U.S. Pat. No. 12,296,265
Speech Prosody Prediction in Video Games
AssigneeELECTRONIC ARTS INC.
Issue DateJanuary 9, 2024
Illustrative Figure
Abstract
This specification describes a computer-implemented method of generating context-dependent speech audio in a video game. The method comprises obtaining contextual information relating to a state of the video game. The contextual information is inputted into a prosody prediction module. The prosody prediction module comprises a trained machine learning model which is configured to generate predicted prosodic features based on the contextual information. Input data comprising the predicted prosodic features and speech content data associated with the state of the video game is inputted into a speech audio generation module. An encoded representation of the speech content data dependent on the predicted prosodic features is generated using one or more encoders of the speech audio generation module. Context-dependent speech audio is generated, based on the encoded representation, using a decoder of the speech audio generation module.
Description
DETAILED DESCRIPTION General Definitions The following terms are defined to aid the present disclosure and not limit the scope thereof. A “user” or “player”, as used in some embodiments herein, refers to an individual and/or the computing system(s) or device(s) corresponding to (e.g., associated with, operated by) that individual. A “client”, as used in some embodiments described herein, is a software application with which a user interacts, and which can be executed on a computing system or device locally, remotely, or over a cloud service. A “server” as used in some embodiments described here, is a software application configured to provide certain services to a client, e.g. content and/or functionality. A “video game” as used in some embodiments described herein, is a virtual interactive environment in which players engage. Video game environments may be facilitated through a client-server framework in which a client may connect with the server to access at least some of the content and functionality of the video game. “Speech” as used in some embodiments described herein may include sounds in the form of spoken words in any language, whether real or invented and/or other utterances including paralinguistics such as sighs, yawns, moans etc. “Speech audio” refers to audio (e.g. audio data) which includes or represents speech, and may comprise data in any suitable audio file format whether in a compressed or uncompressed format. “Text” as used in some in embodiments described herein refers to any suitable representation of characters, words or symbols that may be used to represent language and/or speech. In some cases text may be input by use of a keyboard and/or stored in memory in the form of text data. Text may comprise text data in any suitable compressed or uncompressed format, e.g. ASCII format. “Prosody” as used in some embodiments described herein ...
DETAILED DESCRIPTION
General Definitions
The following terms are defined to aid the present disclosure and not limit the scope thereof.
A “user” or “player”, as used in some embodiments herein, refers to an individual and/or the computing system(s) or device(s) corresponding to (e.g., associated with, operated by) that individual.
A “client”, as used in some embodiments described herein, is a software application with which a user interacts, and which can be executed on a computing system or device locally, remotely, or over a cloud service.
A “server” as used in some embodiments described here, is a software application configured to provide certain services to a client, e.g. content and/or functionality.
A “video game” as used in some embodiments described herein, is a virtual interactive environment in which players engage. Video game environments may be facilitated through a client-server framework in which a client may connect with the server to access at least some of the content and functionality of the video game.
“Speech” as used in some embodiments described herein may include sounds in the form of spoken words in any language, whether real or invented and/or other utterances including paralinguistics such as sighs, yawns, moans etc. “Speech audio” refers to audio (e.g. audio data) which includes or represents speech, and may comprise data in any suitable audio file format whether in a compressed or uncompressed format.
“Text” as used in some in embodiments described herein refers to any suitable representation of characters, words or symbols that may be used to represent language and/or speech. In some cases text may be input by use of a keyboard and/or stored in memory in the form of text data. Text may comprise text data in any suitable compressed or uncompressed format, e.g. ASCII format.
“Prosody” as used in some embodiments described herein refers to the way in which speech is expressed, e.g. the intonation, pitch, volume, timing (e.g. rhythm, speech rate) and/or tone of speech. It may include pronunciation aspects such as articulation or stress and/or performance aspects such as intensity/arousal or valence. In some embodiments described herein prosody may be represented by prosodic features which may be derived from pitch and/or volume contours, timing information, etc. and may be predicted using the models described herein.
A “speech audio generator” as used in some embodiments described herein, is a software module that receives an indication of an utterance (e.g. speech content data) and outputs speech audio corresponding to the indication. Various characteristics of the output speech audio may be varied by speech audio generator modules described herein, e.g. speech content, speaker identity, and speech style (for example the prosody of the output speech).
“Acoustic features” as used in some embodiments described herein may include any suitable acoustic representation of frequency, magnitude and/or phase information. For example, acoustic features may comprise linear spectrograms, log-mel-spectrograms, linear predictive coding (LPC) coefficients, Mel-Frequency Cepstral Coefficients (MFCC), log fundamental frequency (LFO), band aperiodicity (bap) or combinations thereof.
Example implementations provide systems and methods for predicting speech prosody for use in generating speech audio in a video game. The video game continually (e.g. periodically) determines contextual information relating to the state of the video game, which is input to a prosody prediction module (otherwise referred to herein as a prosody predictor) when generating speech audio. The prosody prediction module is configured to predict prosodic features given a particular context of the video game. The predicted prosodic features and speech content data associated with the state of the video game are inputted into a speech audio generation module and speech audio for the speech content represented in the speech content data is generated, in accordance with the predicted prosodic features.
In this way, systems and methods described in this specification enable expressive speech audio to be dynamically generated such that the performance of the generated speech audio matches the current context/states of the video game. This is particularly advantageous in video games where it is difficult, during the development phase of the video game, to anticipate and specifically plan for all of the potential contexts/states that may occur when the game is actually played. For example, some modern video games are unpredictable as they may involve procedural generation and/or include storylines that evolve as a result of player choices. In these (and other) video games, pre-recording speech audio that is appropriate for the potential contexts is a difficult task.
Systems and methods described in this specification may be used for real-time generation of speech audio (or faster than real-time), such that the context of the video game used to predict prosodic features is still relevant when the generated speech audio is output to a player of the video game. In this way, the performance of the generated speech audio may be responsive to real-time game events. The prosody predictor and speech audio generator may be provided on the same computing device as the video game is provided on, reducing latency when compared to other approaches of generating speech audio using models that are hosted externally on one or more separate computing devices. The speech audio generator may comprise neural networks such as transformer networks, flow-based networks or another suitable architecture which may be used to output speech audio in real-time.
Furthermore, systems and methods described herein may allow for fine-grained control of the prosody of generated speech audio. For example, the prosody predictor may be configured to output prosodic features (which are also referred to herein as prosody embeddings) for each time step of a plurality of time steps. The plurality of time steps may correspond to time steps of the speech content data, with each time step being associated with a unit of the speech content data (e.g. characters, phonemes, words). The prosodic features predicted for each time step may be used, along with the speech content data, by the speech audio generator to generate realistic and expressive speech audio for the speech content represented in the speech content data. Other characteristics of the generated speech audio, such as the speaker identity, may also be easily controlled by the methods and systems described herein.
