U.S. Pat. No. 12,274,950
METHODS AND SYSTEM FOR SMART VOICE CHAT IN MULTIPLAYER GAMING
AssigneeAdeia Guides Inc
Issue DateFebruary 3, 2022
Illustrative Figure
Abstract
Systems and methods for providing smart communications in a video game environment are disclosed. A first positional vector of a first user within a video game environment and a second positional vector of a second user within the video game environment are determined. In a first communication between the first user and second user, the first positional information is detected and a first translation vector between the first positional vector of the first user and the second positional vector of the second user is calculated. Based on the first translation vector, the first positional information is corrected, and the corrected positional information is transmitted to the second user.
Description
DETAILED DESCRIPTION As briefly described above, the directional conflict between users can be resolved by implementing a system that determines information from a first user (e.g., Player 1) that was provided to a second user (e.g., Player 2) and correct that information if it is determined that the information provided was inadequate. In this example, since Player 1 and Player 2 have different fields of view, and the direction of one may not be the same as another, the implemented system can convey the location by converting it to a listener's perspective. This solution is therefore scalable from a player-to-player interaction, which may be more appropriate for an FPS video game, to a player-to-team interaction, which may be more appropriate for a MOBA video game. Indeed, the present disclosure is equally applicable to both scenarios and many more which may not be explicitly referred to herein. Therefore, in the examples given within this disclosure, it is intended that the type of video games referred to within the description and figures are non-limiting and that any type of video game can benefit from the present disclosure. Continuing the example above, if Player 1 is to say, “An enemy is in front of me” to Player 2, the system will analyze the speech and convert it with respect to Player 2's position and perspective (direction, distance, elevation, and the like). This ensures that the positional information is correct with respect to the listener, Player 2. Accordingly, Player 2 will see a message popping up on his screen that “Enemy is on your right,” or, in some examples, the speech may be amended with a natural language unit to relay the same. This resolution will resolve the conflicts among the team and hence give the players an exemplary playing experience. More particularly, the ...
DETAILED DESCRIPTION
As briefly described above, the directional conflict between users can be resolved by implementing a system that determines information from a first user (e.g., Player 1) that was provided to a second user (e.g., Player 2) and correct that information if it is determined that the information provided was inadequate. In this example, since Player 1 and Player 2 have different fields of view, and the direction of one may not be the same as another, the implemented system can convey the location by converting it to a listener's perspective. This solution is therefore scalable from a player-to-player interaction, which may be more appropriate for an FPS video game, to a player-to-team interaction, which may be more appropriate for a MOBA video game. Indeed, the present disclosure is equally applicable to both scenarios and many more which may not be explicitly referred to herein. Therefore, in the examples given within this disclosure, it is intended that the type of video games referred to within the description and figures are non-limiting and that any type of video game can benefit from the present disclosure.
Continuing the example above, if Player 1 is to say, “An enemy is in front of me” to Player 2, the system will analyze the speech and convert it with respect to Player 2's position and perspective (direction, distance, elevation, and the like). This ensures that the positional information is correct with respect to the listener, Player 2. Accordingly, Player 2 will see a message popping up on his screen that “Enemy is on your right,” or, in some examples, the speech may be amended with a natural language unit to relay the same. This resolution will resolve the conflicts among the team and hence give the players an exemplary playing experience.
More particularly, the disclosure generally relates to smart communications in multiplayer gaming and, even more particularly, to systems and related processes for providing relative positional information for a common object of interest between players of a multiplayer game. This is carried out by converting positional information from a perspective of a speaker (e.g., avatar or another in-game character) to a perspective of a listener (e.g., an avatar or other in-game character) with the use of positional vectors and, optionally, rotational vectors to determine the correct information to convert within the original positional information provided by the speaker. Illustratively, the speaker and the listeners are players and teammates in a multiplayer game, and the positional information is conveyed through an in-game “callout” (e.g., the speaker communicates a position of an enemy to a teammate(s)). The disclosed techniques analyze positional information in the speaker communication (e.g., an enemy is in front of me) and identify location information of the speaker and of the listener (e.g., positional vectors, coordinates, a player field of view (FOV), and the like). The techniques use the location information to convert the positional information (e.g., the position of the enemy) from being relative to the speaker to being relative to the listener, and provides the converted positional information to the listener, for example, in a chat screen, as will be described in more detail below, with reference to the figures.
FIG.1is an illustrative diagram showing positional vectors and fields of views of players of a video game in a video game environment, in accordance with some embodiments of the disclosure. Shown inFIG.1is an origin point100, Player 1 and their field of view110, Player 2 and their field of view120, and a plurality of vectors.
In geometry, a positional or position vector, also known as location vector or radius vector, is a Euclidean vector that represents the position of a point P in space in relation to an arbitrary reference origin, O,100. Usually denoted x, r, or s, it corresponds to the straight line segment from O to P. In other words, it is the displacement or translation that maps the origin to P:
r=OP→
The term “position vector” is used mostly in the fields of differential geometry, mechanics and occasionally vector calculus. Frequently this is used in two-dimensional or three-dimensional space but can be easily generalized to Euclidean spaces and affine spaces of any dimension. This is relevant for video game environments where some avatars are “stealthed” and cannot be seen, or the like. In three dimensions, any set of three-dimensional coordinates and their corresponding basis vectors can be used to define the location of a point in space—whichever is the simplest for the task at hand may be used.
Referring toFIG.1, vector
OP1→
is a first positional vector that snows the position of Player 1, a first user, from the origin point100within the video game environment. The origin100is a common origin between all objects within the video game environment. Similarly,
OP2→
is a second positional vector that shows the position of Player 2, a second user, from the origin100.
Commonly, one uses the familiar Cartesian coordinate system, or sometimes spherical polar coordinates, or cylindrical coordinates:
r(t)≡r(x,y,z)≡x(t)e^x+y(t)e^y+z(t)e^z≡r(r,θ,φ)≡r(t)e^r(θ(t),φ(t))≡r(r,θ,z)≡r(t)e^r(θ(t))+z(t)e^z
where t is a parameter, owing to their rectangular or circular symmetry. These different coordinates and corresponding basis vectors represent the same position vector. The choice of coordinate system is largely determined by the complexity of the resolution chosen to solve the communication issue between the players in the video game environment, or the level of intervention the system determines may be needed. In the first instance, the Cartesian coordinate system will be used for straight-line movements, where specifying the motion of an axis is simple: input the location to which the user should travel (or the amount of distance they should travel from the starting point), and a linear path to the specified location is provided; however, no directional information is provided, so for certain video games (such as FPS games) this may not be a sufficient solution.
Although Cartesian coordinates are straightforward for many applications, for some types of motion of an object of interest or for players within a video game environment constantly in motion, it might be necessary or more efficient to work in one of the non-linear coordinate systems, such as the polar or cylindrical coordinates. For example, if an avatar in constant motion around a video game environment is being targeted by a plurality of players, this motion involves circular interpolation around a plurality of players' points of reference; therefore, polar coordinates might be more convenient to work in than Cartesian coordinates. Spherical polar coordinates define a position in two-dimensional or three-dimensional space using a combination of linear and angular units. With spherical polar coordinates, a point is specified by a straight-line distance from a reference point (typically the origin100or the center of the user's point of view110,120), and an angle or two from a reference direction. These are referred to as the radial and angular coordinates (r, θ) or (r, θ, φ) in two-dimensional and three-dimensional respectively.
A cylindrical coordinate system is a three-dimensional coordinate system that specifies point positions by the distance from a chosen reference axis, such as an axis at origin100(not shown), the direction from the axis relative to a chosen reference direction (typically the positive x-direction), and the distance from a chosen reference plane perpendicular to the axis. The latter distance is given as a positive or negative number depending on which side of the reference plane faces the point. The power, and indeed the origin, of the cylindrical coordinate system is the point where all three coordinates can be given as zero. This is the intersection between the reference plane and the axis.
