U.S. Pat. No. 11,890,538
SCALABLE GAME CONSOLE CPU / GPU DESIGN FOR HOME CONSOLE AND CLOUD GAMING
AssigneeSony Interactive Entertainment LLC
Issue DateJuly 30, 2021
Illustrative Figure
Abstract
In a multi-GPU simulation environment, frame buffer management may be implemented by multiple GPUs rendering respective frames of video, or by rendering respective portions of each frame of video. One of the GPUs controls HDMI frame output by virtue of receiving frame information from the other GPU(s) and reading out complete frames through a physically connected HDMI output port. Or, the outputs of the GPUs can be multiplexed together.
Description
DETAILED DESCRIPTION This disclosure relates generally to computer ecosystems including aspects of consumer electronics (CE) device networks such as but not limited to distributed computer game networks, video broadcasting, content delivery networks, virtual machines, and machine learning applications. A system herein may include server and client components, connected over a network such that data may be exchanged between the client and server components. The client components may include one or more computing devices including game consoles such as Sony PlayStation® and related motherboards, portable televisions (e.g. smart TVs, Internet-enabled TVs), portable computers such as laptops and tablet computers, and other mobile devices including smart phones and additional examples discussed below. These client devices may operate with a variety of operating environments. For example, some of the client computers may employ, as examples, Orbis or Linux operating systems, operating systems from Microsoft, or a Unix operating system, or operating systems produced by Apple Computer or Google. These operating environments may be used to execute one or more browsing programs, such as a browser made by Microsoft or Google or Mozilla or other browser program that can access websites hosted by the Internet servers discussed below. Also, an operating environment according to present principles may be used to execute one or more computer game programs. Servers and/or gateways may include one or more processors executing instructions that configure the servers to receive and transmit data over a network such as the Internet. Or, a client and server can be connected over a local intranet or a virtual private network. A server or controller may be instantiated by a game console and/or one or more motherboards thereof such as a Sony PlayStation®, a personal computer, etc. Information may be exchanged over a network between the clients and servers. To this end and for ...
DETAILED DESCRIPTION
This disclosure relates generally to computer ecosystems including aspects of consumer electronics (CE) device networks such as but not limited to distributed computer game networks, video broadcasting, content delivery networks, virtual machines, and machine learning applications. A system herein may include server and client components, connected over a network such that data may be exchanged between the client and server components. The client components may include one or more computing devices including game consoles such as Sony PlayStation® and related motherboards, portable televisions (e.g. smart TVs, Internet-enabled TVs), portable computers such as laptops and tablet computers, and other mobile devices including smart phones and additional examples discussed below. These client devices may operate with a variety of operating environments. For example, some of the client computers may employ, as examples, Orbis or Linux operating systems, operating systems from Microsoft, or a Unix operating system, or operating systems produced by Apple Computer or Google. These operating environments may be used to execute one or more browsing programs, such as a browser made by Microsoft or Google or Mozilla or other browser program that can access websites hosted by the Internet servers discussed below. Also, an operating environment according to present principles may be used to execute one or more computer game programs.
Servers and/or gateways may include one or more processors executing instructions that configure the servers to receive and transmit data over a network such as the Internet. Or, a client and server can be connected over a local intranet or a virtual private network. A server or controller may be instantiated by a game console and/or one or more motherboards thereof such as a Sony PlayStation®, a personal computer, etc.
Information may be exchanged over a network between the clients and servers. To this end and for security, servers and/or clients can include firewalls, load balancers, temporary storages, and proxies, and other network infrastructure for reliability and security. One or more servers may form an apparatus that implement methods of providing a secure community such as an online social website to network members.
As used herein, instructions refer to computer-implemented steps for processing information in the system. Instructions can be implemented in software, firmware or hardware and include any type of programmed step undertaken by components of the system.
A processor may be any conventional general-purpose single- or multi-chip processor that can execute logic by means of various lines such as address lines, data lines, and control lines and registers and shift registers.
Software modules described by way of the flow charts and user interfaces herein can include various sub-routines, procedures, etc. Without limiting the disclosure, logic stated to be executed by a particular module can be redistributed to other software modules and/or combined together in a single module and/or made available in a shareable library.
