U.S. Pat. No. 12,076,642
Delivery of Spectator Feedback Content to Virtual Reality Environments Provided by Head Mounted Display
AssigneeSony Interactive Entertainment Inc
Issue DateJuly 27, 2021
Illustrative Figure
Abstract
Systems and methods for receiving a scene by a head mounted display (HMD) of an HMD user. One method includes receiving image data of a real world space where the HMD is located. The image data is analyzed to identify positional data on the one or more spectators present in the real world space. The method includes identifying, based on the positional data, that a personal space of a spectator is being encroached. The identifying causing an indicator to alert the HMD user of said encroachment of said personal space of the spectator.
Description
DETAILED DESCRIPTION The following embodiments describe methods, computer programs, and apparatus for processing operations for delivering spectator feedback content (SFC) to a head mounted display (HMD) user while being presented a virtual reality (VR) scene. It will be obvious, however, to one skilled in the art, that the present disclosure may be practiced without some or all of these specific details. In other instances, well known process operations have not been described in detail in order not to unnecessarily obscure the present disclosure. VR environments provided by HMDs are typically configured to by navigable by a single user at a time. Moreover, as HMDs are designed to provide an immersive auditory and visual experience, HMD users interacting with VR content are disconnected from their real world surroundings. This disconnect can be less than optimal in a many situations, for example, when a number of people are sharing or taking turns on a limited number of HMDs. In these social situations, not only is the HMD user unaware how the social group is doing, but the social group is likewise unaware of what the HMD user is experiencing. To increase engagement of persons within the social group, the content of an HMD user's VR experience may be projected onto a social screen that is viewable by persons within a social VR interactive space in real-time. As a result, members of the social group may become spectators of the HMD user's VR experience, thereby increasing a level of user satisfaction with respect to both the HMD user (who may now share his progress with his friends) and spectators within the group (who may find enjoyment in watching their friend navigate a VR scene). Social screens have been described in the art and are used to enable a flow of communication and entertainment ...
DETAILED DESCRIPTION
The following embodiments describe methods, computer programs, and apparatus for processing operations for delivering spectator feedback content (SFC) to a head mounted display (HMD) user while being presented a virtual reality (VR) scene. It will be obvious, however, to one skilled in the art, that the present disclosure may be practiced without some or all of these specific details. In other instances, well known process operations have not been described in detail in order not to unnecessarily obscure the present disclosure.
VR environments provided by HMDs are typically configured to by navigable by a single user at a time. Moreover, as HMDs are designed to provide an immersive auditory and visual experience, HMD users interacting with VR content are disconnected from their real world surroundings. This disconnect can be less than optimal in a many situations, for example, when a number of people are sharing or taking turns on a limited number of HMDs. In these social situations, not only is the HMD user unaware how the social group is doing, but the social group is likewise unaware of what the HMD user is experiencing.
To increase engagement of persons within the social group, the content of an HMD user's VR experience may be projected onto a social screen that is viewable by persons within a social VR interactive space in real-time. As a result, members of the social group may become spectators of the HMD user's VR experience, thereby increasing a level of user satisfaction with respect to both the HMD user (who may now share his progress with his friends) and spectators within the group (who may find enjoyment in watching their friend navigate a VR scene). Social screens have been described in the art and are used to enable a flow of communication and entertainment from HMD user to spectators.
However, even with the use of social screens, the HMD user is nevertheless prevented from being made aware of his audience's reactions and/or emotional states. For example, the HMD user may wish to receive feedback on his game play or in-game decisions. In other circumstances, the HMD user may wish to be informed of whether a spectator has grown restless or frustrated while waiting for a turn to play. Further still, if the HMD user unknowing encroaches on a personal space of a spectator by wandering too close to a spectator or pointing an imagined shooting object at a spectator, the user would want to know.
One method of providing the HMD user with information regarding spectators is to deliver spectator feedback content to a VR scene or environment of an HMD user. In these methods, the user may be apprised with spectator feedback in real-time while still being able to interact with VR content. In general, spectator feedback may include passive feedback and active feedback. Passive feedback of may include, for example, facial expressions, posture, gaze states, and other states of a spectator that he is not necessarily actively attempting to communicate. Active feedback, on the other hand, may include expressions and gestures that might carry some degree of intentionality. The method described herein is able to deliver both passive and active feedback, as both types of feedback are indicators of how an audience is doing and whether they are enjoying themselves.
According to one embodiment of the method, one or more cameras may capture images associated with an audience of spectators of an HMD user. A computing system, which is coupled to the HMD of the HMD user, may analyze the captured images and provide representations of spectators to be displayed within the VR scene experienced by the HMD user. As a result, the HMD user is provided with a view of his spectators, in real-time, while still being allowed continued access to VR content.
As used herein, the term ‘computing system’ refers to a system or VR system that processes and executes VR content to be displayed by an HMD. The computing system may be a separate unit connected to the HMD via wired or wireless channels. In other embodiments, the computing system may be housed or integrated into the HMD body. Additional embodiments may be such that the computing system is both attachable to the HMD body and also removable for other uses. That is, the computing system may be in a form of a smart phone, a tablet, or other mobile computing device having a screen and one or more processors. In still other embodiments, the computing system may be connected to the HMD remotely over the internet, wherein the computing system is implemented on one or more remote servers, or distributed in any combination of the above implementations.
In general, the term ‘VR system’ is taken to mean at least a minimum set of components that allow for spectator feedback content (SFC) to be delivered to an HMD of an HMD user. For example, a VR system as used herein may comprise of at least one HMD, at least one computing system, and at least one spectator detection or capture device. Spectator capturing devices may include, by way of example, one or more cameras, microphones, hand held input devices, or other networked device such as a tablet or a controller.
As used herein, social VR interactive space refers to a real world setting in which an audience of one or more spectators may observe an HMD user interact with VR content first hand.
As used herein, spectator feedback content (SFC) refers to content derived from one or more spectators from a social VR interactive space. SFC may include, by way of example, information regarding who the spectators are, where they are located, how long they have been waiting for a turn, their emotional state, or verbal communications from spectators. SFC may also include digitally communicable expressions such as emojis, GIF s, images, Vines, animations, ‘stickers,’ snaps' (short video recordings), and other forms of digital communication. SFC is also taken to include feedback information regarding a spectator's location relative to the HMD user. Thus, spectator feedback content is taken to include any information that may be captured of a spectator located within a VR interactive space.