Recall from above that with Cartesian coordinates, any point in space can be defined by only one set of coordinates. A key difference when using polar coordinates is that the polar system allows a theoretically infinite number of coordinate sets to describe any point. Accordingly, by way of a summary, spherical polar coordinates are likely to be the preferred choice for many modern-day dynamic video games; however, the simplicity of Cartesian coordinates may be utilized on hardware with processing limitations, such as mobile gaming or the like, and cylindrical coordinates may be used in connection with objects that have some rotational symmetry about the longitudinal axis.
Referring back toFIG.1, the vectors,
P1P2→andP2P1→
are translation vectors that describe a translation from Player 1 to Player 2, or Player 2 to Player 1, respectively. In Euclidean geometry, a translation is a geometric transformation that moves every point of a figure, shape or space by the same distance in a given direction. A translation can also be interpreted as the addition of a constant vector to every point, or as shifting the origin of the coordinate system. Accordingly, the translation in the video game environment can be applied to the origin position100, or the position of Player 1.
In classical physics, translational motion is a movement that changes the position of an object, as opposed to rotational. For example, a translation is an operation changing the positions of all points (x, y, z) of an object according to the formula
(x,y,z)→(x+Δx,y+Δy,z+Δz)
where (Δx, Δy, Δz) is the same vector for each point of the object. The translation vector (Δx, Δy, Δz) common to all points of the object describes a particular type of displacement of the object, usually called a linear displacement to distinguish it from displacements involving rotational, usually called angular displacements. In some scenarios, a translation vector alone will be sufficient to determine how to correct the positional information; however, in most scenarios, in particular for modern dynamic games such as FPSs, a translation vector is likely to be accompanied by a rotational or rotational vector, which will be described in more detail below.
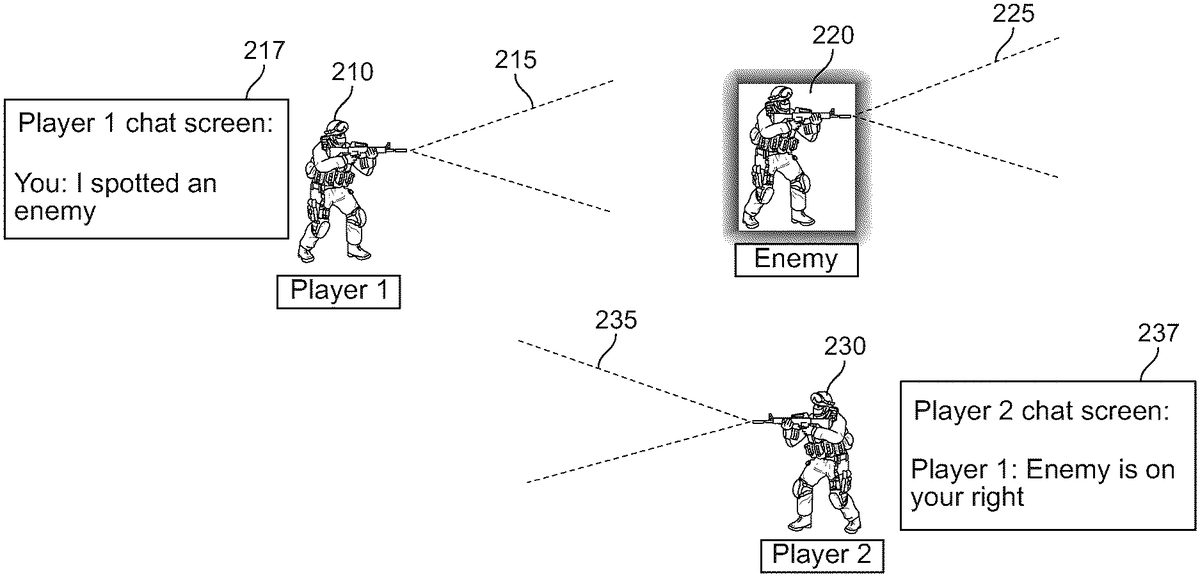
FIG.2Ais an illustrative diagram showing players in a video game environment and their respective field of views and chat boxes, in accordance with some embodiments of the disclosure. For example, inFIG.2A, the video game application facilitates intra-game communication in video game environments featuring first-person or third-person FOV. As shown inFIG.2A, the video game environment is displayed to a first user, Player 1,210in a first-person perspective (e.g., FOV215of the first user210). However, the video game application may also render video game environments in a third-person perspective or through the use of virtual reality or augmented reality hardware and/or applications (e.g., as discussed with reference toFIG.7below). As referred to herein, “a video game environment” may include any surroundings or conditions in which a video game occurs. For example, an environment may be a three-dimensional environment (e.g., featuring three-dimensional models and/or textures) or the video game environment may be a virtual or augmented reality environment (e.g., featuring a virtual world or a view in which computer-generated images are superimposed on a user's view of the real world). As referred to herein, “a video game” may include any electronic presentation that involves interaction with a user interface to generate audio/visual feedback on a video device such as a TV screen, wearable electronic device, and/or computer monitor.
As shown inFIG.2A, in a video game environment having a first-person perspective, the line of sight of the users210,220,230may correspond to the eye level of their avatar in the video game environment. As referred to herein, “a line of sight” may refer to a straight line along which an observer (e.g., the first user) has unobstructed vision within the field of view215,225,235, of the avatar. The field of view may include a range as indicated by a particular angle (e.g., mimicking the wide-angle view that a human may see). The video game application may determine the line of sight of a user based on a predetermined angle (or angles in multiple orientations) as well as the presence of in-game objects that may obstruct the line of sight (e.g., the second user, shown as Player 2,230is facing a different direction from the first user210, and therefore cannot see the enemy avatar220).
Furthermore, the system (e.g., the video game application, or methods used therein) may determine the location of an object of interest by determining line-of-sight boundaries, within the video game environment, from a perspective of the first user210at the first location (e.g., determining the coordinates that define the surfaces of objects and boundaries in the video game environment). The video game application may determine the first trajectory from the first location to the second location within the video game environment. For example, by determining the trajectory from the first location to the second location, the video game application may determine both the trajectory of pointer106of the on-screen graphic, line-of-sight boundaries between the user and an object, and/or a distance between the first and second location.
After the first user210spots the enemy avatar220in their field of view215, the first user informs the second user230, as shown by chat screen217. Chat screen217shows that the first player210has indicated that they have “spotted an enemy,” which is referred to as the first communication. The first communication has little to no information that is useful to the second user230, other than that an enemy has been spotted. Unless the second user230knows where the first user210is, and the direction the first user210is facing (i.e., the boundaries of their field of view215) the second user230does not know where the enemy avatar220is, relative to their position.
In an embodiment, an analysis of the communication is performed to identify positional information and extract relevant information, such as relative directions (e.g., to my left/right, in front of/behind me, above/below me, etc.), distance from the speaker, and positional information with respect to landmarks (e.g., behind the water tower, in the upstairs window, etc.). If no directional information is present in the first communication, then an object referred to in the first communication can be identified in the field of view215of the first user210. In this example, enemy220is identified in the field of view and therefore the system can determine the position information is “in front,” even though the first user210did not say that. In some examples, the analysis of the communication extracts further information, such as an enemy name/character, enemy health status, a weapon used by an enemy, a movement characteristic of an enemy (e.g., still/camping-out, running, riding a particular vehicle, etc.), another context regarding an enemy purpose (e.g., guarding a base/flag, planting a bomb, providing support/healing, etc.), and/or a timestamp of the communication.