Present principles described herein can be implemented as hardware, software, firmware, or combinations thereof; hence, illustrative components, blocks, modules, circuits, and steps are set forth in terms of their functionality.
Further to what has been alluded to above, logical blocks, modules, and circuits described below can be implemented or performed with a general purpose processor, a digital signal processor (DSP), a field programmable gate array (FPGA) or other programmable logic device such as an application specific integrated circuit (ASIC), discrete gate or transistor logic, discrete hardware components, or any combination thereof designed to perform the functions described herein. A processor can be implemented by a controller or state machine or a combination of computing devices.
The functions and methods described below, when implemented in software, can be written in an appropriate language such as but not limited to Java, C# or C++, and can be stored on or transmitted through a computer-readable storage medium such as a random access memory (RAM), read-only memory (ROM), electrically erasable programmable read-only memory (EEPROM), compact disk read-only memory (CD-ROM) or other optical disk storage such as digital versatile disc (DVD), magnetic disk storage or other magnetic storage devices including removable thumb drives, etc. A connection may establish a computer-readable medium. Such connections can include, as examples, hard-wired cables including fiber optics and coaxial wires and digital subscriber line (DSL) and twisted pair wires. Such connections may include wireless communication connections including infrared and radio.
Components included in one embodiment can be used in other embodiments in any appropriate combination. For example, any of the various components described herein and/or depicted in the Figures may be combined, interchanged or excluded from other embodiments.
“A system having at least one of A, B, and C” (likewise “a system having at least one of A, B, or C” and “a system having at least one of A, B, C”) includes systems that have A alone, B alone, C alone, A and B together, A and C together, B and C together, and/or A, B, and C together, etc.
Now specifically referring toFIG.1, an example system10is shown, which may include one or more of the example devices mentioned above and described further below in accordance with present principles. The first of the example devices included in the system10is a consumer electronics (CE) device such as an audio video device (AVD)12such as but not limited to an Internet-enabled TV with a TV tuner (equivalently, set top box controlling a TV). However, the AVD12alternatively may be an appliance or household item, e.g. computerized Internet enabled refrigerator, washer, or dryer. The AVD12alternatively may also be a computerized Internet enabled (“smart”) telephone, a tablet computer, a notebook computer, a wearable computerized device such as e.g. computerized Internet-enabled watch, a computerized Internet-enabled bracelet, other computerized Internet-enabled devices, a computerized Internet-enabled music player, computerized Internet-enabled head phones, a computerized Internet-enabled implantable device such as an implantable skin device, etc. Regardless, it is to be understood that the AVD12is configured to undertake present principles (e.g. communicate with other CE devices to undertake present principles, execute the logic described herein, and perform any other functions and/or operations described herein).
Accordingly, to undertake such principles the AVD12can be established by some or all of the components shown inFIG.1. For example, the AVD12can include one or more displays14that may be implemented by a high definition or ultra-high definition “4K” or higher flat screen and that may be touch-enabled for receiving user input signals via touches on the display. The AVD12may include one or more speakers16for outputting audio in accordance with present principles, and at least one additional input device18such as e.g. an audio receiver/microphone for e.g. entering audible commands to the AVD12to control the AVD12. The example AVD12may also include one or more network interfaces20for communication over at least one network22such as the Internet, an WAN, an LAN, etc. under control of one or more processors24such as one or more central processing units (CPUs), graphics processing units (GPUs), and combinations thereof. Note that a processing chip on a single die acting as a central processing unit (CPU) and graphics processing unit (GPU) may be referred to herein as an accelerated processing unit (APU).
The interface20may be, without limitation, a Wi-Fi transceiver, which is an example of a wireless computer network interface, such as but not limited to a mesh network transceiver. It is to be understood that the processor24controls the AVD12to undertake present principles, including the other elements of the AVD12described herein such as e.g. controlling the display14to present images thereon and receiving input therefrom. Furthermore, note the network interface20may be, e.g., a wired or wireless modem or router, or other appropriate interface such as, e.g., a wireless telephony transceiver, or Wi-Fi transceiver as mentioned above, etc.
