets such as, without limitation, for example the button205and the door203and/or round roofed building204. Positions of game entities may be represented in absolute terms, e.g. the absolute position of the game entity201within the video game environment200, or in relative terms, e.g. the relative position of the game entity201with respect to the goal position. Other attributes of the ML agent-controlled game entity201may also be obtained, e.g. an indication as to whether the game entity201is grounded, whether it can jump, etc. Other attributes for the other game entities may also be obtained, e.g. an indication as to whether the button205has been pressed or not. The obtained information also includes a semantic representation of a region of the video game environment200comprising the ML agent-controlled game entity201. The obtained information is processed by the ML agent to generate an action for controlling the game entity201to perform in a subsequent time step. In this example, a generated action may to be move in a certain direction, to run, to jump, or to press the button205.
It will be appreciated thatFIG.2illustrates just one example of a video game environment200, and that the systems and methods described herein can be used to perform automated validation of any suitable video game. Furthermore, whileFIG.2depicts a goal202as a particular location or building204in the video game environment for the ML agent-controlled game entity201to reach, it will be appreciated that a goal may be defined as any suitable state of the video game environment. For example, in a shooter video game, a goal for an ML agent-controlled game entity to achieve may be to shoot an enemy game entity. In a sports video game, a goal for an ML agent-controlled game entity to achieve may be to win a match. The goal may be a timed goal, i.e. the ML agent-controlled game entity201may be required to reach the goal or achieve the goal within a period of time or within a minimum time.
FIG.3is a schematic block diagram illustrating an example300of a neural network301for a computer-controlled agent such as an ML agent when used in performing automated playtesting/validation of video game environments.
The neural network301receives an input comprising entity data302for a game entity controllable by the ML agent, entity data303-1,303-2,303-N for N other game entities, and a segmented map304. The input reflects the state of the video game environment at a particular time.
The entity data302for the ML agent-controllable game entity comprises a representation of a state of the ML agent-controllable game entity with respect to the goal. For example, a goal for the ML agent-controllable game entity to achieve may be to reach a goal location in the video game environment. In this example, the entity data302may comprise a representation of the position of the ML agent-controllable game entity with respect to the goal location. For example, the entity data302may specify the relative position of the ML agent-controllable game entity in relation to the goal location. This may be achieved by performing one or more projections of the position vector between the position of the ML agent-controllable game entity and the goal location onto respective planes. For example, the position vector may be projected into the XY-plane and the XZ-plane, e.g. if the video game environment is a three-dimensional environment. The lengths of the projected vectors may be normalized, e.g. based on the area of the video game environment, and the normalized lengths may be used to specify the relative position in the entity data302. Entity data303-1,303-2,303-N for other game entities may also each specify the relative position of the respective game entity with respect to the goal location in a similar manner. For other kinds of goals, the entity data302may comprise an indicator indicating whether the goal has been achieved to represent the state of the ML agent-controllable game entity with respect to the goal. More generally, any suitable state of the video game environment may be a goal for the ML agent-controllable game entity to achieve (e.g. to shoot an enemy in a shooter video game, to score a goal in a sports video game, etc.).
The entity data302may further comprise non-goal related information/attributes about the agent-controllable game entity. For example, the entity data302may specify whether the game entity has possession of particular game item(s) (e.g. a key if needed to unlock a door), a status of the game entity (e.g. if the game entity is grounded, if the game entity can jump, a health status, etc.), a position of the game entity in the video game environment, and any other data which may be relevant for gameplay. The entity data302may comprise an indication of a particular playstyle/persona corresponding to a desired playstyle/persona for the agent-controllable game entity. The entity data302may be represented as a vector.
The input to the neural network301comprises entity data303-1,303-2,303-N for N other game entities. The other game entities are game entities that may be useful for the ML agent to be aware of when controlling the agent-controllable game entity. The other game entities may include intermediate goals, dynamic objects, enemies, and other game entities that could be used for achieving the final goal. The number of other game entities, N, for which entity data303is received may differ between different inputs to the neural network301. In other words, the neural network301may be configured to process entity data303associated with a variable number of other game entities. The entity data303comprises information/attributes about the game entity. For example, the entity data303may specify a status of the game entity (e.g. if the game entity is grounded, if the game entity can jump, a health status, etc.), a position of the game entity in the video game environment, and any other data which may be relevant for gameplay. As mentioned above, the entity data303-1,303-2,303-N may each specify the relative position of the respective game entity with respect to a goal location. Each of the entity data303may be represented as a vector.