As used herein, a VR scene is taken to mean a visual and auditory output of a virtual reality capable device that includes virtual reality content.
In some embodiments of the method, SFC may take a form of a thumbnail within a VR scene or environment so as to not occupy a larger portion of the HMD user's field of view than necessary. Additionally, SFC may include spectator representations that may take one of many forms, such as for non-delimiting examples, an avatar resembling a spectator, a life-like representation of a spectator, a life-like representation of a spectator having a filter, a lens, or an effect for post-processing a captured live image of the spectator, a generic face having multiple possible states of expression, or a name of the spectator. The spectator representations may serve to inform an HMD user of who is present within an audience of spectators, as well as other states a spectator may have. According to some embodiments, an emotional state of a spectator is extracted from image data and mapped to that spectator's representation. In other embodiments, a state of impatience or urgency to have a turn at the HMD of a spectator may also be extracted from image data and/or a player timer module and mapped to the representation of the spectator.
In addition to providing visual information on a state of a spectator, some embodiments of the method may provide SFC that includes verbalizations from a spectator communicating with the HMD user. In these embodiments, one or more microphones are used to capture sound data from the real world setting and parse it into meaningful content. For example, a spectator may be able to communicate a suggestion to the HMD user by simply voicing the suggestion. The suggestion, once captured is then relayed to the HMD user either in text form or in an audible format or both. Generally speaking, HMDs usually have an audio output such as headphones, which can deliver verbal/audio SFC to the HMD user. Moreover, the method is configured to match the verbal feedback to the spectator who offered it, allowing the HMD user to receive feedback and to know whom it came from.
In other social situations, the HMD user may wish to be informed on a location of one or spectators within his proximity. For example, in some social settings (e.g. social VR interactive spaces), spectators may be moving about and continually entering and leaving a proximity of the HMD user. There an increased a likelihood that a personal space of a spectator will be encroached on in these social settings. Certain embodiments of the method may provide a view for tracking a spectator's location relative to the HMD user. Some embodiments of this location tracking view might be in the form of an overhead view such as a bird's-eye-view (BEV) or ‘minimap.’ These embodiments provide positional or overhead views of the HMD user's surroundings, including spectators and other objects within a proximity of the user. The HMD user, having a bird's-eye-view of spectator feedback content (BEV-SFC), may then concentrate on interacting with VR content without fear of running into someone or otherwise encroaching on someone's personal space.
Additional embodiments of the method include operations that record clips of VR scenes as an HMD user is interacting with said VR scene. The method is also able to record clips of the spectator's reaction while watching the HMD user interact with the VR scene. These clips may also be made shareable through the internet.
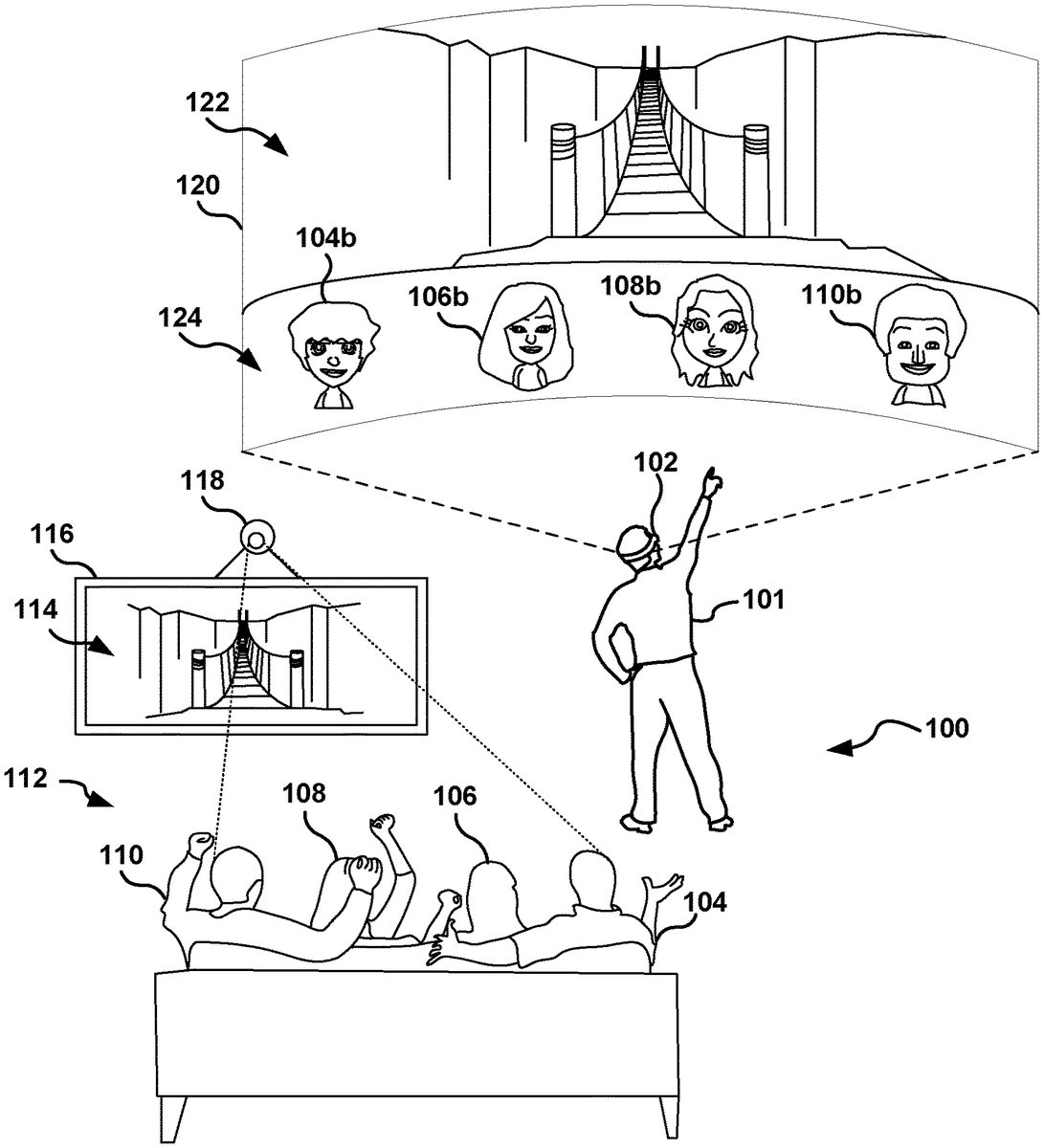
FIG.1shows an embodiment of a social VR interactive space100having an HMD user101being presented a VR display120via an HMD102. The social VR interactive space100is also shown to include an audience112of spectators104-110watching HMD user101navigate the VR scene122via a social screen114displayed on a 2-dimensional display116. Each of the spectators104,106,108, and110are shown to be tracked via image capture device118. Although only one image capture device118is shown, there may be any number of such devices located within the social VR interactive space100. Image capture device118communicates with a computing system (not shown) that is either coupled to HMD102or housed within HMD102. The VR display120is shown to have both a VR scene122and SFC124. In the embodiment shown, SFC124includes avatars104b,106b,108b, and110bwhich correspond to spectators104,106,108, and110, respectively.