Video games that use the methods and systems described herein may require less storage space than video games which do not. For example, the prosody predictor and speech audio generator described herein may be used instead of storing all of the pre-recorded speech audio that may be used for the many contexts/scenarios of modern video games.
Example Video Game Environment
FIG.1illustrates an example of a computer system configured to provide a video game environment100to players of a video game. The video game environment100is configured to provide expressive speech audio that is dynamically generated such that the performance of the generated speech audio matches the current context/environment of the video game. A prosody predictor107is configured to predict prosodic features given a particular (e.g. current) context of the video game. The predicted prosodic features and speech content data are inputted into a speech audio generator108and speech audio for the speech content represented in the speech content data is generated, in accordance with the predicted prosodic features.
The video game environment100includes one or more client computing devices101. Each client computing device101is operable by a user and provides a client in the form of gaming application102to the user. The client computing device101may be configured to communicate with a video game server apparatus including a game server for providing content and functionality to the gaming application102. For the sake of clarity, the video game environment100is illustrated as comprising a specific number of devices. Any of the functionality described as being performed by a specific device may instead be performed across a number of computing devices, and/or functionality described as being performed by multiple devices may be performed on a single device.
The client computing device101can be any computing device suitable for providing the gaming application102to the user. For example, the client computing device101may be any of a laptop computer, a desktop computer, a tablet computer, a video games console, or a smartphone. For displaying the graphical user interfaces of computer programs to the user, the client computing device includes or is connected to a display (not shown). Input device(s) (not shown) are also included or connected to the client. Examples of suitable input devices include keyboards, touchscreens, mice, video game controllers, microphones and cameras.
Gaming application102provides a video game to the user of the client computing device101. The gaming application102may be configured to cause the client computing device101to request video game content from a video game server apparatus while the user is playing the video game. Requests made by the gaming application102may be received at a request router of a game server, which processes the request, and returns a corresponding response to gaming application102. Examples of requests include Application Programming Interface (API) requests, e.g. a representational state transfer (REST) call, a Simple Object Access Protocol (SOAP) call, a message queue; or any other suitable request.
Gaming application102includes a game engine103. The game engine103can be configured to execute aspects of the operation of the gaming application102according to game rules. Examples of game rules can include rules for scoring, possible inputs, actions/events, movement in response to inputs, and the like. The game engine103may receive user inputs and determine in-game events, such as actions, jumps, runs, throws, attacks, and other events appropriate for the gaming application102. During runtime operation, the game engine103can read user inputs, in-game data, and game state information to determine the appropriate in-game events. Furthermore, the game engine103is configured to determine the state of the video game as it is being played. This involves determining and storing contextual information which is based on the current state of the video game. For example, in a sports video game, the contextual information may include: statistics relating to one or more teams playing in a match; statistics relating to one or more players playing in the match; statistics relating to the current status of the match; and/or the type of sport being played in the match. Contextual information (or a portion thereof) determined by game engine103is used when predicting speech prosody for a particular (e.g. current) context of the video game.
The game engine103may request generated speech audio to be provided from speech audio generator108at particular moments while the video game is being played. For example, the game engine103may determine whether one or more criteria for the context of the video game are satisfied, and cause the speech audio generator108to provide speech audio in response to determining that the one or more criteria are satisfied. As an example, in a sports video game, the game engine103may request generated speech audio after certain actions have occurred such as a goal being scored, or a particular player making a pass, etc. As another example, in an action-adventure game, the game engine103may request generated speech audio when a character controlled by the player reaches a certain destination in the virtual world of the action-adventure game. In some cases, the game engine103may determine in advance that a particular context of the video game will be reached. In these cases, the game engine103may cause the prosody predictor107to output prosodic features for the particular context. Subsequently, the prosodic features may be stored and/or used immediately for input to speech audio generator108.
The gaming application102comprises game content104accessed while the video game is being played by the player. The game content104includes speech audio105, and speech script106, and other assets such as markup-language files, scripts, images and music. The speech audio105comprises audio data for entities/characters in the video game, which may be output by the gaming application102at appropriate stages of the video game. The speech audio105(or a portion thereof) has corresponding speech scripts106which are transcriptions of the speech audio105. Additionally or alternatively, the speech scripts106may comprise indications of utterances that do not have corresponding speech audio stored as part of game content104.
The gaming application includes a prosody predictor107, and a speech audio generator108. As will be described in further detail in relation toFIG.2, as the video game is being played, the prosody predictor107receives contextual information that is based on the current context of the video game and outputs predicted prosodic features for the current context of the video game. The prosody predictor107may comprise a neural network that has been trained to predict prosodic features, based on contextual information, for use in generating speech audio.
The speech audio generator108receives the predicted prosodic features, speech content data representing speech content for the speech audio that is to be generated, and optionally, speaker identifier data, and outputs generated speech audio in accordance with these received inputs. The generated speech audio comprises a waveform of speech audio. As will be described in further detail in relation toFIG.3, the speech audio generator108may comprise a synthesizer109and a vocoder110. In these implementations, the synthesizer109may be configured to output acoustic features for speech audio, with the vocoder110transforming the acoustic features into generated speech audio. Alternatively, a synthesizer and a vocoder may be combined as a single model to form the speech audio generator108. The speech audio generator108may comprise one or more trained neural networks.
In general, trained neural networks comprise parameters that have been learned after training the neural networks on one or more tasks using training data. Example methods of training the models disclosed above are described in relation toFIGS.4,5, and6.
As depicted inFIG.1, the prosody predictor107and speech audio generator108are shown as components that are local to computing device101. This may be advantageous for reducing latency, as speech audio that is generated as the video game is being played may not need to be transmitted to computing device101over a network. However, it will be appreciated that other implementations are possible, such as the prosody predictor107and/or speech audio generator108(or components thereof) being implemented on a separate computing device (e.g. a video game server) to computing device101.
Methods and systems described herein may be used for any suitable video game. For example, the video game may be a sports video game and speech audio may be generated for an announcer in the sports video game. As another example, the video game may be an action-adventure video game, and speech audio may be generated for one or more background characters (e.g. non-playing characters).
Example Speech Audio Generator Method
FIG.2illustrates an example method200for generating speech audio207in a video game using prosodic features predicted from contextual information201that is based on a current context of the video game. The method200is performed as the video game is being played.