In addition to the foregoing, the AVD12may also include one or more input ports26such as, e.g., a high definition multimedia interface (HDMI) port or a USB port to physically connect (e.g. using a wired connection) to another CE device and/or a headphone port to connect headphones to the AVD12for presentation of audio from the AVD12to a user through the headphones. For example, the input port26may be connected via wire or wirelessly to a cable or satellite source26aof audio video content. Thus, the source26amay be, e.g., a separate or integrated set top box, or a satellite receiver. Or, the source26amay be a game console or disk player containing content that might be regarded by a user as a favorite for channel assignation purposes described further below. The source26awhen implemented as a game console may include some or all of the components described below in relation to the CE device44.
The AVD12may further include one or more computer memories28such as disk-based or solid state storage that are not transitory signals, in some cases embodied in the chassis of the AVD as standalone devices or as a personal video recording device (PVR) or video disk player either internal or external to the chassis of the AVD for playing back AV programs or as removable memory media. Also in some embodiments, the AVD12can include a position or location receiver such as but not limited to a cellphone receiver, GPS receiver and/or altimeter30that is configured to e.g. receive geographic position information from at least one satellite or cellphone tower and provide the information to the processor24and/or determine an altitude at which the AVD12is disposed in conjunction with the processor24. However, it is to be understood that that another suitable position receiver other than a cellphone receiver, GPS receiver and/or altimeter may be used in accordance with present principles to e.g. determine the location of the AVD12in e.g. all three dimensions.
Continuing the description of the AVD12, in some embodiments the AVD12may include one or more cameras32that may be, e.g., a thermal imaging camera, a digital camera such as a webcam, and/or a camera integrated into the AVD12and controllable by the processor24to gather pictures/images and/or video in accordance with present principles. Also included on the AVD12may be a Bluetooth transceiver34and other Near Field Communication (NFC) element36for communication with other devices using Bluetooth and/or NFC technology, respectively. An example NFC element can be a radio frequency identification (RFID) element.
Further still, the AVD12may include one or more auxiliary sensors37(e.g., a motion sensor such as an accelerometer, gyroscope, cyclometer, or a magnetic sensor, an infrared (IR) sensor, an optical sensor, a speed and/or cadence sensor, a gesture sensor (e.g. for sensing gesture command), etc.) providing input to the processor24. The AVD12may include an over-the-air TV broadcast port38for receiving OTH TV broadcasts providing input to the processor24. In addition to the foregoing, it is noted that the AVD12may also include an infrared (IR) transmitter and/or IR receiver and/or IR transceiver42such as an IR data association (IRDA) device. A battery (not shown) may be provided for powering the AVD12.
Still referring toFIG.1, in addition to the AVD12, the system10may include one or more other CE device types. In one example, a first CE device44may be used to control the display via commands sent through the below-described server while a second CE device46may include similar components as the first CE device44and hence will not be discussed in detail. In the example shown, only two CE devices44,46are shown, it being understood that fewer or greater devices may be used. As alluded to above, the CE device44/46and/or the source26amay be implemented by a game console. Or, one or more of the CE devices44/46may be implemented by devices sold under the trademarks Google Chromecast, Roku, Amazon FireTV.
In the example shown, to illustrate present principles all three devices12,44,46are assumed to be members of an entertainment network in, e.g., a home, or at least to be present in proximity to each other in a location such as a house. However, for present principles are not limited to a particular location, illustrated by dashed lines48, unless explicitly claimed otherwise.
The example non-limiting first CE device44may be established by any one of the above-mentioned devices, for example, a portable wireless laptop computer or notebook computer or game controller (also referred to as “console”), and accordingly may have one or more of the components described below. The second CE device46without limitation may be established by a video disk player such as a Blu-ray player, a game console, and the like. The first CE device44may be a remote control (RC) for, e.g., issuing AV play and pause commands to the AVD12, or it may be a more sophisticated device such as a tablet computer, a game controller communicating via wired or wireless link with a game console implemented by the second CE device46and controlling video game presentation on the AVD12, a personal computer, a wireless telephone, etc.