Although the social screen114is shown to include VR scene122but not SFC124, the social screen114may also be configured to display SFC124. In such embodiments, spectators104-110may be made aware of how they appear to HMD user101. As noted earlier, although the embodiment shown includes avatars as representations of spectators104-110, there are a number of other methods of representing said spectators to HMD user101.
InFIG.2, an embodiment of a method for delivering SFC to an HMD user is shown. Once operation200displays a VR scene to an HMD user, operation210detects presence of spectators. For example, this operation may use image capture and sound capture to identify that there are other persons are within a proximity of the HMD user. If it is detected that there are spectators within the proximity, operation220may then detect facial expressions and/or emotions of the one or more spectators. Facial feature and expression detection technology is well understood in the art and will not be described in detail here.
The method then flows to operation230, which displays within the VR scene of the HMD user an indication of the presence of the one or more spectators. As discussed above, an indication may take one of many forms, including virtual representations such as avatars or life-like projections of image capture data. For the sake of clarity and consistency, however, the term ‘avatar’ will be used to mean any indication or representation of a spectator within a VR scene of an HMD user. In most cases, each spectator is provided with his or her own individual avatar within the VR scene. The method then flows to operation240, wherein an indication of each spectator's detected facial expression and/or emotions is displayed on each spectator's respective avatar. For example, if a spectator is happy and smiling, the method will display a respective avatar to be happy and smiling. As a result, the method enables the HMD user to be made aware of an emotional state of a spectator.
Generally speaking, while an emotional state is by definition a private subjective state, emotional states are generally accompanied by emotional cues or observable correlates when occurring in humans. As a result, the term emotional state as used herein to refer to an estimation of how a person is feeling based on behavioral data. Behavioral data may include any outwardly observable or measurable state in a person's facial expression, gaze, posture, vocalizations, or movement. Behavioral data may then be captured, tracked, and analyzed to estimate a likely correlating emotional state.
In certain other embodiments, indications of emotional states may be represented in a format that is not based on a virtual expression given by avatars. Instead, emotional states may be represented in terms of symbols, characters, words, color maps, or gauges.
FIG.3shows an overall flow of a method for detecting that a spectator has left the social VR interactive space but later returns. In general, operation300determines identities of spectators through facial recognition methods that are well understood in the art. The method then flows to operation310wherein the identities of each spectator is displayed onto the VR scene being presented to an HMD user. Operation320is able to detect that one of the spectators has left the social VR interactive space and operation330indicates the same. In certain embodiments, the method recognizes which of the spectators has left and indicates so in the VR scene. For example, if LBJ happens to be one of the spectators identified in operation300of the method and he subsequently leaves the proximity, the method may indicate specifically that LBJ has left.
If LBJ returns to the social VR interactive space, the method is able to detect as his return in operation340and indicate the same in the VR scene of the HMD user in operation350. If, instead, a spectator who is not LBJ enters the room, the method is able to recognize a difference between the two spectators and would display an indication that a new spectator has entered the proximity. Thus, the HMD user is made aware of who is within the social VR interactive space, giving him a better idea of his surroundings. In general, it may be the case that people are at greater ease when they are aware of who is in the same room as them. Informing the HMD user of others who are in the same room as he may therefore enhance his VR experience.
InFIG.4, an overall method for delivering SFC in the form of verbal communication to the HMD user is provided. In operation420, the method detects that a spectator is attempting to communicate with the HMD user. For example, a spectator LBJ may be asking the HMD user for a turn on the HMD (e.g., “Let me try!”). The method is then able to determine the identity of the HMD user attempting to communicate and what that user is communicating in operations430and440, respectively. The method then flows to operation450, wherein the VR scene is displayed with an indication of what is being communicated and who communicated it. In certain embodiments, a text transcription of the verbal communication is displayed within the VR scene. In other embodiments, the communication may be audible within the VR scene. Additionally, according to these embodiments, the communication is associated with the respective avatar so that the HMD user is aware of where the communication originated from.
FIG.4shows an overall method for delivering SFC, including information on spectator position and personal space to an HMD user. In operation510, the method detects a position of one or more spectators. The method then flows to operation520wherein a birds-eye-view (or equivalent) of the HMD user's position relative to that of spectators may be displayed. According to certain embodiments, a birds-eye-view is a third-party view from above that is able to show the position of spectators relative to the HMD user. The birds-eye-view is a virtual representation of relative location calculated from image and sound data. That is, since in most circumstances there is not an actual camera having a bird's-eye-view of the social VR interactive space, the view may instead be generated from image capture data and sound capture data.
According to certain embodiments, a bird's-eye-view of the VR interactive space is able to alert the HMD user that he is encroaching on a spectator's personal space. Operation530is configured to detect if encroachment is occurring and operation540may then indicate so in the birds-eye-view within the HMD's VR scene to alert the HMD user. For some embodiments, the method may provide a graphic or animation on the birds-eye-view demonstrating whose personal space is being encroached on or about to be encroached on. The graphic may be a flashing animation like a sonar ‘ping,’ or other noticeable visual element. The indication may vary with the degree to which a spectator's personal space is being encroached. For example, in some embodiments, the alert may grow in size and/or brightness as the HMD user continues moves further into a spectator's personal.
In other embodiments, a user may engaged with the VR content to an extent that a more intense alert may be used to direct his or her attention to an event of personal space encroachment. For example, in some instances, the HMD of the HMD user may be provided with an interruption to the VR content, a vibrational alert, a view of the real world setting superimposed onto the VR content, audible alerts, or audible, textual, or visual instructions or any combination thereof for exiting a personal space of a spectator. In these embodiments, the instructions enable the HMD user to reposition or reorient him or herself to refrain from encroaching on the personal space of the spectator.