Accordingly, the video game application may detect first positional information from the first communication. Continuing the above example, the first communication from the first user210is, “I spotted an enemy,” which does not comprise positional information, as such, but the enemy is identified in the field of view215of the first user210. Therefore, the positional information can be determined as “in front of” the first user210. Next, the positional information is corrected to reflect, relative to the second user230, the position of the enemy avatar220. For example, as shown in chat screen237, the second user230(Player 2) gets the message, “Player 1: Enemy is on your right.” The correction of the positional information is based on at least the first translation vector, as described above with reference toFIG.1. However, by way of summary, as the video game application has already determined the translation of the positional vector of Player 1 to Player 2, this can be used to determine the instruction to transcribe the positional information from Player 1's perspective to Player 2's perspective. Further, and in some instances, optionally, the corrected positional information is transmitted237to the second user.
In the example ofFIG.2A, only a rotational vector is needed. Accordingly, it should be understood that the term “translation vector” is sometimes used herein as a label to describe not only a translation in an x, y, and/or z-direction of the second user's avatar230but also an accompanying rotational and/or an additional rotational vector, as will be described in more detail below, with reference toFIG.2B.
FIG.2Bis an illustrative diagram showing players in a video game environment and their respective field of views and an object of interest with an obstruction in the way, in accordance with some embodiments of the disclosure. In some examples, after observing an object of interest220in the field of view215, the first user210will inform their teammates, for example, the second user230, as described above with reference toFIG.2A. However, in this scenario, the object of interest220is not in the field of view235of the second user230because of obstruction250. Therefore, when applying a translation vector240, the second user will still be facing the wrong direction and their field of view235will still not have the object of interest220in it. Therefore, in most scenarios, the translation vector is also likely to comprise a rotational element, or rotational vector245. In some examples, the translation vector240and rotational vector245are applied separately or in parallel to arrive at a combined translation vector.
In mathematics, the axis—angle representation of a rotational parameterizes a rotational in a three-dimensional Euclidean space by two quantities: a unit vector e indicating the direction of an axis of rotational, and an angle θ describing the magnitude of the rotational about the axis. In the present examples, the unit vector e, the axis of rotational, will be parallel to the avatar's “height” parameter, which is perpendicular to the field of view. However, other axes of rotation may be selected, for example, the axis of rotational may be parallel to the positional vector of the first or second user. In this way, a rotational vector245can be applied directly to the positional vector240to result in a single vector.
Only two numbers, not three, are needed to define the direction of a unit vector e rooted at the origin because the magnitude of e is constrained (see vector below). For example, the elevation and azimuth angles of e suffice to locate it in any particular Cartesian coordinate frame. The angle and axis determine a transformation that rotates three-dimensional vectors (e.g., positional vectors of the first and second users). The axis—angle representation is equivalent to the more concise rotational vector, also called the Euler vector. In this case, both the rotational axis and the angle are represented by a vector codirectional with the rotational axis whose length is the rotational angle θ,
{right arrow over (θ)}=θe
Many rotational vectors correspond to the same rotational. In particular, a rotational vector of length θ+2πM, for any integer M, encodes exactly the same rotational as a rotational vector of length θ. Thus, there are at least a countable infinity of rotational vectors corresponding to any rotational. Furthermore, all rotationals by 2πM are the same as no rotational at all, so, for a given integer M, all rotational vectors of length 2πM, in all directions, constitute a two-parameter uncountable infinity of rotational vectors encoding the same rotational as the zero vector. These relationships are taken into account when inverting the exponential map, that is, when finding a rotational vector that corresponds to a given rotational matrix if applying the present disclosure with matrices rather than vectors.
FIG.3Ashows an example view of a video game environment and on-screen graphics, in accordance with some embodiments of the disclosure. InFIG.3A, the video game application further determines whether or not to present an on-screen graphic, despite also correcting the positional information provided by the first user. For example, the video game application may determine a distance, within the video game environment, between first location308and second location310. The distance between the two locations can be determined based on the absolute length between first location308and second location310(e.g., as the crow flies) in the video game environment. Alternatively or additionally, the number of, and composition of, objects between first location308and second location310may affect the determined distance. For example, the relative distance between two locations in the video game environment may be determined to be greater if multiple objects (e.g., walls) are situated between first location308and second location310.
InFIG.3A, the video game application compares the distance between first location308and second location310to a threshold distance. For example, the threshold distance may correspond to a minimum distance in which on-screen graphics (e.g., on-screen graphic302) are generated relative to a trajectory between the locations of the first and second user (e.g., first location308and second location310). In response to the video game application determining that the distance is within the threshold distance, the video game application may determine to generate for display an on-screen graphic302relative to a trajectory between the locations of the first and second user (e.g., as shown inFIGS.2A-2B). Alternatively, in response to the video game application determining that the distance is equal to or exceeds the threshold distance, the video game application may determine not to generate for display on-screen graphic302.
InFIG.3A, the on-screen graphic displays the corrected positional information, which, in the example shown, is provided in the form of additional positional information: direction and distance information. The direction and distance information, “SE140, 12m” represents that the subject of the corrected positional information “Enemy spotted in Zone A” is southeast, at a bearing of 140 degrees, 12 meters away. Player 2's directional information304is provided such that Player 2 can make their way to the callout target, Zone A.
In some examples, the systems and methods use natural language understanding (NLU) or natural language processing (NLP) algorithms to learn and process vocabulary and map locations used by the players in a game. The players may also provide and edit a list of terms and vocabulary and may tag locations within a game map with certain names. The video game application, systems, and methods use NLU training and user-defined information to analyze the content of the communication and determine where to place a pin, or where the location of interest or object of interest is located. For example, in NLU, various ML algorithms are used to identify the sentiment, perform name entity recognition (NER), process semantics, etc. NLU algorithms often operate on a text that has already been standardized by text pre-processing steps, so permitting the players to add to this library enables different teams or video games, who may already have a commonly used language, to improve further the communication between users.
FIG.3Bshows an example view of an in-game map in a video game environment with on-screen graphics, in accordance with some embodiments of the disclosure. InFIG.3B, there is illustrated an example of a video game application, in which locations and FOVs of a Player A312and a Player B314are shown in an on-screen map. In this example, Player A provides a communication identifying an enemy320in front of them at the end of a corridor behind a wall. In practice, in-game callouts should be concise and are based on a unique vocabulary (slang terms, shorthand, lingo, location names, etc.) that are particular to a player, team, game, game map, etc. So, in this scenario, Player A may say: “Viper Low AK Hall End.” In this example, Viper refers to an enemy avatar with particular characteristics, Low refers to the enemy health level, AK refers to the enemy's weapon, and Hall End refers to a map location.
In the example ofFIG.3B, an on-screen graphic associated with the enemy location320has been generated with a radius322. In this example, the on-screen graphic is augmented to increase in size as a function of time passed since the first communication from Player A, “Viper Low AK Hall End.” Moreover, the rate of increase in size may be based on information extracted from the first communication. In addition, the on-screen graphic can be removed when the time passed reaches a threshold. For example, the video game application may, in the first instance, determine the size of the on-screen graphic based on a distance, within the video game environment, to a spotted enemy avatar or object of interest, as described above with reference toFIG.3A. In such cases, user interactions from users closer to the first user may (e.g., imitating the real-world condition that sounds are heard as louder the closer the user is to the source of the sound) than similar user interactions from users farther away. However, over time, the confidence of the exact location of the enemy avatar322will decrease, as the enemy avatar may move out of sight and continue moving. Accordingly, the radius of the on-screen graphic is increased over time to show that the object of interest is likely still within a zone, but exactly where within the zone is unknown. After the radius reaches a maximum size threshold (which equates to a maximum time threshold) the on-screen graphic is removed.