The segmented map304is a representation of an area/region of the video game environment comprising the ML agent-controllable game entity. The segmented map304is segmented according to the characteristics of subregions of the region. Such a segmented map may be referred to as a semantic map, as the map encodes information about the region. The segmented map may be integer-encoded, e.g. a different integer may represent a different characteristic of subregions. For example, the segmented map304may distinguish between obstacles and unobstructed areas by representing unobstructed areas with a particular value, and obstacles with another value. The region represented by the segmented map304may be gridded and the segmented map304may indicate characteristics of the video game environment at each grid position. The segmented map304may be two-dimensional (e.g. for a platformer video game) and the segmented map304may be represented as a matrix. The matrix may represent subregions of the region that share characteristics/that are of the same type using the same value (e.g. a same integer). Alternatively, the segmented map304may be three-dimensional (e.g. for an action-adventure video game) and the segmented map304may be represented as a tensor. The tensor may represent subregions of the region that share characteristics/that are of the same type using the same value (e.g. a same integer). Any suitable number of different subregion types may be represented in the segmented map304.
The neural network301comprises an entity data processing portion305configured to process entity data302associated with the ML agent-controllable game entity. The entity data processing portion305comprises one or more neural network layers, each neural network layer associated with a set of parameters/weights. As depicted inFIG.3, the entity data processing portion305comprises one or more fully connected layers. The entity data processing portion305may comprise additional neural network layers, such as convolutional layers, Transformer layers, etc. The entity data processing portion305processes the entity data302in accordance with the neural network layers and respective parameters, and produces a vector/embedding representing the entity data302.
The neural network301comprises an “other entity” data processing portion306configured to process entity data303associated with other game entities. The other entity data processing portion306comprises one or more neural network layers, each neural network layer associated with a set of parameters/weights. As depicted inFIG.3, the other entity data processing portion306comprises one or more fully connected layers. The other entity data processing portion306may comprise additional neural network layers, such as convolutional layers, Transformer layers, etc. The other entity data processing portion306processes each entity data303in accordance with the neural network layers and respective parameters, and produces a respective vector/embedding representing the corresponding entity data303. The other entity data processing portion306may process the entity data303-1,303-2,303-N at the same time, e.g. by forming a matrix from the entity data303-1,303-2,303-N and processing the matrix. The other entity data processing portion306may process the entity data303in parallel with the entity data processing portion305processing the entity data302.
The neural network301comprises a segmented map processing portion307configured to process segmented maps304. The segmented map processing portion307comprises one or more neural network layers, each neural network layer associated with a set of parameters/weights. As depicted inFIG.3, the segmented map processing portion307comprises one or more convolutional layers. The convolutional layer(s) may be configured to perform 3D convolution and/or 2D convolution, e.g. depending on the whether the segmented map304is three-dimensional or two-dimensional. The segmented map processing portion307may comprise additional neural network layers, such as fully connected layers, pooling layers, Transformer layers, etc. The segmented map processing portion307processes the segmented map304in accordance with the neural network layers and respective parameters, and produces a vector/embedding representing the segmented map304. The segmented map processing portion307may process the segmented map304in parallel with the entity data processing portion305processing the entity data302and the other entity data processing portion306processing the entity data303.
The neural network301comprises an attention mechanism308. The attention mechanism308receives inputs formed from combining vectors/embeddings produced by the entity data processing portion305with vectors/embeddings produced by the other entity data processing portion306. For example, N combined entity embeddings may be produced from combining the entity embedding produced by the entity data processing portion305with each of the N other entity embeddings produced by the other entity data processing portion306. Any suitable combining operation may be used to form the combined entity embeddings, e.g. concatenation, addition, etc. The attention mechanism308comprises one or more neural network layers, e.g. fully-connected layers, Transformer layers (e.g. Transformer encoder blocks), pooling layers etc. The attention mechanism308is configured to process the N combined entity embeddings to produce a single combined embedding representing the N combined entity embeddings.