In further embodiments, a spectator whose personal space is being encroached may have an image captured of him that is to be displayed within the VR scene of the HMD. By delivering an image of the spectator whose space is being encroached, the HMD user may be made aware of said spectator's position and disposition, according to some embodiments.
A method that is able to deliver an image of a spectator whose space is being encroached to a VR scene of an HMD is shown inFIG.6. For example, operations610and620detect a position and a facial expression of a spectator, respectively. The method then flows to operation630which determines that the HMD user is encroaching on a personal space of a spectator or that a spectator is uncomfortable due to the HMD user's actions. In operation640, the method is able to capture images of the spectator whose personal space is being encroached. In some embodiments, images may be captured by cameras located on or around the HMD, for example, and elsewhere in the social VR interactive space.
The method then flows to operation650wherein a virtual representation of the spectator may be inserted into the VR scene to be displayed to the HMD user. In general, the method displays the representation of the spectator at a display location within the VR scene that corresponds to the spectator's real-world position relative to the HMD user. In this manner, the HMD user is made aware of the spectator's location.
It should be noted that although steps of the method ofFIG.6are presented in an exemplary order, the precise order of each of the steps may be modified or performed in parallel without departing from the scope and spirit of the embodiments. As a result, the order of the steps shown inFIG.6should not be construed as limiting.
FIG.7shows an overall flow of a method for recording a playback clip of a VR scene being navigated by an HMD user. Operation710, for example, is able to display a VR scene being navigated by an HMD on a secondary screen (social screen) viewable by one or more spectators. The method then flows to operation720, which records a playback clip of the VR scene being navigated by an HMD user. As operation720is recording the VR scene, operation730records a clip of the spectators reacting to what they see on the social screen. In so doing, a segment of VR content is matched with audience reaction to the segment, according to certain embodiments. In operation740, the method allows for the playback clip and the audience reaction to be made shareable through the internet.
FIGS.8A-8Cshow multiple embodiments of spectator feedback content (SFC) as it might appear to an HMD user while navigating a VR scene. For example, inFIG.8Aa VR scene801is shown to have SFC in the form of a column of spectator avatars802,804,806, and808. The same spectators are shown to be arranged in a grid form in VR scene803ofFIG.8Band in floating form in VR scene805ofFIG.8C.
It should be appreciated that there are a number of permutations and variations of forms for displaying SFC on a display of an HMD that fall within the scope and spirit of the method that have been intentionally excluded from the figures for the sake of clarity. The figures are exemplary embodiments that illustrate how and where spectator feedback content such as spectator avatar may be placed within the VR display. In the exemplary embodiments shown and described in the Figures, an HMD user is enabled to view spectator feedback content via the spectator avatars802-808while still allowing the HMD user to concentrate on VR content. According to some embodiments, SFC is placed towards an edge or corner of the display, as shown inFIGS.8A and8B, as well asFIG.1. In certain other embodiments, SFC may be placed on a dedicated SFC display or region of the VR display, such as for example, toward an edge, side, or corner of the HMD user's field of view.
FIGS.9A-9Cshow an embodiment of a method for delivering SFC that includes verbal information to an HMD user.FIG.9A, for example, depicts a social VR interactive space having an audience901that includes spectators902,904,906, and908. According to the embodiment, the spectators902-908are observing an HMD user (not shown) interact with VR content, for example via a social screen (not shown). Spectator902is shown to suggest to the HMD user to “grab the ropes for balance” verbalization910. Also shown in the VR interactive space is spectator906asking of spectator908whether or not he took the trash out, a verbalization912. Spectator908responds that he′ll do it later, a verbalization914. Each of verbalizations910,912, and914is captured by microphone array918. Image capture device916also captures contents of the social VR interactive space, including identities of spectators902-908.
FIG.9Bshows an embodiment of a method for parsing sound data928(for example, verbalizations910,912, and914ofFIG.9A) into meaningful expressions930. Additionally, the embodiment shows facial feature data920being analyzed and used to recognize spectator identities922corresponding to audience901. According to this embodiment, spectator identities922and expressions930are applied to a spectator sound logic/filter924, which can filter expressions930intended to be communicated to HMD user (e.g., verbalization910) from those which are not (verbalizations912and914). Further, spectator sound logic/filter924is also able to match expressions924to spectator identities922. For example, spectator sound logic/filter924is able to tag the verbalization910“grab the ropes for balance” to spectator902, JLin. Moreover, the embodiment is able to determine that verbalizations912and914are not communications intended for the HMD user.
In certain embodiments, spectator sound logic/filter924may use voice fingerprinting to match a verbal expression with a spectator who produced the verbal expression. The HMD user may thus be apprised of the expression and the spectator from whom it originated.
Embodiments of methods for matching a sound to a spectator who produced it have been described in a previously filed co-pending U.S. patent application Ser. No. 11/429,133, filed May 6, 2006, entitled “SELECTIVE SOUND SOURCE LISTENING IN CONJUNCTION WITH COMPUTER INTERACTIVE PROCESSING,” and is hereby incorporated-by-reference.
According to this embodiment, verbalizations that are not intended to be communicated to HMD user are able to be filtered out. For example, spectator906(Uma) is shown inFIG.9Ato ask spectator908(LBJ) whether or not he took the trash out912. Spectator908(LBJ) responds that he′ll do it later with verbalization914. Although these verbalizations may be parsed into meaningful expressions930, they are not delivered to HMD user. Spectator Sound Logic/Filter924, having semantic interpretation properties, is able to identify that these expressions are not intended for HMD user.
In certain embodiments, the HDM user is given an ability to mute expressions of verbalizations that originate from one or more users. For example, if a particular spectator is distracting the HMD user from interacting with VR content, the HMD user may be allowed to selectively filter out communications from said spectator. The method and system described herein is able to such selective muting of a spectator using spectator sound logic/filter924. In other embodiments, the user may be enabled to allow all sound data to be communicated to the HMD.