For a positional vector r that is a function of time t, the time derivatives can be computed with respect to t. In the video game environment, the maximum velocity of the user's avatars can be used to determine the rate of increase of radius322. For example, an avatar's velocity and the rate of increase of the radius can be linked by the equation:
v=drdt
where dr is an infinitesimally small-displacement vector. To further improve the model, higher-order derivatives can improve approximations of the original displacement function, such as the acceleration (a) and jerk (j) functions (these names for the first, second and third derivatives of position are commonly used in kinematics):
a=dvdt=d2rdt2j=dadt=d2vdt2=d3rdt3
The on-screen graphic may be, for instance, a ring/dome-shape or an abstract two-dimensional or three-dimensional boundary that expands from the ping location as time passes from the time of the communication. The rate of the expansion and the contours of the boundary may also be based on the information extracted from the communication, such as running speed and/or jumping/climbing capabilities of different enemy avatars or movement characteristics of a vehicle the enemy was occupying, and input into the above equations to determine the rate of increase of the radius322. In-game environment or map features, such as possible travel paths and obstacles around the pin location, may also have an impact.
Different types of pins and visual effects may be used to represent different game instruments/contexts and characteristics. For instance, different shapes can be used to represent different classes of characters (tankers, melee, ranged, support, etc.); different colors or borders around a pin may represent an enemy's health; a weapon icon may be placed near the pin, etc.
FIG.4shows an example view of a video game environment and a callout score and suggestion, in accordance with some embodiments of the disclosure. InFIG.4, the positional information given by the first user to the second user is analyzed and provided with a callout score. For example, Player 1's chat box410shows that the information they provided was, “there's a guy hiding in the trees.”, which was given a callout score of 6/10. The first user was also provided with a feedback (e.g., a suggestion) to improve in their call-outs in the future, “suggestion: try giving your teammate directions relative to their position.” In some examples, the on-screen visualization (e.g., by highlighting or underlining keywords) of relevant information in the callout can be made, which helps to train players to provide better callouts-more concise, precise, and useful information-to teammates.
Player 2's chat box420shows the corrected positional information, “Player 1: An enemy is behind you, in the trees.” Thus, from Player 2's perspective, no change in their experience is made. In some examples, the callout score can provide the user's avatar in-game experience or rewards, encouraging the user to improve their callouts.
In some examples, the callout score can be improved by not only providing directional information that is relative to the second user but also by highlighting another game context, for example, an enemy or some other object, such as a bomb, flag, trap, item, weapon, vehicle, power-up, etc. Examples of game contexts may include sounds relating to a game instrument, such as enemy footsteps or a ticking bomb. Therefore, different combinations of techniques to process and convert the positional information of the context, and to convey the converted positional information, are provided.
In addition, in some examples (not shown) the callout score is provided as a summary at the end of the video game gameplay to each user. The callout score summary can be provided to all users, so that users can see the most common corrections being made in a match, or to players individually with a personalized callout score and individualized feedback, such as the feedback inFIG.4.
FIGS.5A and5Bshow example views of a video game environment and on-screen graphics, in accordance with some embodiments of the disclosure. InFIGS.5A and5B, the corrected positional information may be provided by the in-game chat system, in conjunction with an on-screen graphic, to aid, for example, new users to the game. For example, a first user, Player 1, may not know the language and terminology commonly used in the video game environment. As shown, inFIG.5A, the first user, Player 1, provides the positional information, “There's someone on the roof of the building I'm looking at,” which, in this particular example, is commonly referred to as building 3—however, due to the FOV of Player 1, the system may determine there is an uncertainty in the first user's reference, as the buildings are relatively close together. Therefore, inFIG.5B, for the second user, an on-screen graphic is used to help assist with the corrected positional information.
In some examples, the video game application may compare a user interaction to a database listing presentation formats associated with different user interactions to determine a presentation format of an on-screen graphic associated with the user interaction. For example, the video game application may have presentation formats that are specific to particular user interactions (e.g., red boxes for audio communications, custom designs for specific in-game actions, etc.). By providing the different presentation formats, the intuitiveness of the cues is further increased.
InFIG.5A, Player 1 has focused on an in-game object, which results in user interaction with the object, as described above. As Player 1's avatar zooms in and interacts with the video game environment, Player 1 may call out an object or boundary to Player 2. For example, a video game application may incorporate and/or have access to a detection module that may determine coordinates (e.g., x, y, and z spatial coordinates and/or any other suitable coordinate system) associated with the user interaction and the positional vector of the first and second user. The coordinates may then be used by the video game application to determine the bounds of the video game environment and/or objects within the video game environment that were interacted with by the user, for determining the object of interest that the user interacted with, prior to receiving the first communication.
After the video game application determines one or more portions of a video game object or environment have been interacted with, the video game application may then expect the first communication, and pre-calculate the current positional vector for the first and/or second user. For example, the video game application may detect an avatar interacting with a wall in the video game environment. In response, the video game application may determine a first positional vector of a first user within a video game environment and determine a second positional vector of a second user within the video game environment. In some embodiments, the video game application may detect a trajectory associated with a user interaction (e.g., performed by the user) by monitoring the path and velocity associated with the user interaction (e.g., the movement of a user while the user is within a predetermined proximity to a video game object (e.g., a wall), which is then used in the calculation of the translation and/or rotational vector.
FIG.6illustrates an exemplary media device600, in accordance with some embodiments of the disclosure. The media device600comprises a transceiver module610, a control module620, and a network module630. The media transmission system may communicate with an additional user device635, such as a home gateway, smartphone, video game controller, or other smart devices. In some examples, the additional user device635is the user's main device for interacting with the video game environment, and the media device600comprises the components for carrying out the processing, in particular when the additional user device is limited in processing capabilities.
In some examples, the transceiver module communicates with a second user device635via communication link618. The communication link618between the transceiver module610and the second user device635may comprise a physical connection, facilitated by an input port such as a 3.5 mm jack, RCA jack, USB port, ethernet port, or any other suitable connection for communicating over a wired connection or may comprise a wireless connection via BLUETOOTH, Wi-Fi, WiMAX, Zigbee, GSM, UTMS, CDMA, TDMA, 3G, 4G, 4G LTE, 5G or other wireless transmissions as described by the relevant 802.11 wireless communication protocols.
In some examples, the second user device635may receive the natural language input (e.g., the first communication between the first user and the second user) and then transmit the natural language input to the media device600. However, these examples are considered to be non-limiting and other combinations of the features herein being spread over two or more devices are considered within the scope of this disclosure. For example, each of the transceiver module, the network module, and the control module may be separate internet of things (IoT) devices that each carry out a portion of the methods herein. Collectively, these devices may be referred to as a system. In some examples, the natural language input may be stored on a server such as server702.
The media device600and/or user device635may collectively be an augmented reality or virtual reality headset. In such an embodiment, an eye contact detection component, which may be a part of control module620, may be used to identify the gaze point of a user, in order to determine whether or not a user is focusing on a particular portion of a video game environment and/or determine a line of sight or field of view of a user and/or avatar. For example, the location upon which a user's eyes are focused may determine whether or not the video game application selects one object over another.
FIG.7is a block diagram representing devices, components of each device, and data flow therebetween for providing smart communications in a video game environment, in accordance with some embodiments of the disclosure. System700is shown to include a user device718, a server702, and a communication network714. It is understood that while a single instance of a component may be shown and described relative toFIG.7, additional instances of the component may be employed. For example, server702may include, or may be incorporated in, more than one server. Similarly, communication network714may include, or may be incorporated in, more than one communication network. Server702is shown communicatively coupled to user device718through communication network714. While not shown inFIG.7, server702may be directly communicatively coupled to user device718, for example, in a system absent or bypassing communication network714. User device718may be thought of as the media device600or635. as described above.
Communication network714may comprise one or more network systems, such as, without limitation, an internet, LAN, Wi-Fi, or other network systems suitable for audio processing applications. In some embodiments, system700excludes server702, and functionality that would otherwise be implemented by server702is instead implemented by other components of system700, such as one or more components of communication network714. In other embodiments, server702works in conjunction with one or more components of a communication network714to implement certain functionality described herein in a distributed or cooperative manner. Similarly, in some embodiments, system700excludes user device718, and functionality that would otherwise be implemented by the user device718is instead implemented by other components of system700, such as one or more components of communication network714or server702or a combination of components. In still other embodiments, the user device718works in conjunction with one or more components of communication network714or server702to implement certain functionality described herein in a distributed or cooperative manner.