Accordingly, the first CE device44may include one or more displays50that may be touch-enabled for receiving user input signals via touches on the display. The first CE device44may include one or more speakers52for outputting audio in accordance with present principles, and at least one additional input device54such as e.g. an audio receiver/microphone for e.g. entering audible commands to the first CE device44to control the device44. The example first CE device44may also include one or more network interfaces56for communication over the network22under control of one or more CE device processors58such as one or more CPUs, GPUs, and combinations thereof. Thus, the interface56may be, without limitation, a Wi-Fi transceiver, which is an example of a wireless computer network interface, including mesh network interfaces. It is to be understood that the processor58controls the first CE device44to undertake present principles, including the other elements of the first CE device44described herein such as e.g. controlling the display50to present images thereon and receiving input therefrom. Furthermore, note the network interface56may be, e.g., a wired or wireless modem or router, or other appropriate interface such as, e.g., a wireless telephony transceiver, or Wi-Fi transceiver as mentioned above, etc.
In addition to the foregoing, the first CE device44may also include one or more input ports60such as, e.g., a HDMI port or a USB port to physically connect (e.g. using a wired connection) to another CE device and/or a headphone port to connect headphones to the first CE device44for presentation of audio from the first CE device44to a user through the headphones. The first CE device44may further include one or more tangible computer readable storage medium62such as disk-based or solid-state storage. Also in some embodiments, the first CE device44can include a position or location receiver such as but not limited to a cellphone and/or GPS receiver and/or altimeter64that is configured to e.g. receive geographic position information from at least one satellite and/or cell tower, using triangulation, and provide the information to the CE device processor58and/or determine an altitude at which the first CE device44is disposed in conjunction with the CE device processor58. However, it is to be understood that that another suitable position receiver other than a cellphone and/or GPS receiver and/or altimeter may be used in accordance with present principles to e.g. determine the location of the first CE device44in e.g. all three dimensions.
Continuing the description of the first CE device44, in some embodiments the first CE device44may include one or more cameras66that may be, e.g., a thermal imaging camera, a digital camera such as a webcam, and/or a camera integrated into the first CE device44and controllable by the CE device processor58to gather pictures/images and/or video in accordance with present principles. Also included on the first CE device44may be a Bluetooth transceiver68and other Near Field Communication (NFC) element70for communication with other devices using Bluetooth and/or NFC technology, respectively. An example NFC element can be a radio frequency identification (RFID) element.
Further still, the first CE device44may include one or more auxiliary sensors72(e.g., a motion sensor such as an accelerometer, gyroscope, cyclometer, or a magnetic sensor, an infrared (IR) sensor, an optical sensor, a speed and/or cadence sensor, a gesture sensor (e.g. for sensing gesture command), etc.) providing input to the CE device processor58. The first CE device44may include still other sensors such as e.g. one or more climate sensors74(e.g. barometers, humidity sensors, wind sensors, light sensors, temperature sensors, etc.) and/or one or more biometric sensors76providing input to the CE device processor58. In addition to the foregoing, it is noted that in some embodiments the first CE device44may also include an infrared (IR) transmitter and/or IR receiver and/or IR transceiver78such as an IR data association (IRDA) device. A battery (not shown) may be provided for powering the first CE device44. The CE device44may communicate with the AVD12through any of the above-described communication modes and related components.
The second CE device46may include some or all of the components shown for the CE device44. Either one or both CE devices may be powered by one or more batteries.
Now in reference to the afore-mentioned at least one server80, it includes at least one server processor82, at least one tangible computer readable storage medium84such as disk-based or solid-state storage. In an implementation, the medium84includes one or more SSDs. The server also includes at least one network interface86that allows for communication with the other devices ofFIG.1over the network22, and indeed may facilitate communication between servers and client devices in accordance with present principles. Note that the network interface86may be, e.g., a wired or wireless modem or router, Wi-Fi transceiver, or other appropriate interface such as, e.g., a wireless telephony transceiver. The network interface86may be a remote direct memory access (RDMA) interface that directly connects the medium84to a network such as a so-called “fabric” without passing through the server processor82. The network may include an Ethernet network and/or Fibre Channel network and/or InfiniBand network. Typically, the server80includes multiple processors in multiple computers referred to as “blades” that may be arranged in a physical server “stack”.