InFIG.9C, a VR scene is shown to receive SFC containing avatars902b,904b,906b, and908bcorresponding respectively to spectators902,904,906, and908. Additionally, the SFC contains expression926tagged to avatar JLin902b. In certain embodiments like the one shown, avatar902bis shown to be relatively larger than the rest of the avatars to better indicate from an originator of the communication. In other embodiments, an audio playback of the recording of the communication may be delivered as part of the SFC to the HMD user. In certain embodiments, only a textual form of the communication is made part of the SFC. In still other embodiments, both textual and audible forms of the expression are made part of the SFC.
FIGS.10A-10Cshow several embodiments of various types of SFC that may be delivered to an HMD user's VR scene. For example,FIG.10Ashows a VR scene1001with SFC displayed in a ‘column’ format on the left-hand side of a display of the HMD. Within the SFC, avatar1002appears impatient as he glances at his watch1010. In certain embodiments, this animation of glancing at one's watch may be representative of a spectator's level of urgency to play. In other embodiments, the animation may correspond to a real life glancing of a watch by spectator1002. In either case, the HMD user is made aware of the spectator1002desire to play. Also shown in VR scene1001are avatars1004and1006, who appear neutral, and an indication1008that spectator LBJ has just entered the social VR interactive space.
FIG.10Bshows an additional embodiment of a VR scene1003with SFC that includes avatars1002,1004,1008, and1006. In this embodiment, the avatars may be arranged in an order corresponding to which spectator should have a next turn. A determination of which spectator should have a next turn may be determined by a computing system associated with the HMD. In the embodiment shown, avatar1004may be displayed at the top of the column of avatars because she has yet to have a turn to play. In addition, the VR system may attempt to inform HMD user that Kat hasn't had a turn to play and ask of the HMD user to let her play1012.
InFIG.10C, an additional embodiment of a VR scene1005is shown with SFC containing avatars1002,1004,1006, and1008. In this embodiment, each avatar is shown with an indication of their current emotional state as detected by a system that is enabled with embodiments of the method and system described herein. For example, avatar1002,1004,1006, and1008are shown to be happy1014, bored1016, scared1018, and impatient1020, respectively. The HMD user is thus made aware of these states of his spectators and may take action accordingly. For example, the HMD user when faced with such SFC might choose to give spectator1008a next turn with the HMD. In other cases, HMD user may choose to give spectator1004a next turn.
FIG.11shows an exemplary embodiment of a VR system capable of delivering SFC to an HMD user. The VR system includes a computing system or module1102having one or more processors as well as a number of hardware and software components. The computing system, for example, is shown to include components I/O interface1104, VR content generator1106, social screen generator1108, microphone1110, sound analyzer1112, facial detection logic1114, expression detection logic1116, spectator identification logic1118, player queue1120, sound filter1122, reaction detection logic1124, social network interface1126, playback module1128, reaction recorder1130, and timer logic1146.
Also shown inFIG.11is camera1146, which captures images from a field of view that includes HMD user1140and an audience of spectators1144. Although shown to be mounted to computing system1102, camera1146may be a standalone unit positioned anywhere within the social VR interactive space while still maintaining a view of HMD user1140and audience1144. Furthermore, although only one camera1146is shown for the sake of simplicity, it should be noted that any number of cameras may be implemented in other embodiments in order to capture images from the social VR interactive space, especially in cases where a number of spectators are many and spread about the interactive space.
Also shown to be connected to computing system1102is head mounted display (HMD)1134. HMD1134is shown to include primary VR display1136, SFC display1138, front-facing camera (FFC)1152, and rear-facing camera (RFC)1154. The primary VR display1136is responsible for displaying to the HMD user1140VR content, while SFC display1138delivers spectator feedback content to the HMD1134. SFC display1138is shown to overlap with a portion of primary VR display1136, demonstrating that SFC1138may be able to use some of VR display1136to deliver SFC to the HMD1134. Additionally, SFC display1138may have a dedicated space within the HMD1134to deliver SFC, according to some embodiments. In other embodiments, the SFC display1138is included by the primary VR display1136.
According to the embodiment shown, FFC1152is able to capture images of audience/spectators1144. Images captured by FFC1152may be used for delivery of SFC to the HMD user1140. The same is true of RFC1154. For example, if HMD user1140wanders too close to a spectator1144, the SFC content generator1108may insert a representation of said spectator1144into the SFC display1138. Further details on using FFC1152or RFC1154for capturing SFC content will be provided below. Additional components that may be included within the HMD are shown in more detail inFIG.16.
HMD user1140is also shown to be connected to HMD1134.
Although HMD1134is shown to be a standalone device connected to computing system1102, it should be appreciated that whether HMD1134is standalone or integrated with computing device1102is immaterial to the execution and scope of the method. For example, in some embodiments, HMD1134may have a slot or mount for computing device1102, which may be allow for computing device1102to be attached to and detached from HMD1134freely. In still other embodiments, HMD1134may be a standalone device that is connected to computing system1102either via wire or wirelessly. Additionally, there are certain embodiments in of the method and system in which the primary VR display1136and the SFC display1138are associated with the computing device1102, which is in turn associated with the HMD1134. In these and other embodiments, the HMD1134may act as a holder or assembly for a separable computing system1102that is associated with a display including the primary VR display1136and the SFC display1138.
Included within certain embodiments of computing system1102are VR content generator1106and social screen content generator1106. VR content generator1106is generally responsible for processing operations for delivering VR content to the HMD1134. Social screen content generator1108is generally responsible for providing a view of the HMD user's experience to a secondary display such as a social screen1142. In certain embodiments, the social screen content generator1108renders a 2-dimensional version of the VR scene to be displayed on social screen1142. Methods for rendering 2-dimensional projections or versions of 3-dimensional content is well described in the art and will not be described in detail here.
Also shown to be included in computing system1102are facial detection and expression detection logics1114and1116, respectively. Facial detection logic1114uses facial recognition technology to identify who a spectator is. For example, if a spectator leaves the room, facial detection logic1114is configured to recognize who left the room. If the same spectator re-enters the room, facial detection logic1114is able to recognize that the same person who left the room has come back. The computing system1102is able to use facial detection logic1114to inform the HMD user1140that the spectator who has entered the social VR interactive space was the same spectator who had left as opposed to, for example, a new spectator.