The user device718control circuitry728, display734, and input/output circuitry716. Control circuitry728, in turn, transceiver circuitry762, storage738, and processing circuitry740. In some embodiments, user device718or control circuitry728may be configured as user device635ofFIG.6.
Server702includes control circuitry720and storage724. Each of storage724and738may be an electronic storage device. As referred to herein, the phrase “electronic storage device” or “storage device” should be understood to mean any device for storing electronic data, computer software, or firmware, such as random-access memory, read-only memory, hard drives, optical drives, digital video disc (DVD) recorders, compact disc (CD) recorders, BLU-RAY disc (BD) recorders, BLU-RAY 3D disc recorders, digital video recorders (DVRs, sometimes called personal video recorders, or PVRs), solid-state devices, quantum storage devices, gaming consoles, gaming media, or any other suitable fixed or removable storage devices, and/or any combination of the same. Each storage724,738may be used to store various types of content, media data, and or other types of data (e.g., they can be used to store media content such as audio, video, and advertisement data). The non-volatile memory may also be used (e.g., to launch a boot-up routine and other instructions). Cloud-based storage may be used to supplement storages724,738or instead of storages724,738. In some embodiments, the pre-encoded or encoded media content, in accordance with the present disclosure, may be stored on one or more of storages724,738.
In some embodiments, control circuitry720and/or728executes instructions for an application stored on the memory (e.g., storage724and/or storage738). Specifically, control circuitry720and/or728may be instructed by the application to perform the functions discussed herein. In some implementations, any action performed by control circuitry720and/or728may be based on instructions received from the application. For example, the application may be implemented as software or a set of executable instructions that may be stored in storage724and/or738and executed by control circuitry720and/or728. In some embodiments, the application may be a client/server application where only a client application resides on user device718, and a server application resides on server702.
The application may be implemented using any suitable architecture. For example, it may be a stand-alone application wholly implemented on user device718. In such an approach, instructions for the application are stored locally (e.g., in storage738), and data for use by the application is downloaded periodically (e.g., from an out-of-band feed, from an internet resource, or using another suitable approach). Control circuitry728may retrieve instructions for the application from storage738and process the instructions to perform the functionality described herein. Based on the processed instructions, control circuitry728may determine a type of action to perform in response to input received from the input/output path (or input/output circuitry)716or the communication network714. For example, in response to a receiving a natural language input on the user device718, control circuitry728may perform the steps of processes as described with reference to various examples discussed herein.
In client/server-based embodiments, control circuitry728may include communication circuitry suitable for communicating with an application server (e.g., server702) or other networks or servers. The instructions for carrying out the functionality described herein may be stored on the application server. Communication circuitry may include a cable modem, an Ethernet card, or a wireless modem for communication with other equipment, or any other suitable communication circuitry. Such communication may involve the internet or any other suitable communication networks or paths (e.g., communication network714). In another example of a client/server-based application, control circuitry728runs a web browser that interprets web pages provided by a remote server (e.g., server702). For example, the remote server may store the instructions for the application in a storage device. The remote server may process the stored instructions using circuitry (e.g., control circuitry728) and/or generate displays. User device718may receive the displays generated by the remote server and may display the content of the displays locally via display734. This way, the processing of the instructions is performed remotely (e.g., by server702) while the resulting displays, such as the display windows described elsewhere herein, are provided locally on the user device718. User device718may receive inputs from the user via input circuitry716and transmit those inputs to the remote server for processing and generating the corresponding displays. Alternatively, user device718may receive inputs from the user via input circuitry716and process and display the received inputs locally, by control circuitry728and display734, respectively.
It is understood that user device718is not limited to the embodiments and methods shown and described herein. In non-limiting examples, the user device718may be a television, a Smart TV, a digital storage device, a digital media receiver (DMR), a digital media adapter (DMA), a streaming media device, a personal computer (PC), a laptop computer, a tablet computer, a PC media server, a PC media center, a handheld computer, a personal digital assistant (PDA), a mobile telephone, a portable gaming machine, a smartphone, a virtual reality headset, an augmented reality headset, a mixed reality headset, or any other device, client equipment, or wireless device, and/or a combination of the same capable of engaging with a video game environment.
Control circuitry720and/or728may be based on any suitable processing circuitry such as processing circuitry726and/or740, respectively. As referred to herein, processing circuitry should be understood to mean circuitry based on one or more microprocessors, microcontrollers, digital signal processors, programmable logic devices, field-programmable gate arrays (FPGAs), application-specific integrated circuits (ASICs), etc., and may include a multi-core processor (e.g., dual-core, quad-core, hexa-core, or any suitable number of cores). In some embodiments, processing circuitry may be distributed across multiple separate processors, for example, multiple of the same type of processors (e.g., two Intel Core i9 processors) or multiple different processors (e.g., an Intel Core i7 processor and an Intel Core i9 processor). In some embodiments, control circuitry720and/or control circuitry728are configured to implement a video game environment, such as systems, or parts thereof, that perform various processes described herein.
User device718receives a user input704at input circuitry716. For example, user device718may receive a user input like a user swipe, user touch, or input from peripherals such as a keyboard and mouse, gaming controller, or the like. It is understood that user device718is not limited to the embodiments and methods shown and described herein. In non-limiting examples, the user device718may be a Smart TV, a personal computer (PC), a laptop computer, a tablet computer, a WebTV box, a personal computer television (PC/TV), a PC media server, a PC media center, a handheld computer, a stationary telephone, a personal digital assistant (PDA), a mobile telephone, a portable video player, a portable music player, a portable gaming machine, a smartphone, virtual reality headset, mixed reality headset, an augmented reality headset, or any other television equipment, computing equipment, or wireless device, and/or combination of the same.
User input704may be received from a user selection-capturing interface that is separate from device718, such as a remote-control device, trackpad, or any other suitable user movement-sensitive or capture devices, or as part of device718, such as a touchscreen of display734. Transmission of user input704to user device718may be accomplished using a wired connection, such as an audio cable, USB cable, ethernet cable, or the like attached to a corresponding input port at a local device, or may be accomplished using a wireless connection, such as BLUETOOTH, Wi-Fi, WiMAX, ZIGBEE, GSM, UTMS, CDMA, TDMA, 3G, 4G, 4G LTE, 5G, or any other suitable wireless transmission protocol. Input circuitry716may comprise a physical input port such as a 3.5 mm audio jack, RCA audio jack, USB port, ethernet port, or any other suitable connection for receiving audio over a wired connection, or may comprise a wireless receiver configured to receive data via BLUETOOTH, Wi-Fi, WiMAX, ZIGBEE, GSM, UTMS, CDMA, TDMA, 3G, 4G, 4G LTE, 5G, or other wireless transmission protocols.
Processing circuitry740may receive input704from input circuitry716. Processing circuitry740may convert or translate the received user input704which may be in the form of gestures or movement to digital signals. In some embodiments, input circuitry716performs the translation to digital signals, which are then used in processing. In some embodiments, processing circuitry740(or processing circuitry726, as the case may be) carries out disclosed processes and methods.
FIG.8is an illustrative flowchart of a process for providing smart communications in a video game environment, in accordance with some embodiments of the disclosure. It should be noted that process800or any step thereof could be performed on, or provided by, any of the devices shown inFIGS.6and7. In addition, one or more steps of process800may be incorporated into or combined with one or more steps of any other process or embodiment (e.g., process900(FIG.9)).