Contextual information201is data relating to the state of the video game. For example, in a sports video game, contextual information relating to a state of the video game may comprise determining at least one of: statistics relating to one or more teams playing in a match; statistics relating to one or more players playing in the match; statistics relating to the current status of the match; or the type of sport being played in the match. The contextual information201may comprise any combination of binary features, discrete/categorical features, and numerical features relating to a state of the video game. The contextual information201for a particular context of the video game may be represented as a vector, with binary and discrete/categorical features appropriately coded in the vector (e.g. using one hot encodings of discrete/categorical features).
The contextual information201may further comprise speech content data, and/or speaker identifier data. The speech content data represents desired speech content for the speech audio207that is to be generated, and the speaker identifier data represents the desired speaker of the speech audio207. Speech content data may be encoded into a fixed-dimension sentence embedding (e.g. by using pre-trained models which infer sentence embedding), or an average embedding may be used. The speaker identifier data may comprise a one-hot vector representing a particular speaker. Alternatively, the speaker identifier data may comprise a speaker embedding for a particular speaker. A speaker embedding is an embedding of a learned latent space such that speakers with similar voices are represented by similar speaker embeddings in the learned latent space. This embedding can be obtained from a pre-trained model that has been trained on a task such as speaker verification. It may be beneficial to include speaker identifier data in contextual information201(which is input to prosody predictor202) as prosodic features such as pitch and energy may vary between different speakers.
As described previously in relation toFIG.1, it may be determined in advance that a particular context of the video game will be reached. In these cases, contextual information201may be based on the particular context.
Prosody predictor202receives contextual information201and outputs predicted prosodic features203based on the contextual information201. The prosody predictor202may output a single prosody vector (or embedding) representing global prosodic features for the entirety of generated speech audio207. Alternatively, the prosody predictor202may output a prosody vector for each time step of one or more time steps. The time steps may correspond to time steps of speech content data204, and each prosody vector may represent fine-grained prosodic features for the respective time step.
The prosody predictor202may comprise a neural network that has been trained to predict prosodic features, based on contextual information, for use in generating speech audio. In some implementations, and as will be discussed in relation toFIG.4, the prosody predictor202may have been trained separately to speech audio generator206. In these implementations, the prosody predictor202may comprise one or more fully-connected layers and the prosody predictor202may be configured to output global prosodic features based on contextual information201. In other implementations, and as will be discussed in relation toFIG.6, the prosody predictor202may have been trained jointly with speech audio generator206. In these implementations, the prosody predictor202may comprise one or more recurrent neural network layers (e.g. LSTM layers) and the prosody predictor202may be configured to output fine-grained prosodic features.
In a neural network comprising one or more fully-connected layers, each fully connected layer receives an input and applies a learned linear transformation to its input. The fully connected layer may further apply a non-linear transformation to generate an output for the layer.
In a neural network comprising one or more recurrent layers, each recurrent layer comprises a hidden state that is updated as the recurrent neural network processes data input to the network. For each time step, recurrent layer receives its hidden state from the previous time step, and an input to the recurrent layer for the current time step. A recurrent layer processes its previous hidden state and the current input in accordance with its parameters and generates an updated hidden state for the current time step. For example, recurrent layer may apply a first linear transformation to the previous hidden state and a second linear transformation to the current input and combine the results of the two linear transformations e.g. by adding the two results together. The recurrent layer may apply a non-linear activation function (e.g. a tanh activation function, a sigmoid activation function, a ReLU activation function, etc.) to generate an updated hidden state for the current time step.
The speech content data204represents desired speech content for the speech audio207that is to be generated. The speech content data204may comprise text data. The text data may be any digital data representing text. Additionally or alternatively, the data representing speech content may comprise one or more indications of paralinguistic information. Any paralinguistic utterance may be indicated in the speech content, such as sighs, yawns, moans, laughs, grunts, etc. The speech content may be encoded by a sequence of vectors with each vector representing a character of the speech content. For example, a character may be a letter, a number, and/or a tag indicating a paralinguistic utterance. The elements of a character vector may correspond with one character out of a set of possible characters, with each character represented by a character vector with only one non-zero element (also known as a one-hot vector). Additionally or alternatively, the speech content may be represented by continuous embeddings, e.g. character embeddings and/or word embeddings. Generally, embeddings are vectors of a learned embedding space. The speech content data204may comprise phoneme information.
The speech content data204may be determined in any suitable manner. For example, it may be determined from game content (such as in speech script106ofFIG.1). As another example, a separate speech content generation system may be used to provide speech content data204.
The speaker identifier data205is any data indicating the desired speaker of the speech audio207. The speaker identifier data205may comprise a one-hot vector representing a particular speaker. Alternatively, the speaker identifier data205may comprise a speaker embedding for a particular speaker. A speaker embedding is an embedding of a learned latent space such that speakers with similar voices are represented by similar speaker embeddings in the learned latent space. This embedding can be obtained from a pre-trained model that has been trained on a task such as speaker verification.
Speech audio generator206receives the predicted prosodic features203, speech content data204, and (optionally) speaker identifier data205and outputs generated speech audio207in accordance with these received inputs. The generated speech audio207comprises a waveform of speech audio.
As will be described in relation toFIG.3, the speech audio generator206may comprise a synthesizer and a vocoder. In these implementations, the synthesizer may be configured to output acoustic features for speech audio, with the vocoder transforming the acoustic features into generated speech audio. Alternatively, a synthesizer and a vocoder may be combined as a single model to form the speech audio generator206. The speech audio generator206may comprise one or more trained neural networks.
The generated speech audio207may be post-processed. Post-processing steps may include denoising, upsampling, and/or decompression to a full sample rate.
Example Synthesizer/Vocoder Method
FIG.3illustrates an example speech audio generator300comprising a synthesizer304and a vocoder310for use in generating speech audio311in a video game.FIG.3shows a more detailed example of the speech audio generators described in relation toFIGS.1and2.
The synthesizer304receives prosodic features301, speech content data302, and speaker identifier data303. The prosodic features301may be provided from output of a prosody predictor, as described above in relation toFIGS.1and2. The prosodic features may comprise a global prosody vector or a sequence of fine-grained prosody vectors.
The synthesizer304comprises a speech content encoder306and a decoder309. The synthesizer304may comprise further encoders, such as a speaker encoder307, and/or a prosody encoder305. The prosody encoder305and/or speaker encoder307may be omitted in some implementations, for example in implementations where prosodic features301and/or speaker identifier data303may be directly combined (e.g. by concatenation, addition, etc.) with speech content encodings generated by speech content encoder306. For example, speech content encodings may be directly combined with prosody embeddings and/or speaker embeddings.