The neural network301comprises an output portion309. The output portion309is configured to receive an input formed from combining the single combined embedding produced by the attention mechanism308with the segmented map embedding produced by the segmented map processing portion307. Any suitable combining operation may be used, e.g. concatenation, addition, etc. The output portion309comprises one or more neural network layers, each neural network layer associated with a set of parameters/weights. As depicted inFIG.3, the output portion309comprises one or more fully connected layers. The output portion309may comprise additional neural network layers, such as convolutional layers, pooling layers, Transformer layers etc. The output portion309processes the input formed from combining the single combined embedding with the segmented map embedding and produces an output from which an ML agent action310(or actions) can be obtained.
The output generated by the output portion309may be a vector of scores/probabilities for various one or more actions that the ML agent-controllable game entity can perform. The vector may specify a score for each of a plurality of discrete actions. For example, a score for a move left action, a score for a move forward action, a score for a jump action etc. One or more ML agent actions310may be selected based on the output scores, for example the highest-scoring action(s) may be selected as the ML agent action310. It may be possible for the ML agent-controllable game entity to perform multiple actions at the same time (e.g. move right and jump), and multiple actions may be selected as the ML agent action310based on the output scores. For example, if the scores for two actions capable of being performed at the same time or concurrently are each greater than a threshold value, the two actions may be selected as the ML agent action310. Although an ML agent action310may include two or more actions that are to be performed by the ML agent-controllable game entity, the two or more actions may be performed by the ML agent-controllable game entity simultaneously, serially, concurrently and/or at least partially concurrently prior to the ML agent receiving further input for generating a further ML agent action310. For example, once the ML agent action310is output with two or more actions, each of the two or more actions of the ML agent action310may be performable by the ML agent-controllable game entity at the same or different time instances to other of the two or more actions and complete at the same or different time instances of the other of the two or more actions, as well, when performed simultaneously, concurrently or at least partially concurrently, the two or more actions may overlap in time.
FIG.4illustrates an example method400of performing automated playtesting of video game environments.FIG.4refers to various components of the system101described in relation toFIG.1.
Video game environment designer401used for designing the video game environment. The video game environment designer component401may be an application that can be used by game designers and/or may be a component of the gaming application402that can be used/accessed by players of the video game. The video game environment designer component401configures the game engine403and/or game assets404based on received user inputs.
The training system406receives one or more demonstrations of a user/player controlling a game entity405in the video game environment, generates training examples408from the one or more user demonstrations, and trains an agent410by updating parameters of the neural network411of the agent410using the training examples408. As an example, the neural network411may be based on the neural network301described with reference toFIG.3. The agent410may be a computer-controlled agent such as an ML agent and the like.
During each demonstration provided by the user, the demonstration recorder407continually (e.g. periodically, such as before the rendering of each video frame, multiple frames, etc.) obtains data relating to the state of the video game environment at the current time step and associates this with actions performed by the user at a subsequent time step (e.g. the time step immediately following the current time step).
The data relating to the state of the video game environment at the current time step is used to form a training input of a training example408and the actions performed by the user at the subsequent time step is used to form the target output for the training example408. The demonstration recorder407may process the data relating to the state of the video game environment at the current time step to form a training input that is suitable for input and subsequent processing by the neural network411. Similarly, the demonstration recorder407may process the action(s) performed by the user at the subsequent time step to form a target output that is suitable for training the neural network411. For example, the target output may be represented as a vector indicating the action(s) performed by the user at the subsequent time step(s).
For each training example408, the neural network411of the agent410processes the training input of the training example408and produces a training output. The training output represents a prediction for which action(s) the agent410should perform in the state of the video game environment corresponding to the training input. The training system406trains the neural network411of the agent410by updating parameters of the neural network411to optimize an objective function. For example, the training system406may update parameters of the neural network411to optimize a cross-entropy loss function, a least-squares loss function, or any other suitable loss function and combinations thereof. In general, updating parameters of the neural network411to optimize an objective function minimizes differences (or errors) between training outputs generated by the neural network411from processing training examples408and the corresponding target outputs of the training examples408. The parameters of the neural network411may be updated by optimizing the objective function using any suitable optimization procedure. For example, the objective function may be optimized using gradient-based methods such as stochastic gradient descent, mini-batch gradient descent, or batch gradient descent, including momentum-based methods such as Adam, RMSProp, and AdaGrad.