At step810, the video game application determines a first positional vector of a first user within a video game environment. The determination may be carried out using control circuitry (e.g., via control circuitry720(FIG.7)). At step820, the video game application determines a second positional vector of a second user within the video game environment (e.g., via control circuitry720(FIG.7)). For example, relative to an origin point (e.g., origin100ofFIG.1) in the video game environment, the location and distance of the user (or the user's avatar) within the boundaries of the game environment are determined. In practice, this is carried out by determining the coordinates of an avatar relative to the origin, for example, Player 1's avatar is at (x1, y1, z1), the positional vector is therefore the
OP1→=x1i^+y1j^+z1k^,
where î, ĵ, and {circumflex over (k)} are orthogonal unit vectors; the same can be done for Player 2's avatar, mutatis mutandis.
At step830, the video game application receives a first communication between the first user and the second user (e.g., the first user communicating the location of an object of interest in a chat box or with voice communication to the second user).
At step840, the video game application determines if the first communication contains positional information. If the answer at step840is no, process800optionally continues to step845. At step845, a waiting period may be initiated before process800reverts to step810. If the waiting period isn't initiated, process800may revert to step810immediately or process800ends. For example, the first communication may be an acknowledgement or confirmation of a previous communication, and therefore will not contain any positional information between the first and second user. Accordingly, process800can revert to step810or step830to receive another communication between the first user and the second user, and redetermined the position vectors of the first and second users.
If the answer at step840is yes, process800continues to step850. In some examples, the first communication may contain positional information that is already an ideal or model callout. In which case another determination step, comprising determining if the positional information in the first communication can be improved, is made after step840. In this example, if the positional information cannot be improved, then process800ends or returns to step810.
At step850, the video game application calculates a translation vector between the first positional vector and the second positional vector. In practice, this is carried out by determining the coordinates of each avatar relative to the origin, for example, Player 1's avatar is at (x1, y1, z1) and Player 2's avatar is at (x2, y2, z2). The translation vector between Player 1's avatar to Player 2's avatar is therefore
P1P2→=(x2-x1)i^+(y2-y1)j^+(z2-z1)k^,
where î, ĵ, and {circumflex over (k)} are orthogonal unit vectors; the same can be done to determine the translation vector between Player 2's avatar to Player 1's avatar, mutatis mutandis.
At step860, the video game application corrects the first positional information based on the first translation vector (e.g., providing information relative to the second user's position and direction, instead of the first user's position and direction). For example, the positional information in the first communication may include a direction, distance, elevation, or other information describing a particular location within the game environment relative to the first user's current position and/or field of view. Using the translation vector, the positional information may be corrected so that the direction, distance, elevation, or other information instead describes the particular location within the game environment relative to the position and/or field of view of the second user. At step870, the video game application transmits the corrected positional information to the second user. For example, the first positional information may be transmitted to the second user via the second user's chat box (e.g., chat box237ofFIG.2A). In another example, the first positional information may be transmitted to the second user audibly through speakers, a headset, or the like. For instance, a spoken communication from the first user may be modified with the corrected positional information and the modified communication may be provided audibly, in real-time, to the second user instead of the original first communication.
FIG.9is an illustrative flowchart of a process for calculating a callout score and providing feedback to a user, in accordance with some embodiments of the disclosure. It should be noted that process900or any step thereof could be performed on, or provided by, any of the devices shown inFIGS.6and7. In addition, one or more steps of process900may be incorporated into or combined with one or more steps of any other process or embodiment (e.g., process800(FIG.9)).
At step910, the video game application calculates a difference score between positional information and translation vector. For example, at the time the first communication is received, an object of interest may be identified in the first FOV of the first user. The system can determine, or look up, an ideal phraseology or natural language input (e.g., a phraseology that would yield a perfect or model callout score (i.e., 10/10, 100%, etc.)) and compare the ideal phraseology (e.g., ideal positional information) to the first communication to calculate a difference score between the positional information in the first communication and the ideal positional information that should have been given to the second user. In some examples, the ideal positional information will update according to the relative position of the first and second user. That is to say that as the second user moves through the video game environment, the ideal positional information may need updating to reflect the movement of the second user. Accordingly, the ideal positional information can be determined based on the translation (and/or rotational) vector, between the first and second user, and/or a third positional vector of an object of interest; so that as the second user moves through the video game environment the ideal positional information, knowing that the object of interest is the target, can be updated accordingly.
At step920, the video game application assigns a callout score to the positional information based on the calculated difference score. For example, the difference score may be an arbitrary metric, whereas the callout score may be a score out of10, which a user can readily understand. The callout score is determined based on the calculated difference score, and therefore feedback can be provided to the first user based on the callout score. In the calculation of the difference score, the video game application may use a database of natural language inputs and analyze the natural language input received in the first communication between the first user and second user. The callout score can therefore be based on accuracy, conciseness, completeness, and/or proper use of terminology of the content of the first positional information regarding the video game environment and its parameters, as well as the object of interest, which will be explained in more detailed with reference toFIG.12, below.
At step930, the video game application determines if the callout score is above a threshold. If the answer at step930is no, process900optionally continues to step935. At step935, a waiting period may be initiated before process900reverts to step910. If the waiting period is not initiated, process900may revert to step910immediately or process900ends. If the answer at step930is yes, process900continues to step935.
At step940the video game application provides the feedback to the first user based on the callout score. For example, if Player 1's chat box shows that the information they provided was given a callout score of 6/10. The first user is provided with feedback (e.g., a suggestion) to improve in their call-outs in the future, such as “Suggestion: try giving your teammate directions relative to their position.” In some examples, the on-screen visualization (e.g., by highlighting or underlining keywords) of relevant information in the feedback can be made, which helps to train players to provide better callouts by highlighting keywords that are ideal. After step940, process900can optionally end. However, in some examples, process900can continue to step950. At step950, the video game application receives a second communication between the first user and second user, and process900continues to step840of process800, as described with reference toFIG.8.
FIG.10is an illustrative flowchart of a process for identifying an object of interest in a field of view of one user in a video game environment, in accordance with some embodiments of the disclosure. It should be noted that process1000or any step thereof could be performed on, or provided by, any of the devices shown inFIGS.6&7. In addition, one or more steps of process1000may be incorporated into or combined with one or more steps of any other process or embodiment (e.g., process900(FIG.9)).
At step1010, the video game application retrieves the first field of view of the first user. At step1020, the video game application retrieves the second field of view of the second user. The field of view of a user may be retrieved from data within the video game environment, or determined based on the avatar's positional vector (e.g., location within the video game environment and the direction they are facing). Typically, the FOV of an avatar in a video game environment is different from the field of view of the user, that is, the field of view of the user may be first person (i.e., from the perspective of the avatar) or third person (i.e., a view comprising the user's avatar and the surrounding area). The FOV of the avatar can be further affected by the user's actions, for example, in an FPS video game, if the user is aiming down the sights of a weapon, the field of view is reduced and magnified; in other games, FOV is manipulated by in-game mechanics, such as the “fog of war” in MOBA games, which require friendly avatars in an area to expand the FOV.
At step1030, the video game application identifies an object of interest in the field of view of the first user. For example, objects of interest may include landmarks (e.g., a tree, a roof, an upstairs window, etc.) and or objective/targets (e.g., an enemy avatar, a flag to capture, etc.) At step1040, the video game application determines if an object of interest is in the field of view of the first user and not in the field of view of the second user. If the answer at step1040is no, process1000optionally continues to step1045. At step1045, a waiting period may be initiated before process1000reverts to step1010. If the waiting period isn't initiated, process1000may revert to step1010immediately or process1000ends. If the answer at step1040is yes, process1000continues to step1050. For example, video game environments featuring first-person or third-person perspectives require three-dimensional rendering of the video game environments, in which avatars associated with a user may move and enter into or out of a user's field of view. Describing features in three-dimensional environments that a user can see in their field of view, such as in audio communications, is common, but not necessarily helpful to other users with a different field of view. Obtaining and using the field of view of a user or their avatar can assist in the identification of an object of interest and therefore an indication to the second user of the location of the objection of interest from their perspective. If the object of interest is already in the FOV of the second user, then the system can reduce the level of intervention and simply provide an on-screen graphic or correct the first positional information minimally (e.g., to improve the callout to as close to ideal as possible).