The speech content data302is processed by the speech content encoder306to generate one or more speech content encodings. The speech content encoder306may output a plurality of speech content encodings, with a speech content encoding output for each time step of the speech content data302. The speech content encoder306may comprise neural network layers. For example, the neural network layers may comprise feedforward layers, e.g. fully connected layers and/or convolutional layers. Additionally or alternatively, the neural network layers may comprise recurrent layers, e.g. LSTM layers and/or bidirectional LSTM layers. The one or more speech content encodings output by the speech content encoder306is a learned representation of the speech content data302, enabling the output of synthesized speech audio311corresponding to the speech content data302.
The prosodic features301may be processed by the prosody encoder305to generate one or more prosody encodings. The prosody encoder306may comprise neural network layers. For example, the neural network layers may comprise feedforward layers, e.g. fully connected layers and/or convolutional layers. Additionally or alternatively, the neural network layers may comprise recurrent layers, e.g. LSTM layers and/or bidirectional LSTM layers.
The speaker identifier data303may be processed by the speaker encoder306to generate a speaker encoding. The speaker encoder306may comprise neural network layers. For example, the neural network layers may comprise feedforward layers, e.g. fully connected layers and/or convolutional layers. Additionally or alternatively, the neural network layers may comprise recurrent layers, e.g. LSTM layers and/or bidirectional LSTM layers.
The one or more speech content encodings are received at a combining operation308. The combining operation308outputs one or more combined encodings that are derived from the one or more speech content encodings, the prosodic features301, and the speaker identifier data303. In implementations where the prosody encoder305and the speaker encoder307are omitted, the combining operation308may be configured to combine the one or more speech content encodings with prosodic features301and speaker identifier data303. In other implementations, the combining operation308may combine the one or more speech content encodings with encodings output by prosody encoder305and/or speaker encoder307.
The combining operation308may comprise any operation resulting in a single encoding from two or more inputs. For example, the combination may be performed by an addition, an averaging, a concatenation, etc. The prosody encoder305and speaker encoder307may be configured to produce vector outputs having dimension(s) adapted for combination, during the combining operation308, with the vector output of the speech content encoder306. For example in some embodiments the speech content encoder306, the prosody encoder305, and speaker encoder307may generate vector outputs of the same dimension, which may be combined by a suitable operation such as addition.
The combining operation308may output a combined encoding for each time step of one or more time steps. For example, in implementations where speech content encoder306outputs a speech content encoding output for each time step of the speech content data302, the speech content encoding of each time step may be combined with prosodic features301(or encodings derived therefrom) and speaker identifier data303(or encodings derived therefrom). The prosodic features301may comprise a prosody vector for each time step of the one or more time steps. A combined encoding for a time step may be produced by combining the speech content encoding of the time step with the prosody vector of the time step and the speaker identifier data303(or an encoding derived therefrom).
The decoder309receives the one or more combined encodings and outputs acoustic features for use in generating the speech audio311. Acoustic features may comprise any low-level acoustic representation of frequency, magnitude and phase information such as linear spectrograms, log-mel-spectrograms, linear predictive coding (LPC) coefficients, Mel-Frequency Cepstral Coefficients (MFCC), log fundamental frequency (LFO), band aperiodicity (bap) or combinations thereof. The acoustic features may comprise a sequence of vectors, each vector representing acoustic information in a short time period, e.g. 50 milliseconds.
The decoder309may comprise neural network layers. For example, the neural network layers may comprise feedforward layers, e.g. fully connected layers and/or convolutional layers. Additionally or alternatively, the neural network layers may comprise recurrent layers, e.g. LSTM layers and/or bidirectional LSTM layers.
In some implementations, the decoder309comprises an attention mechanism. In these implementations, the combining operation308generates a combined encoding for each input time step of the speech content data302, as described above. For an output time step, the attention mechanism receives the combined encoding of each input time step and generates attention weights for each of the combined encodings. The attention mechanism averages each combined encoding by the respective attention weight to generate a context vector for the output time step. When decoding to produce predicted acoustic features for an output time step, the decoder309decodes the context vector for the output time step.
The speech audio generator300comprises a vocoder310. The vocoder310is a machine-learned model which is used during processing of the target acoustic features to produce a waveform of speech audio311. The speech audio is synthesized speech audio in accordance with prosodic features301, speech content data302, and speaker identifier data303.
The training of speech audio generator300will be described in relation toFIGS.5and6. In some implementations, the vocoder310may be trained separately to the other components of the speech audio generator300.
For example, the vocoder310may be pre-trained using recordings or input from speakers for whom there are many speech samples. In some cases, the same vocoder310may be used for many speakers without the need for retraining based on new speakers, i.e. the vocoder310may comprise a universal vocoder. For example, the vocoder310may be pre-trained using training examples derived from speech samples wherein each training example comprises acoustic features for the speech sample and a corresponding ground-truth waveform of speech audio. The vocoder310processes the acoustic features of one or more training examples and generates a predicted waveform of speech audio for the one or more training examples. The vocoder310is trained in dependence on an objective function, wherein the objective function comprises a comparison between the predicted waveform of speech audio and the ground-truth waveform of speech audio. The parameters of the vocoder310are updated by optimizing the objective function using any suitable optimization procedure. For example, the objective function may be optimized using gradient-based methods such as stochastic gradient descent, mini-batch gradient descent, or batch gradient descent.
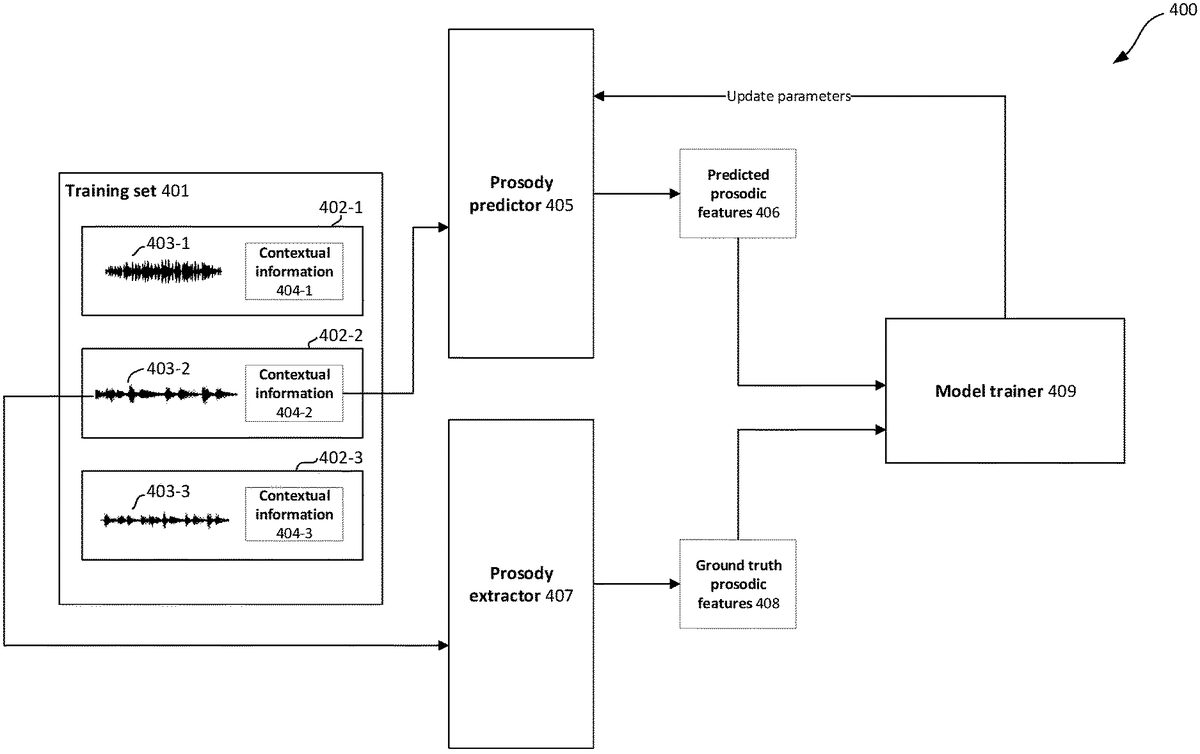
Example Prosody Predictor Training Method
FIG.4illustrates an example method400for training a prosody predictor405to predict prosodic features406from contextual information404. In the embodiment depicted inFIG.4, the prosody predictor405is trained separately to the speech audio generator. The separate training of the speech audio generator will be described in relation toFIG.5.