After training the agent410by updating parameters of the neural network411using one or more training examples408, validation of the video game environment is performed using the trained agent410. The trained agent410controls one or more game entities405for which it was trained to control by continually processing inputs relating to the current state of the video game environment and generating actions for the one or more agent-controlled game entities405to perform in a subsequent time step for use in controlling the one or more agent-controlled game entities405in achieving their corresponding goals. The behavior of the agent-controlled game entities405in the video game environment can be automatically monitored or otherwise observed by the user to validate that the video game plays as intended. For example, the computing system101may automatically validate the video game environment by determining whether any errors (e.g. as determined by the game engine403) were generated as the agent-controlled game entities405interact in the video game environment. Trajectories of actions performed by the agent-controlled game entities405leading to errors may be surfaced to the user (e.g. by replay/visualization of the actions performed by the agent-controlled entity405in the trajectory), enabling the user to easily assess any mistakes/bugs in the design of the video game environment. As another example, if a goal has not been achieved by the agent-controlled game entities405in a trajectory within a threshold amount of time, the trajectory of the actions performed by the agent-controlled game entities405may be surfaced to the user. As another example, the user can observe the behavior of agent-controlled game entities405as they interact with the video game environment in real-time.
The user may provide one or more corrected demonstrations in response to the validation. For example, it may be determined that agent-controlled game entities405face difficulty in navigating a certain region of the video game environment. The user may then provide corrected demonstrations of the user controlling the game entity405in the region which are recorded by the demonstration recorder407to generate one or more corrected training examples409. As another example, the user may modify the video game environment using the video game environment designer401such that the video game environment is different to the one that the agent410was initially trained to interact within. In some cases (e.g. for minor changes to the video game environment) the agent410may generalize well enough to interact successfully (e.g. to achieve a certain goal) within the modified video game environment, thus requiring no retraining of the agent410. In other cases, the agent410may benefit from retraining using corrected demonstrations of the user controlling the game entities405in the modified video game environment. Similarly, corrected training examples409can be generated from the corrected demonstrations in the modified video game environment. In this way, the corrected training examples may be used to correct mistakes in the behavior of the initially trained agent.
Corrected training examples409can be used in addition to the initial training examples408to further train the agent410using a similar process to the initial training process described above, allowing users to easily modify the behavior of agent-controlled game entities405by providing a small number of corrected demonstrations. For example, the training examples408and corrected training examples409may be aggregated to form an aggregated training set, and the training examples of the aggregated training set may be used to further update the parameters of the neural network411when updating the agent410.
FIG.5is a flow diagram illustrating an example method500for performing validation of a video game environment.
In step5.1, one or more demonstrations of a video game entity interacting with the video game environment to achieve a goal are provided by a user. Each of the demonstrations specify one or more actions performed by the video game entity in the video game environment at each of one or more time steps.
In step5.2, one or more training examples are generated from the one or more demonstrations. Each training example is associated with a time step of a demonstration and comprises: (i) a segmented map of an area of the video game environment comprising the video game entity, (ii) entity data for the video game entity, wherein the entity data comprises a representation of a state of the video game entity with respect to the goal, (iii) entity data for each of one or more other video game entities in the video game environment, and (iv) one or more target actions performed by the video game entity for the time step of the training example. The segmented map and entity data represent a state of the video game environment at a time step prior to the time step at which the target actions were performed by the video game entity. The entity data may comprise relative co-ordinate data based on the position of the video game entity in the video game environment and the position of a location corresponding to the goal. The entity data may further comprise attribute information for the video game entity.
In step5.3, an agent is trained to control the video game entity using a neural network. The agent may be a computer-controlled agent such as a ML agent (e.g. a computer-controlled agent including ML functionality configured for training and learning to operate/control one or more game entities autonomously without input from a user). For each training example, one or more predicted actions for the training example are generated by processing, using the neural network, input data derived from the training example. Parameters of the neural network are updated based on a comparison between the one or more predicted actions of the training examples and the one or more corresponding target actions of the training examples.