If it were the case that a new spectator has entered the room, facial detection logic1114is configured to recognize that a new spectator has entered the social VR interactive space and inform HMD user1140of the same. In some embodiments, facial detection logic1114communicates with spectator database1150, which creates a store of individual spectator profiles. In other embodiments, facial detection logic1114communicates with spectator identification logic1118, which uses facial recognition capabilities of facial detection logic1114to keep track of spectators. In addition, spectator identification logic1118may also be configured to communicate with spectator database1150to determine that a given spectator has a profile associate with him in the database1150.
Spectator database1150, in some embodiments, may store a number of types of information regarding each spectator. For example, database1150may store facial feature data of a spectator so that facial detection logic1114and spectator detection logic1118may make a positive identification of a spectator with a spectator profile. Within each spectator profile, a spectator's preferences, and/or tendencies, and/or behavioral patterns may be stored. For example, a first spectator may be more patient than a second spectator. Data capturing this difference may be stored and used in SFC content generator1148.
In addition to facial detection logic1114, which may determine the identity of a spectator, expression detection logic1116is operable to detect an emotional state of a spectator based on his facial expressions. For example, expression detection logic1116may analyze a number of facial characteristics of a spectator such as eye movement, rate of eye blink, head position, pupil dilation, shape of mouth, etc. From such facial characteristic data, one or more emotional states may be extrapolated. Emotional state data provided by expression detection logic1116may also be used by SFC content generator1148for providing the HMD user1140with information regarding a state of a spectator.
Reaction detection logic1124, in some embodiments, may detect facial features indicative of discrete types of reactions, such as surprise, humor, fear, worry, excitement, awe, etc. Reaction detection logic1124communicates with reaction recorder1130, which is configured to record a live video of spectator reaction when reaction detection logic determines that a particular intensity or type of reaction is occurring. Reaction recorder1128receives a video stream from camera1146but does not necessarily record or store spectator video at all times. For example, in some embodiments, the VR content may be such that audience reaction is not so frequent. In such embodiments, the reaction detection logic1124may decide only to record when a level of reaction reaches a certain threshold. That is, audience reactions which are noteworthy or worth sharing are able to be detected by reaction detection logic1124and recorded and saved by reaction recorder1130. In other embodiments, audience reaction may be constantly recorded and saved.
In general, an audience reaction recording is tagged or affixed to a corresponding segment of VR content which is being reacted to. In certain embodiments, playback module1128synchronizes the two clips such a third party who watches the two clips playing simultaneously will be provided with a segment of VR content along with a clip of audience reaction to the VR content in real time. For example, if there is a recorded clip of VR content that happens to be funny and a corresponding clip of an audience's laughing reactions, the two may be synchronized as if the audience were reacting in real time to the funny VR content by playback module1128. Together, the VR content clip and the audience reaction clip may be called social interactive VR content. Playback module1128is also configured to receive playback request from the HMD user or a remote client device and deliver playback content to the HMD user or remote client device.
In certain embodiments, playback module1228also interfaces with a social network interface1126, which is itself interfaced with one or more application programming interfaces (API's) of one or more social networks1132. The social networks1132may, for example, support playback the social interactive VR content. Additionally, HMD user reaction maybe included in the social interactive VR content. For example, cameras facing the HMD user may record the user's movement in response to VR content. Microphones may also record the HMD user's verbal reaction to VR. Both of such reactions may be enjoined to the social interactive VR content and made shareable through the internet via playback module1128and social network interface1126.
Also shown to be included in computing system1102are sound capture device1110, sound analyzer1112, and sound filter1122. These components, in certain embodiments, are responsible for capturing audible forms of SFC to be used by SFC content generator1148. For example, sound capture device1110is configured to detect that a spectator is communicating with the HMD user1140and sound analyzer1112is configured to parse sound data into meaningful expressions.
In certain embodiments, sound filter1122is configured to separate expressions intended to be communicated to HMD user1140from sounds and expressions not intended to be communicated to the HMD user1140. According to these embodiments, the HMD user1140is provided only with pertinent SFC and sounds not helpful or informative to the HMD user1140may otherwise be filtered out.
In certain other embodiments, HMD user1140may decide to selectively block communications of one or more spectators if they are unproductive or distracting, for example. HMD user1140may do so via sound filter1122, wherein the filter may detect a source of each communication and selectively block those of the particular spectator whose comments are not wanted. Sound filter1122is able to do so in some embodiments by using voice recognition and/or 3-dimensional sound sourcing. For example, in certain embodiments, sound filter1122can recognize that a sound is from a spectator whose comments are not welcome and specifically filter them out. In other embodiments, sound filter1122is able to receive data regarding a position or location of a source of sound and cross reference the source of sound to a detected identity of a person by facial detection logic1114and spectator identification logic1118.
Also shown to be included in computing system1102are player queue1120and timer logic1146. According to certain embodiments, player queue1120is configured to keep track of a queue of spectators for deciding who gets to have a next turn on the HMD. For example, if there are four spectators waiting to have a turn, the player queue1120will place each spectator in a queue based on the relative time each player has waited for a turn and/or an amount of time that spectator has taken previous turns on the HMD.
In some embodiments, player queue1120communicates with timer logic1146, which may record an amount of time each spectator has waited for a turn. Additionally, timer logic1146may also record an amount of time an HMD user has spent using the HMD. Player queue1120and timer logic1146may be used by SFC content generator1148for informing HMD user1140of a player queue or a time that a spectator has waited for a turn on the HMD.
Also shown to be included in computing system1102is spectator feedback content (SFC) generator1148. SFC generator1148, in general, is responsible for producing content regarding a state of one or spectators of an audience1144and delivering it to the SFC display1138of HMD1134. In some embodiments, SFC generator collects data from various components included in computing system1102and creates content viewable for HMD user1140. For example, SFC generator1148may collect data from facial detection logic1114, expression detection logic1116, and spectator identification logic1118to render a series of avatars representing the audience/spectators1144. In some embodiments, SFC generator1148is able to use a same avatar for recurring spectators whom are recognized by facial detection logic1114. In other embodiments, spectators are given an opportunity to select and customize their own avatars.
SFC generator1148may also be configured to take expression detection logic1116data and spectator identification logic1118to map spectator facial expression to respective avatars. SFC generator1148may also collect data from sound capture device1110, sound analyzer1112, and sound filter1122to deliver verbal feedback of spectators to the HMD user1140. Additionally, SFC content generator1148may also be configured to attribute SFC to non-player characters in addition to or instead of avatars.