The prosody predictor405is trained using a training set401comprising one or more training examples402.FIG.4depicts three training examples402-1,402-2,402-3, however it will be appreciated that the training set401can comprise any appropriate number of training examples402. Each training example402comprises speech audio403-1,403-2,403-2that may be output for a particular context of a video game and respective contextual information404-1,404-2,404-3relating to the particular context.
During training, the goal for the prosody predictor405is to process contextual information404for a training example402and output predicted prosodic features406for the training example that are similar to ground truth prosodic features408determined from the speech audio403of the training example402.FIG.4depicts this process for training example402-2.
As shown inFIG.4, speech audio403-2of training example402-2is processed by prosody extractor407to determine ground truth prosodic features408for training example402-2. The ground truth prosodic features may comprise statistical prosodic features determined from speech audio403-2. For example, speech audio403-2may first be converted into one or more one-dimensional time series data. Statistical prosodic features may be determined from the one or more one-dimensional time series.
The one or more one-dimensional time series data may comprise at least one of a volume contour and a pitch contour. Volume (i.e. loudness) may be represented as the root mean square (RMS) of overlapping frames of audio. For fundamental frequency, a normalized cross-correlation function may be used to compute the pitch contour. The time-series may be a smoothed value of fundamental frequency for each audio frame. Unvoiced frames may be set to 0 in the pitch contour based on a threshold on the RMS. Given log fundamental frequency contours and RMS contours, statistical prosodic features may be computed by extracting “global statistics” (mean, variance, maximum, minimum) over each of the two time-series. The one or more statistical features may comprise: a mean, a variance, a maximum and a minimum of the pitch contour; and a mean, a variance, and a maximum of the volume contour. Additionally or alternatively, the statistical prosodic features may comprise features derived from timing information. For example, statistical prosodic features may be determined from phoneme duration information and/or pause duration information.
The contextual information404-2of the training example is received by the prosody predictor405, which processes the contextual information404-2in accordance with a current set of parameters to output predicted prosodic features406for the training example.
Model trainer409receives the predicted prosodic features406and the ground-truth prosodic features408, and updates parameters of prosody predictor405in order to optimize an objective function. The objective function comprises a loss in dependence on the predicted prosodic features406and the ground-truth prosodic features408. For example, the loss may measure a mean-squared error between the predicted prosodic features406and the ground-truth prosodic features408. The objective function may additionally comprise a regularization term, for example the objective function may be a linear combination of the loss and the regularization term. Other weighted losses may be included as part of the objective function.
The parameters of the prosody predictor405may be updated by optimizing the objective function using any suitable optimization procedure. For example, the objective function may be optimized using gradient-based methods such as stochastic gradient descent, mini-batch gradient descent, or batch gradient descent, including momentum-based methods such as Adam, RMSProp, and AdaGrad.
The training process is repeated for a number of training examples, and is terminated at a suitable point in time, e.g. when predicted prosodic features406closely match ground-truth target prosodic features408. Subsequently, the prosody predictor405can be used to predict prosodic features for different contexts of the video game (including “unseen” contexts which were not included in the training set) as the video game is being played.
Example Speech Audio Generator Training Method
FIG.5illustrates an example method500for training a speech audio generator508to generate speech audio509. In the embodiment depicted inFIG.5, the speech audio generator508is trained separately to the prosody predictor.
The speech audio generator508is trained using training set501comprising training examples502.FIG.5depicts three training examples502-1,502-2,502-3, however it will be appreciated that the training set501can comprise any appropriate number of training examples502. Each training example502comprises “ground-truth” speech audio503-1,503-2,503-2, speech content data504-1,504-2,504-3representing the speech content of the speech audio, and speaker identifier data505-1,505-2,505-3indicating the speaker of the speech audio.
During training, the goal for the speech audio generator508is to process prosodic features507, speech content data504, and speaker identifier data505for a training example502and output generated speech audio509that is similar to ground truth speech audio503of the training example502.FIG.5depicts this process for training example502-3.
As shown inFIG.5, speech audio503-3of training example502-3is processed by prosody extractor506to determine prosodic features507for training example502-3. The prosodic features may comprise statistical prosodic features determined from speech audio503-3. For example, speech audio503-3may first be converted into one or more one-dimensional time series data. Statistical prosodic features may be determined from the one or more one-dimensional time series.
The one or more one-dimensional time series data may comprise at least one of a volume contour and a pitch contour. Volume (i.e. loudness) may be represented as the root mean square (RMS) of overlapping frames of audio. For fundamental frequency, a normalized cross-correlation function may be used to compute the pitch contour. The time-series may be a smoothed value of fundamental frequency for each audio frame. Unvoiced frames may be set to 0 in the pitch contour based on a threshold on the RMS. Given log fundamental frequency contours and RMS contours, statistical prosodic features may be computed by extracting “global statistics” (mean, variance, maximum, minimum) over each of the two time-series. The one or more statistical features may comprise: a mean, a variance, a maximum and a minimum of the pitch contour; and a mean, a variance, and a maximum of the volume contour. Additionally or alternatively, the statistical prosodic features may comprise features derived from timing information. For example, statistical prosodic features may be determined from phoneme duration information and/or pause duration information.