The neural network may comprise a segmented map processing portion, an entity data processing portion, and a further entity data processing portion. Processing, using the neural network, input data derived from the training example may comprise: processing the segmented map using the segmented map processing portion to generate a segmented map embedding; processing the entity data for the video game entity using the entity data processing portion to generate an entity embedding; processing, for each of the one or more other video game entities, the entity data for the other video game entity to generate another entity embedding; combining, for each other entity embedding, the other entity embedding with the entity embedding to generate a combined entity embedding; and processing the one or more combined entity embeddings and the segmented map embedding to generate an output representing one or more predicted actions for the training example.
Processing the one or more combined entity embeddings and the segmented map embedding to generate the output representing one or more predicted actions for the training example may comprise: processing the one or more combined entity embeddings using an attention mechanism of the neural network to generate a single combined embedding; and processing a combination of the single combined embedding and the segmented map embedding using an output portion of the neural network to generate the output.
Processing the one or more combined entity embeddings using the attention mechanism of the neural network to generate a single combined embedding may comprise processing the one or more combined entity embeddings using one or more Transformer encoder layers of the neural network. For example, the attention mechanism may comprise one or more Transformer encoder blocks. Each of the Transformer encoder blocks may be configured to perform multi-head self-attention on sequences derived from the one or more combined entity embeddings.
The input data derived from a training example may comprise: (i) the segmented map of an area of the video game environment comprising the video game entity, (ii) the entity data for the video game entity, and (iii) the entity data for each of one or more other video game entities in the video game environment.
The segmented map of each training example may comprise a three-dimensional integer-coded representation of the area of the video game environment comprising the video game entity. The neural network may comprise a segmented map processing portion comprising one or more three-dimensional convolutional neural network layers.
In step5.4, validation of the video game environment is performed. This comprises controlling the video game entity in the video game environment using the trained agent. Performing validation of the video game environment may comprise providing, by the user, one or more corrected demonstrations in response to the agent controlling the video game entity in the video game environment using the updated neural network. The agent may be further trained to control the video game entity using the one or more training examples and one or more corrected training examples generated from the one or more corrected demonstrations. This may comprise further updating parameters of the neural network.
Performing validation of the video game environment may comprise providing, by the user, a modification to the video game environment. One or more corrected demonstrations may be provided by the user in response to the agent controlling the video game entity in the modified video game environment using the updated neural network. The agent may be further trained to control the video game entity using the one or more training examples and one or more corrected training examples generated from the one or more corrected demonstrations, comprising further updating parameters of the neural network.
FIG.6shows a schematic example of a system/apparatus for performing any of the methods described herein. The system/apparatus shown is an example of a computing device. It will be appreciated by the skilled person that other types of computing devices/systems may alternatively be used to implement the methods described herein, such as a distributed computing system.
The apparatus (or system)600comprises one or more processors602. The one or more processors control operation of other components of the system/apparatus600. The one or more processors602may, for example, comprise a general purpose processor. The one or more processors602may be a single core device or a multiple core device. The one or more processors602may comprise a central processing unit (CPU) or a graphical processing unit (GPU). Alternatively, the one or more processors602may comprise specialised processing hardware, for instance a RISC processor or programmable hardware with embedded firmware. Multiple processors may be included.
The system/apparatus comprises a working or volatile memory604. The one or more processors may access the volatile memory604in order to process data and may control the storage of data in memory. The volatile memory604may comprise RAM of any type, for example Static RAM (SRAM), Dynamic RAM (DRAM), or it may comprise Flash memory, such as an SD-Card.
The system/apparatus comprises a non-volatile memory606. The non-volatile memory606stores a set of operation instructions608for controlling the operation of the processors602in the form of computer readable instructions. The non-volatile memory606may be a memory of any kind such as a Read Only Memory (ROM), a Flash memory or a magnetic drive memory.
The one or more processors602are configured to execute operating instructions608to cause the system/apparatus to perform any of the methods described herein. The operating instructions608may comprise code (i.e. drivers) relating to the hardware components of the system/apparatus600, as well as code relating to the basic operation of the system/apparatus600. Generally speaking, the one or more processors602execute one or more instructions of the operating instructions608, which are stored permanently or semi-permanently in the non-volatile memory606, using the volatile memory604to temporarily store data generated during execution of said operating instructions608.