In general SFC generator1148communicates with VR content generator1106to determine a most effective format and way of delivering SFC to the HMD user1140. For example, if SFC generator1148determines that HMD user1140should not be alerted of something, then it may decide to deliver SFC in an unobtrusive location within the VR display. If, on the other hand, SFC generator1148determines that HMD user1140should be made aware of some state of a spectator, it may then decide to deliver SFC or a portion thereof at a purposefully obtrusive or otherwise noticeable location within the VR display.
FIGS.12A and12Bshow additional embodiments for delivering SFC to a VR scene with respect to an audience of spectators and an amount of time they have been waiting to have a turn. In VR scenes1202and1202b, an HMD user1204is shown to pushing a ball1206up a mountain1208in a game of ‘Sisyphus.’ SFC is also shown to be delivered to the VR scene. For example, avatars1210,1214,1218, and1222are shown to be progressing along timer bars1212,1216,1220, and1224, respectively. In certain embodiments, avatars that have moved the farthest along a timer bar are the ones who have waited the longest. For example, spectator1210is shown to have moved along time bar1212farther than the rest of the spectators1214,1218, and1222, and as a result may be displayed at the top of the SFC display.
As more time passes, each avatar1210,1214,1218, and1222is shown to have progressed along time bars1212,1216,1220, and1224, respectively. HMD user is thus made aware of how long each spectator has waited for a turn by each avatar's relative progress along their respective time bars. In the embodiment shown, an additional indication of the amount of time the HMD user has been playing is shown in the form of an aging HMD user avatar1204b.
Additional embodiments for delivering SFC are shown inFIGS.13A and13B. For example, in VR scene1301avatars1310,1314, and1318are shown to be presented as SFC within the VR scene. Avatar1310is shown to not be especially happy in his expression. Also attributed to avatar1310is the expression/communication to “hurry up dude!” HMD user1308is thus made aware that spectator/avatar1310is impatient and would like for him to hurry up. Avatar1314, on the other hand, is shown to be pleased both facial-expressively and verbally1316. Spectator/avatar1318, although shown facial expressively to be not be displeased is however shown to be eager to have a turn next 1320. Also shown in VR scene1301is an indication that a fourth spectator, LBJ, has left the social VR interactive space. The HMD user is thus made aware of several states of his spectators with respect to how they feel and their eagerness to have a turn.
FIG.13Bshows an additional embodiment of delivering SFC to a VR scene1303. In the embodiment shown, real life or life-like representations1324,1326, and1328of a spectator is shown. Representation1324shows the spectator to be pouting, while representation1326shows the spectator to be excited, and representation1328shows spectator to be angry and/or frustrated. As a result, according to this embodiment, the HMD user is apprised of not just data on a state of a spectator, but a qualitative, life-like display of the spectator's emotional and/or expressive state.
FIGS.14A through14Fshow a method of delivering SFC1414to VR scenes1401,1403, and1405of an HMD user1402in response to a personal space of a spectator being encroached on.FIG.14A, for example, shows HMD user1402interacting with a VR scene1401with a shooting device1404. Spectators1406,1408,1410, and1412are shown to be watching HMD user1402within a social VR interactive space1413. HMD user1402is shown to be pointing shooting device in a direction of spectator1406, which is according to some embodiments a way of encroaching on someone's personal space. In correspondingFIG.14B, a VR scene1401is shown to include a monster1418which the HMD user1402is targeting. Also shown within the VR scene is SFC1414, which may in certain embodiments be a birds-eye-view (BEV) (or other overhead view) of HMD user1402and spectators1406,1408,1410, and1412. Spectators in BEV-SFC1414are shown as lettered circles A, B, C, and D, respectively.
In certain embodiments of the BEV-SFC, spectator position relative to the HMD user is proportional to a real world position of the spectator in the social VR interactive space1413. Also shown in BEV-SFC1414is a representation of the shooting device1404as well as a virtual line of shot1420to indicate what direction and into what the HMD user1402may be pointing at. As shown inFIG.14A, HMD user1402is pointing shooting device1404at spectator1406, thereby encroaching on a personal space of the spectator1406. An indication1416that the personal space of spectator1406is being encroached by HMD user1402is shown in BEV-SFC1414in the form of highlighted and/or pulsating rings around spectator1406's virtual representation.
InFIG.14C, HMD user1402is shown to have realized that he is pointing shooting device1404at a spectator and proceeds to adjust his position. HMD user1402is shown to have moved toward his right hand side such that his line of shot1420no longer coincides with spectator1406's personal space. As a result, the indication1416that spectator1406's personal space is being encroached is lessened. However, by moving, HMD user1402has unwittingly moved into spectator1412's personal space1422. BEV-SFC1414indicates as much by highlighting spectator1412's virtual representation with pulsating rings indication1422.
It should be noted that while indications1416and1422are shown to be pulsating rings that alert HMD user1402that one or more personal spaces are being encroached on, indications1416and1422may take one of several forms, including an audible warning, visual or audible instructions for repositioning, or any combination thereof.
InFIGS.14E and14F, HMD user1404is shown to have repositioned and/or reoriented himself such that line of shot1420is no longer in a direction facing spectators1406,1408,1410, and1412. As a result, indications1416and1422are no longer presented in BEV-SFC1414of VR scene1405. In certain embodiments, the VR content generator may reposition the HMD user1402by providing visual and/or verbal instructions. In addition, it may pause or slow the VR content and reposition VR content to correspond with a new position and/or orientation of HMD user1402. For example, while HMD user1402is turning away from the audience to a new orientation, target monster1418is repositioned accordingly.
In certain other embodiments, a target such as monster1418may be selectively moved, shifted, or repositioned to reposition and/or reorient HMD user1402away from a state of encroaching a personal space of a spectator. For example, a VR content generator may selectively move a target away from a direction facing a spectator if it is determined that a personal space of a spectator is being encroached on. As a result, the HMD user1402is provided with an opportunity to disengage from a state of encroachment of a personal space of a spectator without disengaging from VR content. The HMD user1402may not even realize that he is being directed away from a state of encroachment as the VR content generator seamlessly redirects his position and orientation away from personal spaces of an audience.
FIGS.15A-15Dshow additional embodiments for delivering SFC to a VR scene1501. InFIG.15A, for example, an HMD user1502is shown to be interacting with VR content via a shooting device1504. Spectators1506,1508, and1510are also shown to be within the social VR interactive space1512. Much like inFIG.14A, HMD user1502is pointing shooting device1504in a direction of a spectator1506. However, instead of displaying a BEV-SFC in VR scene1501, a real world image or representation of spectator1506is superimposed or inserted into VR scene1501ofFIG.15B. According to this embodiment, the real world image or representation of spectator1506is shown to be captured by a FFC1503.