At step1050, the video game application determines a third positional vector for the object of interest. The positional vector of the object of interest is determined in the same way the positional vector for the first or second user's avatar is. For example, relative to an origin point (e.g., origin100ofFIG.1) in the video game environment, the location and distance of the object of interest (e.g., an enemy) within the boundaries of the game environment is determined by determining the coordinates of the object relative to the origin, for example, if Player 1's avatar is at (x3, y3, z3), the positional vector is therefore
OObj1→=x3i^+y3j^+z3k^,
where î, ĵ, and {circumflex over (k)} are orthogonal unit vectors.
At step1060, the video game application calculates a rotational vector for the field of view of the second user based on the second positional vector and the third positional vector. The rotational vector is the amount of rotational required to place the object of interest substantially within the field of view of the second user. The rotational vector can be determined by determining, relative to a chosen axis, a bearing of the object to the second user after the translation vector has been applied. For example, if the second user's avatar is located at (x2, y2, z2) and, after applying the translation vector, the second user's avatar is located at (x3+Δx, y3+Δy, z2+Δz), the object of interest may be located at a bearing of 090 relative to a common axis (such as in the x-direction of the video game environment), which the second user's avatar is facing. Accordingly, a rotational vector can be calculated as
θ→=π2e︷,
whereis a unit vector parallel to the common axis, and
π2
is 90 degrees in radians, the avatar facing 000 (e.g., in the x-direction) in this example.
FIG.11is an illustrative flowchart of a process for generating an on-screen graphic in a video game environment, in accordance with some embodiments of the disclosure. It should be noted that process1100or any step thereof could be performed on, or provided by, any of the devices shown inFIGS.6&7. In addition, one or more steps of process1100may be incorporated into or combined with one or more steps of any other process or embodiment (e.g., process900(FIG.9)).
Process1100starts at step1110. However, process1110may be initiated after step830of process800. At step1110, an on-screen graphic associated with the corrected first positional information is generated. In some examples, the on-screen graphic is used to aid users new to the game, as shown and described inFIGS.3A,3B,5A and5B.
At step1120, the on-screen graphic is augmented to increase in size as a function of time passed since the first communication. For example, the video game application may, in the first instance, determine the size of the on-screen graphic based on a distance, within the video game environment, to a spotted enemy avatar or object of interest, as described above with reference toFIG.3A. The radius of the on-screen graphic may be increased over time to show that the player, or object of interest, is likely still within a zone, but exactly where within the zone is unknown.
At step1130, information from the first communication to determine the rate of increase of size of the on-screen graphic is extracted. At step1140, the video game application determines if the time elapsed since the first communication has reached a threshold. If the answer at step1140is no, process1100optionally continues to step1145. At step1145, a waiting period is initiated before process1100reverts to step1140. If the answer at step1140is yes, process1100continues to step1150. At step1150, the on-screen graphic is removed.
FIG.12illustrates a table of language extracted from media content and weighting assigned to the terms, in accordance with some embodiments of the disclosure. Shown in table1200is a series of terms that have been extracted from media content external to the video game environment. For example, media content sources may comprise YouTube videos, Twitch VODs, Facebook Gaming VODs, in-game communications from other users, or the like. Column1210ofFIG.12shows the “official terms,” that is the terms that the video game designers intended to be used when designing the video game. Columns1220-1240show the “alternate terms,” that is, the terms that have been extracted from the media content sources. For example, the in-game non-player character (NPC), Baron Nashor from the MOBA video game, League of Legends is often referred to as, “Baron,” “Nashor,” or “Nash.”
Also shown in each of columns1210-1240is a weighting score. After extracting information from the media content, a weighting is assigned to the more frequent language found in the media content; in this way the ideal language that should be used in an in-game callout is related to the most common language used by the wider community of players/users. For example, the in-game item “Crest of Insight,” also from League of Legends, is seldom referred to as such. Instead, players tend to refer to the item as “Blue Buff” or simply “Blue.” Accordingly, Crest of Insight has a score of 0.1, Blue Buff a score of 6, Blue a score of 2, and crest a score of 1. The values for the weightings are relative to one another.FIG.12has other examples of official terms and alternate terms with associated weightings.
The term with the highest weighting out of the official term and alternate terms is selected to be the ideal or model term to be used in providing feedback to the first user. In some examples, the term with the highest weighting is also used to correct the first positional information contained within the first communication between the first user and second user.
In some examples, the callout score assigned to the first positional information detected in the first communication is based on the weighting assigned to the terminology. For example, a higher callout score may be assigned to Player 1 using the term “ADC” instead of “carry” as the former term has a higher weighting than the latter. In another example, if player 1 says “Viper Low AK Hall End” this could get a high score based on accuracy of each piece of information—is the enemy actually the Viper avatar, calling out a health status may be useful and could increase a score, likewise with a correct weapon identification and location. Scoring location information in the communication may consider accuracy of a relative location (e.g., player 1 identifying an enemy “20 feet in front of me,” the enemy actually being 50 feet in front of the player at the time of the communication) and use of map location names. In contrast, player 1 saying “enemy in front of me” would get a relatively lower score, as no terminology is used, and the communication is also lacking specific location in formation, weapon information, health information, and the like.
The systems and processes discussed above are intended to be illustrative and not limiting. One skilled in the art would appreciate that the actions of the processes discussed herein may be omitted, modified, combined, and/or rearranged, and any additional actions may be performed without departing from the scope of the invention. More generally, the above disclosure is meant to be exemplary and not limiting. Only the claims that follow are meant to set bounds as to what the present disclosure includes. Furthermore, it should be noted that the features and limitations described in any one embodiment may be applied to any other embodiment herein, and flowcharts or examples relating to one embodiment may be combined with any other embodiment appropriately, done in different orders, or done in parallel. In addition, the systems and methods described herein may be performed in real time. It should also be noted that the systems and/or methods described above may be applied to, or used in accordance with, other systems and/or methods. In this specification, the following terms may be understood given the below explanations:
All of the features disclosed in this specification (including any accompanying claims, abstract, and drawings), and/or all of the steps of any method or process so disclosed, may be combined in any combination, except combinations where at least some of such features and/or steps are mutually exclusive.
Each feature disclosed in this specification (including any accompanying claims, abstract, and drawings), may be replaced by alternative features serving the same, equivalent or similar purpose unless expressly stated otherwise. Thus, unless expressly stated otherwise, each feature disclosed is one example only of a generic series of equivalent or similar features.
The invention is not restricted to the details of any foregoing embodiments. The invention extends to any novel one, or any novel combination, of the features disclosed in this specification (including any accompanying claims, abstract, and drawings), or to any novel one, or any novel combination, of the steps of any method or process so disclosed. The claims should not be construed to cover merely the foregoing embodiments, but also any embodiments which fall within the scope of the claims.
Throughout the description and claims of this specification, the words “comprise” and “contain” and variations of them mean “including but not limited to,” and they are not intended to (and do not) exclude other moieties, additives, components, integers or steps. Throughout the description and claims of this specification, the singular encompasses the plural unless the context otherwise requires. In particular, where the indefinite article is used, the specification is to be understood as contemplating plurality as well as singularity, unless the context requires otherwise.
All of the features disclosed in this specification (including any accompanying claims, abstract, and drawings), and/or all of the steps of any method or process so disclosed, may be combined in any combination, except combinations where at least some of such features and/or steps are mutually exclusive. The invention is not restricted to the details of any foregoing embodiments. The invention extends to any novel one, or any novel combination, of the features disclosed in this specification (including any accompanying claims, abstract, and drawings), or to any novel one, or any novel combination, of the steps of any method or process so disclosed.
The reader's attention is directed to all papers and documents that are filed concurrently with or previous to this specification in connection with this application and which are open to public inspection with this specification, and the contents of all such papers and documents are incorporated herein by reference.