Accordingly, in some embodiments the server80may be an Internet server or an entire “server farm” and may include and perform “cloud” functions such that the devices of the system10may access a “cloud” environment via the server80in example embodiments for, e.g., network gaming applications. Or, the server80may be implemented by one or more game consoles or other computers in the same room as the other devices shown inFIG.1or nearby.
The methods herein may be implemented as software instructions executed by a processor, suitably configured application specific integrated circuits (ASIC) or field programmable gate array (FPGA) modules, or any other convenient manner as would be appreciated by those skilled in those art. Where employed, the software instructions may be embodied in a non-transitory device such as a CD ROM or Flash drive. The software code instructions may alternatively be embodied in a transitory arrangement such as a radio or optical signal, or via a download over the internet.
FIG.2illustrates an example application in the form of a cloud computer game environment in which one or more client game consoles200(also referred to as “game systems”, “game devices”) such as Sony PlayStations®, Microsoft Xboxes®, etc. communicate over a wired and/or wireless link with a cloud-based gaming management server202, typically an Internet server. In turn, the management server202communicates with a first game server204(which may be embodied by multiple server “blades”) that includes one or more solid state memories206such as a random-access memory (RAM) including NVMe-enabled SSDs that use solid state memory such as but not limited to flash or 3D Xpoint. The management server202communicates with up to “N” such servers, including an Nthgame server212that includes one or more solid state memories214.
Example Architectures
FIG.3illustrates an example non-uniform memory access (NUMA) architecture, in which a single fabric300holds two APUs302,304on a single die or on respective dies, it being understood that the NUMA architecture may be implemented by more than two APUs. When implemented on respective die chips on the same fabric300, communication paths, which may be referred to as “busses” for generality, may be established by via layers of the fabric.
As shown, each APU may include one or more CPUs304and one or more GPUs306, typically one CPU and one GPU per APU. Each APU302may be associated with its own respective memory controller308that controls access to memory310such as random-access memory (RAM). Communication between APUs may be affected by one or more communication paths312, referred to herein for convenience as “busses”.
Thus, each APU (or individual GPU) has its own memory controller and hence its own dedicated memory, such as RAM. There can be a (cache-coherent) shared bus between the GPUs, allowing one GPU to access memory of the other GPU.
FIG.4is a block diagram of a shared memory architecture in which two APUs each including a CPU400and GPU402are shown with each CPU and each GPU being implemented on its own respective die, it being understood that the architecture may be implemented on fewer or even one die and that more than two APUs may be implemented. The APUs share a common memory controller404that controls a memory406, and the APUs may communicate with each other and with the memory controller over respective communication paths.
FIG.5is a block diagram of a shared memory architecture in which two APUs (each including a respective CPU502and GPU504) are shown with each APU being implemented on its own respective die500and with a shared memory controller506being implemented on one of the dies500, it being understood that the architecture may be implemented on one die and that more than two APUs may be implemented. The shared memory controller506controls access to a memory508, and the APUs may communicate with each other and with the memory controller506over one or more communication paths510.
FIG.6is a block diagram of an example GPU600with a scanout unit602. The scanout unit602can include plural registers604that point to respective memory buffers (or equivalently buffer IDs)606. A video encoder608may communicate with the scanout unit602. The video encoder608is particularly applicable to a cloud gaming scenario for allowing encoding of the same image as would normally have been output on HDMI.
The scanout unit602is responsible for outputting the pixels of each frame of video, line by line, for example to HDMI. As more fully discussed below, the scanout unit can be programmed to read the correct video frame. It maintains the set of registers604for this, with each register pointing to a different buffer606and with the scanout unit cycling through the buffers.