Prosodic features507, speech content data504-3, and speaker identifier data505-3for training example502-3are received by speech audio generator508, which processes these received inputs in accordance with a current set of parameters to output generated speech audio509for the training example.
Model trainer510receives the generated speech audio509and the ground-truth speech audio503-3for the training example, and updates parameters of speech audio generator508in order to optimize an objective function. The objective function comprises a loss in dependence on the generated speech audio509and the ground-truth speech audio503-3. For example, the loss may measure a mean-squared error between the generated speech audio509and the ground-truth speech audio503-3. The objective function may additionally comprise a regularization term, for example the objective function may be a linear combination of the loss and the regularization term. Other weighted losses, e.g. a speaker classifier loss, may be included as part of the objective function.
The parameters of the speech audio generator508may be updated by optimizing the objective function using any suitable optimization procedure. For example, the objective function may be optimized using gradient-based methods such as stochastic gradient descent, mini-batch gradient descent, or batch gradient descent, including momentum-based methods such as Adam, RMSProp, and AdaGrad.
The training process is repeated for a number of training examples, and is terminated at a suitable point in time, e.g. when generated speech audio509closely matches ground-truth speech audio503-3. Subsequently, the speech audio generator508can be used to generate realistic expressive speech audio in accordance with received prosodic features, speech content data, and speaker identifier data. When using the speech audio generator508at inference time (e.g. when a video game is being played), the prosodic features507are determined from output of a prosody predictor, as described previously.
Example Joint Training Method
FIG.6illustrates an example method600for jointly training a prosody predictor607and a speech audio generator609.
The prosody predictor607and speech audio generator609are jointly trained using training set601comprising training examples602.FIG.6depicts three training examples602-1,602-2,602-3, however it will be appreciated that the training set601can comprise any appropriate number of training examples602. Each training example602comprises: (i) “ground-truth” speech audio606-1,606-2,606-2that may be output for a particular context of a video game, (ii) respective contextual information603-1,603-2,603-3relating to the particular context, (iii) speech content data604-1,604-2,604-3representing the speech content of the speech audio, and (iv) speaker identifier data605-1,605-2,605-3indicating the speaker of the speech audio.
During training, the goal for the prosody predictor607is to learn a mapping between contextual information603and predicted prosodic features608such that the performance of speech audio generated in accordance with the predicted prosodic features is suitable for the context of the video game represented by the contextual information603. The goal for the speech audio generator609is to process predicted prosodic features608, speech content data604, and speaker identifier data605for a training example502and output generated speech audio610that is similar to ground truth speech audio606of the training example602.FIG.6depicts this process for training example602-3.
The contextual information603-3of training example602-3is received by the prosody predictor607, which processes the contextual information603-3in accordance with a current set of parameters to output predicted prosodic features608for the training example.
The predicted prosodic features607, speech content data604-3, and speaker identifier data605-3for training example602-3are received by speech audio generator609, which processes these received inputs in accordance with a current set of parameters to output generated speech audio610for the training example.
Model trainer611receives the generated speech audio610and the ground-truth speech audio606-3for the training example, and updates parameters of the prosody predictor607and the speech audio generator609in order to optimize an objective function. The objective function comprises a loss in dependence on the generated speech audio610and the ground-truth speech audio606-3. For example, the loss may measure a mean-squared error between the generated speech audio610and the ground-truth speech audio606-3. The objective function may additionally comprise a regularization term, for example the objective function may be a linear combination of the loss and the regularization term. Other weighted losses, e.g. a speaker classifier loss, may be included as part of the objective function.
The parameters of the prosody predictor607and the speech audio generator609may be updated by optimizing the objective function using any suitable optimization procedure. For example, the objective function may be optimized using gradient-based methods such as stochastic gradient descent, mini-batch gradient descent, or batch gradient descent, including momentum-based methods such as Adam, RMSProp, and AdaGrad.
The training process is repeated for a number of training examples, and is terminated at a suitable point in time, e.g. when generated speech audio610closely matches ground-truth speech audio606-3. Subsequently, the prosody predictor607can be used to predict prosodic features for different contexts of the video game (including “unseen” contexts which were not included in the training set) as the video game is being played. The speech audio generator609can be used to generate realistic expressive speech audio in accordance with prosodic features predicted by the prosody predictor607, speech content data, and speaker identifier data.
FIG.7is a flow diagram illustrating an example method700of generating context-dependent speech audio in a video game.FIG.7displays a general overview of the methods described in relation toFIGS.1,2, and3.
In step7.1, contextual information relating to a state of the video game is obtained. The video game may be a sports video game, and the generated speech audio may be for an announcer for the sports video game. Obtaining contextual information relating to the state of the video game may comprise determining contextual information relating to an in-progress match of the sports video game. The contextual information relating of an in-progress match of the sports video game may comprise determining one or more of: statistics relating to one or more teams playing in the match; statistics relating to one or more players playing in the match; statistics relating to the current status of the match; and the type of sport being played in the match.
In step7.2, the contextual information is inputted into a prosody prediction module. The prosody prediction module comprises a trained machine learning model which is configured to generate predicted prosodic features based on the contextual information. The contextual information may comprise speech content data associated with the state of the video game. The speech content data represents the speech content of the speech audio that is to be generated. The contextual information may comprise speaker identifier data. The speaker identifier data is data that indicates the speaker of the speech audio that is to be generated.
The prosody predictor may comprise a neural network. The neural network may comprise an attention mechanism. The prosody prediction module may comprise a convolutional neural network and/or a generative model such as a variational autoencoders.
In step7.3, input data comprising the predicted prosodic features and speech content data are inputted into a speech audio generation module. The speech content data is associated with the state of the video game. The input data may further comprise speaker identifier data for a speaker of the generated speech audio. The speech audio generation module may comprise a neural network. The neural network may comprise a transformer network, a flow-based network or other suitable network architecture.
The speech audio generation module may include a synthesizer. The speech content data may comprise a plurality of speech content segments at a plurality of respective time steps. A speech content encoder of the synthesizer may output a speech content encoding for each time step of one or more time steps of the speech content data. The predicted prosodic features may comprise predicted prosodic features for each time step of the one or more time steps of the speech content data. Step7.3may comprise combining, for each time step of the one or more time steps, the speech content encoding and the prosodic features of the time step.
In step7.4, an encoded representation of the speech content data dependent on the predicted prosodic features is generated using one or more encoders of the speech audio generator module. The one or more encoders may comprise a prosody encoder configured to generate an encoded representation of the predicted prosodic features, and a speech content encoder configured to generate the encoded representation of the speech content data based on the encoded representation of the predicted prosodic features.
In step7.5, context-dependent speech audio is generated, based on the encoded representation, using a decoder of the speech audio generation module.