Implementations of the methods, apparatus and/or systems as described herein may be realised as in digital electronic circuitry, integrated circuitry, specially designed ASICs (application specific integrated circuits), system-on-chip (SoC) integrated circuitry, computer hardware, firmware, software, and/or combinations thereof. These may include computer program products (such as software stored on e.g. magnetic discs, optical disks, memory, Programmable Logic Devices) comprising computer readable instructions that, when executed by a computer, such as that described in relation toFIG.6, cause the computer to perform one or more of the methods described herein.
Implementations of the methods, apparatus and/or systems as described herein may be realised as one or more servers, a plurality of servers and/or computing devices, a distributed system, a cloud-based platform and/or cloud computing system and the like. Thus, for instance, several computing devices and/or servers may be in communication by way of a network connection and may collectively perform tasks described as being performed by the methods, apparatus, computing devices, and/or systems as described herein.
Any system feature as described herein may also be provided as a method feature, and vice versa. As used herein, means plus function features may be expressed alternatively in terms of their corresponding structure. In particular, method aspects may be applied to system aspects, and vice versa.
Furthermore, any, some and/or all features in one aspect can be applied to any, some and/or all features in any other aspect, in any appropriate combination. It should also be appreciated that particular combinations of the various features described and defined in any aspects of the invention can be implemented and/or supplied and/or used independently.
Although several embodiments have been shown and described, it would be appreciated by those skilled in the art that changes may be made in these embodiments without departing from the principles of this disclosure, the scope of which is defined in the claims.
It should be understood that the original applicant herein determines which technologies to use and/or productize based on their usefulness and relevance in a constantly evolving field, and what is best for it and its players and users. Accordingly, it may be the case that the systems and methods described herein have not yet been and/or will not later be used and/or productized by the original applicant. It should also be understood that implementation and use, if any, by the original applicant, of the systems and methods described herein are performed in accordance with its privacy policies. These policies are intended to respect and prioritize player privacy, and to meet or exceed government and legal requirements of respective jurisdictions. To the extent that such an implementation or use of these systems and methods enables or requires processing of user personal information, such processing is performed (i) as outlined in the privacy policies; (ii) pursuant to a valid legal mechanism, including but not limited to providing adequate notice or where required, obtaining the consent of the respective user; and (iii) in accordance with the player or user's privacy settings or preferences. It should also be understood that the original applicant intends that the systems and methods described herein, if implemented or used by other entities, be in compliance with privacy policies and practices that are consistent with its objective to respect players and user privacy.
Claims
- A computer-implemented method comprising: providing, by a user, one or more demonstrations of a video game entity interacting with a video game environment to achieve a goal, each of the demonstrations specifying one or more actions performed by the video game entity in the video game environment at each of one or more time steps;generating, from the one or more demonstrations, one or more training examples, each training example associated with a time step of a demonstration and comprising: (i) a segmented map of an area of the video game environment comprising the video game entity, (ii) entity data for the video game entity, wherein the entity data comprises a representation of a state of the video game entity with respect to the goal, (iii) entity data for each of one or more other video game entities in the video game environment, and (iv) one or more target actions performed by the video game entity for the time step of the training example;training an agent to control the video game entity using a neural network, comprising: generating, for each training example, one or more predicted actions for the training example by processing, using the neural network, input data derived from the training example, wherein the segmented map of each training example comprises an integer-coded representation of the area of the video game environment comprising the video game entity, and the neural network comprises a segmented map processing portion comprising one or more convolutional neural network layers;and updating parameters of the neural network based on a comparison between the one or more predicted actions of the training examples and the one or more corresponding target actions of the training examples;and performing validation of the video game environment, comprising controlling the video game entity in the video game environment using the trained agent.
- The method of claim 1, wherein performing validation of the video game environment comprises: providing, by the user, one or more corrected demonstrations in response to the agent controlling the video game entity in the video game environment using the updated neural network;and further training the agent to control the video game entity using the one or more training examples and one or more corrected training examples generated from the one or more corrected demonstrations, comprising further updating parameters of the neural network.