In this embodiment, for example, target monster1514is shown in the foreground while a real world representation of spectator1506is shown in the background. Real world representation of spectator1506is also shown to have an expression that is neutral. Additionally, real world representation of spectator1506is shown to have a position and orientation within the VR scene1501that corresponds to the spectator1506's real world position and orientation. For example, the closer a spectator1506is to HMD user1502, the larger the spectator's real world representation will appear within VR scene1501.
InFIG.15C, HMD user1502is shown to have moved closer to spectator1506. In certain embodiments, having HMD user1502within a certain distance of a spectator indicates that the spectator's personal space is being encroached. This is especially the case if HMD user1502is wielding a pointing and/or shooting device or controller. As a result, real world representation1506becomes more prominent and it is moved to the foreground. HMD user1502is thus given an opportunity to assess a position and orientation of spectator1506based on an a way spectator1506's real world representation appears within1501. For example, in VR scene1501, spectator1506's real world representation appears to HMD user1502to be very close. In addition, according to this embodiment, an expression of discomfort of spectator1506is also shown to be present in the spectator's real world representation.
FIG.16illustrates an additional embodiment of an HMD1602that may be used with the presented method and/or system. HMD1602includes hardware such as a processor1604, battery1606, virtual reality generator1608, buttons, sensors, switches1610, sound localization1612, display1614, and memory1616. HMD1602is also shown to include a position module1628that comprises a magnetometer1618, an accelerometer1620, a gyroscope1622, a GPS1624, and a compass1626. Further included on HMD102are speakers1630, microphone1632, LEDs1634, object/s for visual recognition1636, IR lights1638, front camera1640, rear camera1642, gaze tracking camera/s1644, USB1646, permanent storage1648, vibro-tactile feedback1650, communications link1652, WiFi1654, ultra-sonic communication1656, Bluetooth1658, and photo-sensitive diode (PSD) array1660.
Although the method operations were described in a specific order, it should be understood that other housekeeping operations may be performed in between operations, or operations may be adjusted so that they occur at slightly different times, or may be distributed in a system which allows the occurrence of the processing operations at various intervals associated with the processing, as long as the processing of the changing of VR operations are performed in the desired way.
One or more embodiments can also be fabricated as computer readable code on a computer readable medium. The computer readable medium is any data storage device that can store data, which can be thereafter be read by a computer system. Examples of the computer readable medium include hard drives, network attached storage (NAS), read-only memory, random-access memory, CD-ROMs, CD-Rs, CD-RWs, magnetic tapes and other optical and non-optical data storage devices. The computer readable medium can include computer readable tangible medium distributed over a network-coupled computer system so that the computer readable code is stored and executed in a distributed fashion.
Although the foregoing embodiments have been described in some detail for purposes of clarity of understanding, it will be apparent that certain changes and modifications can be practiced within the scope of the appended claims. Accordingly, the present embodiments are to be considered as illustrative and not restrictive, and the embodiments are not to be limited to the details given herein, but may be modified within the scope and equivalents of the appended claims.
Claims
- A method, comprising: receiving content for rendering in a head mounted display (HMD) of an HMD user;processing positional data of one or more spectators present in a real world space where the HMD user is located using a camera, the positional data usable to determine a location of the one or more spectators relative to the HMD user in the real world space;and generating an overhead view of the real world space, the overhead view is generated responsive to a possible encroachment by the HMD user of a personal space of one or more of the spectators present in the real world space, the overhead view identifying a position of the HMD user that is tracked relative to a position of said one or more of the spectators;wherein said overhead view provides an identification of the possible encroachment of the one or more spectators.
- The method of claim 1, wherein said identification of the possible encroachment is rendered along with the content in the HMD.
- The method of claim 2, wherein the identification is associated with an alert to draw attention to said possible encroachment.
- The method of claim 1, further comprising, determining that one or more points of interest in the content are in a direction or proximity that corresponds to the personal space of the spectator in the real world space;and generating an alert to the HMD user when the HMD user moves in said direction or proximity.
- The method of claim 1, wherein the overhead view includes a bird's-eye-view.
- The method of claim 1, wherein identification is associated with an audible alert presented to the HMD user as a warning.
- The method of claim 6, wherein the audible alert is accompanied with an animation.
- The method of claim 1, further comprising: providing, to the HMD for presentation within the content, instruction for repositioning, the instruction for reposition including a visual or audible prompt indicating how the HMD user is to move in order to avoid encroaching on the personal space of the spectator.
- A method, comprising: receiving a scene by a head mounted display (HMD) of an HMD user;receiving image data of a real world space where the HMD user is located, the image data being analyzed to identify positional data on the one or more spectators present in the real world space;identifying, based on the positional data, that a personal space of a spectator is being encroached by the HMD user, the identifying providing a map of the real world space that includes an image representing a position of the HMD user and a position of the spectator relative to the position of the HMD user, wherein an indicator is displayed in the map to alert the HMD user of said encroachment of said personal space of the spectator.
- The method of claim 9, wherein the alert is provided with a representation of the spectator whose personal space is being encroached.
- The method of claim 9, further comprising: providing an instruction to the HMD regarding an option for repositioning by the HMD user to avoid further encroaching on the personal space of the spectator.
- The method of claim 10, wherein the representation is based on said image data captured of the spectator in the real world space.
- The method of claim 10, wherein the representation is displayed at a display location within the scene that corresponds to a real world location of the spectator.
- The method of claim 9, wherein the image data is captured of the spectator using one or more front facing cameras on the HMD.
- The method of claim 9, further comprising: providing, to the HMD for presentation, instructions for producing an audible alert upon determined that the personal space of the spectator is being encroached.
- The method of claim 9, further comprising: detecting, within the scene, that one or more points of interest of the HMD user within the scene have a first display location that corresponds to the personal space of the spectator.
- The method of claim 16, further comprising: moving, within the scene, at least one of the one or more points of interest within the scene to a second display location within the scene, the second display location not corresponding to the personal space of the spectator.
Disclaimer: Data collected from the USPTO and may be malformed, incomplete, and/or otherwise inaccurate.