FIG.8is a flow diagram illustrating an example method800of training a prosody prediction model for use in generating context-dependent speech audio in a video game.FIG.8displays a general overview of the methods described in relation toFIGS.4,5, and6.
In step8.1, one or more training examples are received. Each training example comprises: (i) contextual information for a state of the video game, and (ii) ground-truth speech audio that is associated with the state.
Step8.2comprises steps8.2.1, and8.2.2, each of which are performed for each of the one or more training examples.
In step8.2.1, the contextual information is inputted into the prosody prediction model.
In step8.2.2, predicted prosodic features are generated as output of the prosody prediction model.
In step8.3, parameters of the prosody prediction model are updated. The parameters of the prosody predictor are updated based on an objective function. The objective function is dependent on the predicted prosodic features and the ground-truth speech audio of each training example.
The prosody prediction model may be being trained separately to a speech audio generation model. In this case, the objective function may compare the predicted prosodic features with ground-truth prosodic features of each training example. The ground-truth prosodic features of a training example may be determined from the ground-truth speech audio of the training example. The ground-truth prosodic features may comprise one or more statistical features relating to a pitch contour. The one or more statistical features may comprise a mean, a variance, a maximum, and a minimum of the pitch contour. The ground-truth prosodic features may comprise one or more statistical features relating to a volume contour of the ground-truth speech audio of the training example. The one or more statistical features may comprise: a mean, a variance, and a maximum of the volume contour.
The method800may further involve updating parameters of a speech audio generation model that is being trained separately to the prosody prediction model. This may comprise receiving one or more further training examples. Each further training example may comprise: (i) ground-truth speech audio, and (ii) speech content data representing one or more utterances of the ground-truth speech audio. For each further training example of the one or more further training examples, the method may further comprise determining prosodic features from the ground-truth speech audio. Input data comprising the speech content data and the determined prosodic features may be inputted into the speech audio generation model. Predicted speech audio may be generated as output of the speech audio generation model. Parameters of the speech audio generation model may be updated based on a further objective function, wherein the further objective function comprises a comparison between the generated speech audio and the ground-truth speech audio of each training example.
Alternatively, the prosody predictor may be being trained jointly with a speech audio generation model. In this case, each training example may further comprise speech content data for the ground-truth speech audio. The method800may further comprise, for each training example of the one or more training examples: inputting, into the speech audio generation model, input data comprising the speech content data and the predicted prosodic features; and generating, as output of the speech audio generation model, the predicted speech audio. The parameters of the prosody prediction model and the speech audio generation model may be updated based on the objective function. The objective function may comprise a comparison between the generated speech audio and the ground-truth speech audio of each training example.
FIG.9shows a schematic example of a system/apparatus for performing methods described herein. The system/apparatus shown is an example of a computing device. It will be appreciated by the skilled person that other types of computing devices/systems may alternatively be used to implement the methods described herein, such as a distributed computing system.
The apparatus (or system)900comprises one or more processors902. The one or more processors control operation of other components of the system/apparatus900. The one or more processors902may, for example, comprise a general purpose processor. The one or more processors902may be a single core device or a multiple core device. The one or more processors902may comprise a central processing unit (CPU) or a graphical processing unit (GPU). Alternatively, the one or more processors902may comprise specialised processing hardware, for instance a RISC processor or programmable hardware with embedded firmware. Multiple processors may be included.
The system/apparatus comprises a working or volatile memory904. The one or more processors may access the volatile memory904in order to process data and may control the storage of data in memory. The volatile memory904may comprise RAM of any type, for example Static RAM (SRAM), Dynamic RAM (DRAM), or it may comprise Flash memory, such as an SD-Card.
The system/apparatus comprises a non-volatile memory906. The non-volatile memory906stores a set of operation instructions908for controlling the operation of the processors902in the form of computer readable instructions. The non-volatile memory906may be a memory of any kind such as a Read Only Memory (ROM), a Flash memory or a magnetic drive memory.
The one or more processors902are configured to execute operating instructions908to cause the system/apparatus to perform any of the methods described herein. The operating instructions908may comprise code (i.e. drivers) relating to the hardware components of the system/apparatus900, as well as code relating to the basic operation of the system/apparatus900. Generally speaking, the one or more processors902execute one or more instructions of the operating instructions908, which are stored permanently or semi-permanently in the non-volatile memory906, using the volatile memory904to temporarily store data generated during execution of said operating instructions908.
Implementations of the methods described herein may be realised as in digital electronic circuitry, integrated circuitry, specially designed ASICs (application specific integrated circuits), computer hardware, firmware, software, and/or combinations thereof. These may include computer program products (such as software stored on e.g. magnetic discs, optical disks, memory, Programmable Logic Devices) comprising computer readable instructions that, when executed by a computer, such as that described in relation toFIG.9, cause the computer to perform one or more of the methods described herein.
Any system feature as described herein may also be provided as a method feature, and vice versa. As used herein, means plus function features may be expressed alternatively in terms of their corresponding structure. In particular, method aspects may be applied to system aspects, and vice versa.
Furthermore, any, some and/or all features in one aspect can be applied to any, some and/or all features in any other aspect, in any appropriate combination. It should also be appreciated that particular combinations of the various features described and defined in any aspects of the invention can be implemented and/or supplied and/or used independently.
Although several embodiments have been shown and described, it would be appreciated by those skilled in the art that changes may be made in these embodiments without departing from the principles of this disclosure, the scope of which is defined in the claims.
Claims
- A computer-implemented method of generating context-dependent speech audio in a video game, the method comprising: enabling, by at least one processor of a computing device, gameplay of the video game;determining, by a video game engine of the video game on the at least one processor, an in-game event for which context-dependent speech audio is to be generated during the gameplay of the video game, wherein the in-game event includes an action performed by a character of the video game;obtaining, by the video game engine of the video game, contextual information and speech content data relating to a current state of the gameplay;requesting, by the video game engine of the video game, the context-dependent speech audio from a speech audio generator of the video game;generating, by the speech audio generator responsive to the request, the context-dependent speech audio by: inputting the contextual information relating to the current state of the gameplay into a prosody prediction model, wherein the prosody prediction model comprises a trained machine learning model which is configured to generate predicted prosodic features based on the contextual information;generating, by the prosody prediction model, predicted prosodic features from the input contextual information;inputting, into a speech audio generation model, input data comprising: at least the predicted prosodic features;and the speech content data relating to the current state of the gameplay;generating, using one or more encoders of the speech audio generation model, an encoded representation of the speech content data dependent on the predicted prosodic features;decoding, using a decoder of the speech audio generation model, the encoded representation to generate the context-dependent speech audio;and causing, by the video game engine of the video game, the context-dependent speech audio that matches the current state of the video game to be played among the gameplay of the in-game event.