- The method of claim 1, wherein performing validation of the video game environment comprises: providing, by the user, a modification to the video game environment;providing, by the user, one or more corrected demonstrations in response to the agent controlling the video game entity in the modified video game environment using the updated neural network;and further training the agent to control the video game entity using the one or more training examples and one or more corrected training examples generated from the one or more corrected demonstrations, comprising further updating parameters of the neural network.
- The method of claim 1, wherein the input data derived from a training example comprises: (i) the segmented map of an area of the video game environment comprising the video game entity, (ii) the entity data for the video game entity, and (iii) the entity data for each of one or more other video game entities in the video game environment.
- The method of claim 4, wherein the neural network comprises a segmented map processing portion, an entity data processing portion, and a further entity data processing portion, and wherein processing, using the neural network, input data derived from the training example comprises: processing the segmented map using the segmented map processing portion to generate a segmented map embedding;processing the entity data for the video game entity using the entity data processing portion to generate an entity embedding;processing, for each of the one or more other video game entities, the entity data for the other video game entity to generate another entity embedding;combining, for each other entity embedding, the other entity embedding with the entity embedding to generate a combined entity embedding;and processing the one or more combined entity embeddings and the segmented map embedding to generate an output representing one or more predicted actions for the training example.
- The method of claim 5, wherein processing the one or more combined entity embeddings and the segmented map embedding to generate the output representing one or more predicted actions for the training example comprises: processing the one or more combined entity embeddings using an attention mechanism of the neural network to generate a single combined embedding;and processing a combination of the single combined embedding and the segmented map embedding using an output portion of the neural network to generate the output.
- The method of claim 6, wherein processing the one or more combined entity embeddings using the attention mechanism of the neural network to generate a single combined embedding comprises processing the one or more combined entity embeddings using one or more transformer encoder layers of the neural network.
- The method of claim 1, wherein the integer-coded representation of the area of the video game environment comprising the video game entity is a two-dimensional integer coded representation or a three-dimensional integer-coded representation, and the one or more convolutional neural network layers are one or more two-dimensional convolutional neural network layers or one or more three-dimensional convolutional neural network layers, respectively.
- The method of claim 1, wherein the entity data comprises relative co-ordinate data based on the position of the video game entity in the video game environment and the position of a location corresponding to the goal.
- The method of claim 1, wherein the entity data further comprises attribute information for the video game entity.
- A computing system comprising one or more computing devices configured to: receive, from a user, one or more demonstrations of a video game entity interacting with a video game environment to achieve a goal, each of the demonstrations specifying one or more actions performed by the video game entity in the video game environment at each of one or more time steps;generate, from the one or more demonstrations, one or more training examples, each training example associated with a time step of a demonstration and comprising: (i) a segmented map of an area of the video game environment comprising the video game entity, (ii) entity data for the video game entity, wherein the entity data comprises a representation of a state of the video game entity with respect to the goal, (iii) entity data for each of one or more other video game entities in the video game environment, and (iv) one or more target actions performed by the video game entity for the time step of the training example;train an agent to control the video game entity using a neural network, comprising: generating, for each training example, one or more predicted actions for the training example by processing, using the neural network, input data derived from the training example, wherein the segmented map of each training example comprises an integer-coded representation of the area of the video game environment comprising the video game entity, and the neural network comprises a segmented map processing portion comprising one or more convolutional neural network layers;and updating parameters of the neural network based on a comparison between the one or more predicted actions of the training examples and the one or more corresponding target actions of the training examples;and perform validation of the video game environment, comprising controlling the video game entity in the video game environment using the trained agent.
- The computing system of claim 11, wherein performing validation of the video game environment comprises: providing, by the user, one or more corrected demonstrations in response to the agent controlling the video game entity in the video game environment using the updated neural network;and further training the agent to control the video game entity using the one or more training examples and one or more corrected training examples generated from the one or more corrected demonstrations, comprising further updating parameters of the neural network.