Claims
- A method for providing smart communications in a video game environment, the method comprising: determining a first positional vector of an area occupied by a first avatar of a first user within a video game environment in relation to a point in the video game environment;determining a second positional vector of an area occupied by a second avatar of a second user within the video game environment in relation to the point in the video game environment;detecting, in a first communication from the first user to the second user, first positional information indicative of a location of an object of interest in relation to the first avatar;calculating a first translation vector between the first positional vector of the first user and the second positional vector of the second user;correcting the first positional information based on the first translation vector;and causing to be generated for display the corrected first positional information to the second user.
- The method of claim 1, wherein correcting the first positional information is carried out in response to the first positional information not corresponding to the translation vector.
- The method of claim 2, further comprising: calculating a difference score between the first positional information and video game environment data;assigning a callout score to the first positional information based on the calculated difference score;and providing feedback to the first user based on the callout score.
- The method of claim 1, further comprising: retrieving a first field of view of the first user;retrieving a second field of view of the second user;identifying an object of interest in the field of view of the first user;wherein the object of interest is not in the field of view of the second user;and wherein the correcting of the first positional information is also based on the object of interest.
- The method of claim 4, wherein the object of interest is one or more of: a user, an avatar of a user, an enemy, an immovable object, a moveable object, a target zone, or an item.
- The method of claim 1, wherein detecting first positional information further comprises: extracting directional information from the first communication from the first user;extracting landmark information from the first communication from the first user;extracting supplementary information about the video game environment;and wherein the supplementary information is at least one of: a username, a user-health status, a weapon used by a user, movement characteristics of a user, type of object of interest, characteristics of an object of interest, movement characteristics of an object of interest, a user action, a user intention, or a timestamp of the communication.
- The method of claim 1, further comprising: extracting language from media content external to the video game environment, wherein the media content is related to the video game environment;creating a library of model language based on the language of the media content, wherein a weighting is given to frequently used language in the media content;identifying language in the first communication;comparing the language in the first communication with the library of model language;and providing feedback to the first user based on the comparison.
- The method of claim 1, further comprising: generating an on-screen graphic associated with the corrected first positional information;augmenting the on-screen graphic to increase in size as a function of time passed since the first communication;and removing the on-screen graphic when the function of time passed reaches a threshold.
- The method of claim 8, further comprising: extracting information from the first communication;and determining a rate of increase of the on-screen graphic based on the information extracted from the first communication.
- The method of claim 9, wherein the extracted information comprises at least one of: movement characteristics of a user, type of object of interest, characteristics of an object of interest, movement characteristics of an object of interest, a user action, a user intention, or a timestamp of the communication.
- The method of claim 9, wherein the threshold is determined based on the information extracted from the first communication.
- The method of claim 1, wherein the first positional vector is associated with an area within the video game environment occupied by an avatar of the first user, and wherein the second positional vector is associated with an area within the video game environment occupied by an avatar of the second user.
- The method of claim 1, wherein the first communication comprises text describing the first positional information indicative of the location of the object of interest from the perspective of the first avatar, and the corrected first positional information that is generated for display comprises a correction of the text of the first communication, the corrected text indicating the location of the object of interest from a perspective of the second avatar.
- A method for providing smart communications in a video game environment, the method comprising: determining a first positional vector of a first user within a video game environment;determining a second positional vector of a second user within the video game environment;retrieving a first field of view of the first user;retrieving a second field of view of the second user;identifying an object of interest in the field of view of the first user, wherein the object of interest is not in the field of view of the second user;detecting, in a first communication from the first user to the second user, first positional information;calculating a first translation vector between the first positional vector of the first user and the second positional vector of the second user;correcting the first positional information based on the first translation vector, wherein the correcting of the first positional information is also based on the object of interest;causing to be generated for display the corrected first positional information to the second user;determining a third positional vector for the object of interest;and calculating a first rotational vector for the field of view of the second user based on the second positional vector and the third positional vector, and wherein the first rotational vector is the amount of rotational required to place the object of interest substantially within the field of view of the second user.
- The method of claim 14, wherein correcting the first positional information further comprises: transcribing the first rotational vector into a set of user-readable instructions;and transmitting the user-readable instructions to a computing device of the second user.
- The method of claim 14, further comprising: determining the object of interest is obscured by a second object within the video game environment;calculating a second translation vector based on the second positional vector of the second user and the first rotational vector;and updating the first rotational vector based on the second translation vector.
- A media device comprising a control module, a transceiver module and a network module, configured to: determine a first positional vector of an area occupied by a first avatar of a first user within a video game environment in relation to a point in the video game environment;determine a second positional vector of an area occupied by a second avatar of a second user within the video game environment in relation to the point in the video game environment;detect, in a first communication between the first user and second user, first positional information indicative of a location of an object of interest in relation to the first avatar;calculate a first translation vector between the first positional vector of the first user and the second positional vector of the second user;correct the first positional information based on the first translation vector;and cause to be generated for display the first corrected positional information to the second user.
- The media device of claim 17, wherein correcting the first positional information is carried out in response to the first positional information not corresponding to the translation vector.
- The media device of claim 18, further comprising: calculating a difference score between the first positional information and video game environment data;assigning a callout score to the first positional information based on the calculated difference score;and providing feedback to the first user based on the callout score.
- The media device of claim 17, further comprising: retrieving a first field of view of the first user;retrieving a second field of view of the second user;identifying an object of interest in the field of view of the first user;wherein the object of interest is not in the field of view of the second user;and wherein the correcting of the first positional information is also based on the object of interest.
- The media device of claim 20, further comprising: determining a third positional vector for the object of interest;calculating a first rotational vector for the field of view of the second user based on the second positional vector and the third positional vector;and wherein the first rotational vector is the amount of rotational required to place the object of interest substantially within the field of view of the second user.
- The media device of claim 21, wherein correcting the first positional information further comprises: transcribing the first rotational vector into a set of user-readable instructions;and transmitting the user-readable instructions to a computing device of the second user.
- The media device of claim 21, further comprising: determining the object of interest is obscured by a second object within the video game environment;calculating a second translation vector based on the second positional vector of the second user and the first rotational vector;and updating the first rotational vector based on the second translation vector.
- The media device of claim 20, wherein the object of interest is one or more of: a user, an avatar of a user, an enemy, an immovable object, a moveable object, a target zone, or an item.
- The media device of claim 17, wherein detecting first positional information further comprises: extracting directional information from the first communication from the first user;extracting landmark information from the first communication from the first user;extracting supplementary information about the video game environment;and wherein the supplementary information is at least one of: a username, a user-health status, a weapon used by a user, movement characteristics of a user, type of object of interest, characteristics of an object of interest, movement characteristics of an object of interest, a user action, a user intention, or a timestamp of the communication.
- The media device of claim 17, further comprising: extracting language from media content external to the video game environment, wherein the media content is related to the video game environment;creating a library of model language based on the language of the media content, wherein a weighting is given to frequently used language in the media content;identifying language in the first communication;comparing the language in the first communication with the library of model language;and providing feedback to the first user based on the comparison.
- The media device of claim 17, further comprising: generating an on-screen graphic associated with the corrected first positional information;augmenting the on-screen graphic to increase in size as a function of time passed since the first communication;and removing the on-screen graphic when the function of time passed reaches a threshold.
- The media device of claim 27, further comprising: extracting information from the first communication;and determining rate of increase of the on-screen graphic based on the information extracted from the first communication.
- The media device of claim 28, wherein the extracted information comprises at least one of: movement characteristics of a user, type of object of interest, characteristics of an object of interest, movement characteristics of an object of interest, a user action, a user intention, or a timestamp of the communication.
- The media device of claim 28, wherein the threshold is determined based on the information extracted from the first communication.
Disclaimer: Data collected from the USPTO and may be malformed, incomplete, and/or otherwise inaccurate.