- The computer-implemented method of claim 1, wherein the one or more encoders comprise a prosody encoder configured to generate an encoded representation of the predicted prosodic features, and a speech content encoder configured to generate the encoded representation of the speech content data based on the encoded representation of the predicted prosodic features.
- The computer-implemented method of claim 1, wherein the video game is a sports video game, wherein obtaining the contextual information relating to the current state of the video game comprises determining contextual information relating to an in-progress match of the sports video game.
- The computer-implemented method of claim 3, wherein the contextual information relating to the in-progress match of the sports video game comprises determining one or more of: statistics relating to one or more teams playing in the match;statistics relating to one or more players playing in the match;statistics relating to a current status of the match;and the type of sport being played in the match.
- The computer-implemented method of claim 1, wherein the contextual information includes the speech content data associated with the current state of the video game.
- The computer-implemented method of claim 1, wherein the input data further comprises speaker identifier data for a speaker of the generated speech audio.
- A non-transitory computer-readable medium containing instructions, which when executed by one or more processors, causes the one or more processors to perform a method comprising: enabling, by at least one processor of a computing device, gameplay of a video game;determining, by a video game engine of the video game on the at least one processor, an in-game event for which context-dependent speech audio is to be generated during the gameplay of the video game, wherein the in-game event includes an action performed by a character of the video game;obtaining, by the video game engine of the video game, contextual information and speech content data relating to a current state of the gameplay;requesting, by the video game engine of the video game, the context-dependent speech audio from a speech audio generator of the video game;generating, by the speech audio generator responsive to the request, the context-dependent speech audio by: inputting the contextual information relating to the current state of the gameplay into a prosody prediction model, wherein the prosody prediction model comprises a trained machine learning model which is configured to generate predicted prosodic features based on the contextual information;generating, by the prosody prediction model, predicted prosodic features from the input contextual information;inputting, into a speech audio generation model, input data comprising: at least the predicted prosodic features;and the speech content data relating to the current state of the gameplay;generating, using one or more encoders of the speech audio generation model, an encoded representation of the speech content data dependent on the predicted prosodic features;decoding, using a decoder of the speech audio generation model, the encoded representation to generate the context-dependent speech audio;and causing, by the video game engine of the video game, the context-dependent speech audio that matches the current state of the video game to be played among the gameplay of the in-game event.
- The non-transitory computer-readable medium of claim 7, wherein the speech audio generation model includes a synthesizer.
- The non-transitory computer-readable medium of claim 8, wherein the speech content data comprises a plurality of speech content segments at a plurality of respective time steps and wherein inputting, into the speech audio generation model, the input data comprising the predicted prosodic features and the speech content data comprises generating, as output of a speech content encoder of the synthesizer, a speech content encoding for each time step of one or more time steps of the speech content data.
- The non-transitory computer-readable medium of claim 9, wherein generating predicted prosodic features comprises generating predicted prosodic features for each time step of the one or more time steps of the speech content data.
- The non-transitory computer-readable medium of claim 10, wherein inputting, into the speech audio generator, the input data comprising the predicted prosodic features and the speech content data comprises combining, for each time step of the one or more time steps, the speech content encoding and the predicted prosodic features of the time step.
- A computer-implemented method of generating context-dependent speech audio in a video game, the method comprising: enabling, by at least one processor of a computing device, gameplay of the video game comprising requesting, by the at least one processor of the computing device, video game content from a video game server while a user is playing the video game;determining, by a video game engine of the video game on the at least one processor, an in-game event for which context-dependent speech audio is to be generated during the gameplay of the video game;obtaining, by the video game engine of the video game, contextual information and speech content data relating to a current state of the gameplay;requesting, by the video game engine of the video game, the context-dependent speech audio from a speech audio generator of the video game;generating, by the speech audio generator responsive to the request, the context-dependent speech audio based upon processing the contextual information and speech content data relating to the current state of the gameplay by one or more machine learning models;and causing, by the video game engine of the video game, the context-dependent speech audio that matches the current state of the video game to be played among the gameplay of the in-game event.
- The computer-implemented method of claim 12, wherein generating, by the speech audio generator responsive to the request, the context-dependent speech audio based upon processing the contextual information and speech content data relating to the current state of the gameplay by the one or more machine learning models comprises: generating, using the one or more machine learning models, predicted prosodic features based upon the contextual information.
- The computer-implemented method of claim 13, wherein generating, by the speech audio generator responsive to the request, the context-dependent speech audio based upon processing the contextual information and speech content data relating to the current state of the gameplay by the one or more machine learning models comprises: generating, using the one or more machine learning models, the speech content data based upon the predicted prosodic features.
- The computer-implemented method of claim 12, wherein the video game is a sports video game, wherein obtaining the contextual information relating to the current state of the video game comprises determining contextual information relating to an in-progress match of the sports video game.
- The computer-implemented method of claim 15, wherein the contextual information relating to the in-progress match of the sports video game comprises determining one or more of: statistics relating to one or more teams playing in the match;statistics relating to one or more players playing in the match;statistics relating to a current status of the match;and the type of sport being played in the match.
- The computer-implemented method of claim 12, wherein the contextual information includes the speech content data associated with the current state of the video game.
- The computer-implemented method of claim 12, wherein an input data further comprises speaker identifier data for a speaker of the generated speech audio.
- A non-transitory computer-readable medium containing instructions, which when executed by one or more processors, causes the one or more processors to perform a method comprising: enabling, by at least one processor of a computing device, gameplay of a video game comprising requesting, by the at least one processor of the computing device, video game content from a video game server while a user is playing the video game;determining, by a video game engine of the video game on the at least one processor, an in-game event for which context-dependent speech audio is to be generated during the gameplay of the video game;obtaining, by the video game engine of the video game, contextual information and speech content data relating to a current state of the gameplay;requesting, by the video game engine of the video game, the context-dependent speech audio from a speech audio generator of the video game;generating, by the speech audio generator responsive to the request, the context-dependent speech audio based upon processing the contextual information and speech content data relating to the current state of the gameplay by one or more machine learning models;and causing, by the video game engine of the video game, the context-dependent speech audio that matches the current state of the video game to be played among the gameplay of the in-game event.
- The non-transitory computer-readable medium of claim 19, wherein generating, by the speech audio generator responsive to the request, the context-dependent speech audio based upon processing the contextual information and speech content data relating to the current state of the gameplay by the one or more machine learning models comprises: generating, using the one or more machine learning models, predicted prosodic features based upon the contextual information.
Disclaimer: Data collected from the USPTO and may be malformed, incomplete, and/or otherwise inaccurate.