- The computing system of claim 11, wherein performing validation of the video game environment comprises: providing, by the user, a modification to the video game environment;providing, by the user, one or more corrected demonstrations in response to the agent controlling the video game entity in the modified video game environment using the updated neural network;and further training the agent to control the video game entity using the one or more training examples and one or more corrected training examples generated from the one or more corrected demonstrations, comprising further updating parameters of the neural network.
- The computing system of claim 11, wherein the input data derived from a training example comprises: (i) the segmented map of an area of the video game environment comprising the video game entity, (ii) the entity data for the video game entity, and (iii) the entity data for each of one or more other video game entities in the video game environment.
- The computing system of claim 14, wherein the neural network comprises a segmented map processing portion, an entity data processing portion, and a further entity data processing portion, and wherein processing, using the neural network, input data derived from the training example comprises: processing the segmented map using the segmented map processing portion to generate a segmented map embedding;processing the entity data for the video game entity using the entity data processing portion to generate an entity embedding;processing, for each of the one or more other video game entities, the entity data for the other video game entity to generate another entity embedding;combining, for each other entity embedding, the other entity embedding with the entity embedding to generate a combined entity embedding;and processing the one or more combined entity embeddings and the segmented map embedding to generate an output representing one or more predicted actions for the training example.
- A non-transitory computer-readable medium, which when executed by a processor, cause the processor to: receive, from a user, one or more demonstrations of a video game entity interacting with a video game environment to achieve a goal, each of the demonstrations specifying one or more actions performed by the video game entity in the video game environment at each of one or more time steps;generate, from the one or more demonstrations, one or more training examples, each training example associated with a time step of a demonstration and comprising: (i) a segmented map of an area of the video game environment comprising the video game entity, (ii) entity data for the video game entity, wherein the entity data comprises a representation of a state of the video game entity with respect to the goal, (iii) entity data for each of one or more other video game entities in the video game environment, and (iv) one or more target actions performed by the video game entity for the time step of the training example;train an agent to control the video game entity using a neural network, comprising: generating, for each training example, one or more predicted actions for the training example by processing, using the neural network, input data derived from the training example, wherein the segmented map of each training example comprises an integer-coded representation of the area of the video game environment comprising the video game entity, and the neural network comprises a segmented map processing portion comprising one or more convolutional neural network layers;and updating parameters of the neural network based on a comparison between the one or more predicted actions of the training examples and the one or more corresponding target actions of the training examples;and perform validation of the video game environment, comprising controlling the video game entity in the video game environment using the trained agent.
- The non-transitory computer-readable medium of claim 16, wherein performing validation of the video game environment comprises: providing, by the user, one or more corrected demonstrations in response to the agent controlling the video game entity in the video game environment using the updated neural network;and further training the agent to control the video game entity using the one or more training examples and one or more corrected training examples generated from the one or more corrected demonstrations, comprising further updating parameters of the neural network.
- The non-transitory computer-readable medium of claim 16, wherein performing validation of the video game environment comprises: providing, by the user, a modification to the video game environment;providing, by the user, one or more corrected demonstrations in response to the agent controlling the video game entity in the modified video game environment using the updated neural network;and further training the agent to control the video game entity using the one or more training examples and one or more corrected training examples generated from the one or more corrected demonstrations, comprising further updating parameters of the neural network.
- The non-transitory computer-readable medium of claim 16, wherein the input data derived from a training example comprises: (i) the segmented map of an area of the video game environment comprising the video game entity, (ii) the entity data for the video game entity, and (iii) the entity data for each of one or more other video game entities in the video game environment.
- The non-transitory computer-readable medium of claim 16, wherein the neural network comprises a segmented map processing portion, an entity data processing portion, and a further entity data processing portion, and wherein processing, using the neural network, input data derived from the training example comprises: processing the segmented map using the segmented map processing portion to generate a segmented map embedding;processing the entity data for the video game entity using the entity data processing portion to generate an entity embedding;processing, for each of the one or more other video game entities, the entity data for the other video game entity to generate another entity embedding;combining, for each other entity embedding, the other entity embedding with the entity embedding to generate a combined entity embedding;and processing the one or more combined entity embeddings and the segmented map embedding to generate an output representing one or more predicted actions for the training example.
Disclaimer: Data collected from the USPTO and may be malformed, incomplete, and/or otherwise inaccurate.