Frame Buffer Management
As will be presently discussed more fully, there are multiple approaches on how multiple GPUs work together to manage frame buffers. Each GPU may render a different frame of the video than the other GPU. Or, each GPU may render a different part of the same frame, e.g., the top 1 through N lines of a frame may be rendered by the first GPU and the bottom N+1 through M lines of the same frame may be rendered by the second GPU. Other patterns/portions between the GPUs may be used.
FIG.7is a flow chart of example logic of a NUMA embodiment in which each GPU renders complete frames with each GPU rendering different frames of the same video than the other GPU, with one of the GPUs having registers pointing to buffers of the other GPU(s). Commencing at block700, the operating system and/or GPU drivers assign memory regions to be used as a framebuffer. Typically, a framebuffer consists of at least two buffers (more add latency). One buffer is used for the currently displayed frame to be output, e.g., over HDMI, while a second buffer can be used for rendering of the next frame. There can be additional depth buffers and other buffers if desired.
InFIG.7, the GPU driver and/or simulation program (e.g., computer game) sends rendering commands to alternate between the GPUs. The GPU driver or game manages this by commanding the first GPU to render every odd-numbered frame and the second GPU to render every even-numbered frame.
In such an implementation, the logic may move to block702to program the registers of the scanout unit such that each register points to a memory buffer managed by a different GPU. Proceeding to block704, the GPU cycles through the buffers it manages and those managed by other GPUs as pointed to by the registers of the cycling GPU to output all the frames of the video, which may be in HDMI. It is to be appreciated that when more than two GPUs are used, the number of frames rendered by each GPU may be reduced accordingly, e.g., each of N GPUs may render1/N frames of a video with each GPU rendering different frames than are rendered by the other GPUs.
FIG.8illustrates an alternate approach in which the scanout unit only scans frames out from the “local” GPU its memory. As was the case inFIG.7, at block800inFIG.8the operating system and/or GPU drivers assign memory regions to be used as a framebuffer. Moving to block802, however, the registers of the first GPU are programmed to point only to buffers local to that GPU, with frames from the second GPU being copied over via direct memory access (DMA) to the first GPU upon completion of rendering of the frames at block804. Note that the “first” GPU may be established by the first GPU which copies the frame based on an interrupt (to notify frame completion) from the second GPU. Proceeding to block806, the first GPU cycles through the buffers it manages, and the frames received via DMA at block804from the second GPU to output all the frames of the video, which may be in HDMI.
Note that in a shared memory controller architecture such as those shown inFIGS.4and5, there is no need to copy frames over as there is no issue for the scanout unit to read the data. The timing is the same no matter which GPU rendered it.
FIG.9is a flow chart of example logic of a NUMA embodiment in which each GPU renders portions (e.g., lines) of frames with each GPU rendering different portions of the same frame than the other GPU. Commencing at block900, a first GPU renders a first portion of a frame, such as the first N lines (lines1through N) while at block902the second GPU renders a different portion of the same frame, for example, lines N+1 through M (the last line). It is to be appreciated that when more than two GPUs are used, the portions of a frame rendered by each GPU is reduced accordingly. In any case, at block904the complete frame (lines1through M) is output by the first GPU.
To affect the above, the scanout unit can be modified to reading from multiple buffers per frame, each managed by a different GPU. The scanout unit may thus be programmed to generate the first “N” lines from a first buffer (which may be to its own internal rendering), and the next N lines from a second buffer, which may that associated with the second GPU.
FIG.10illustrates another alternate approach similar to that ofFIG.9except that the second GPU DMA's memory over to a portion of the first GPU its video buffers. Accordingly, at block1000, a first GPU renders a first portion of a frame, such as the first N lines (lines1through N) while at block1002the first GPU receives via DMA from the second GPU a different portion of the same frame, for example, lines N+1 through M (the last line). At block1004the complete frame (lines1through M) is output by the first GPU.
FIG.11is a flow chart of example logic of a shared memory embodiment in which each GPU renders portions (e.g., lines) of frames with each GPU rendering different portions of the same frame than the other GPU. Thus, at block1100the first GPU renders the first portion of a frame to a buffer, and at block1102the second GPU renders the second portion of the same frame to the same buffer. At block1104the complete frame (lines1through M) is output by the shared buffer.
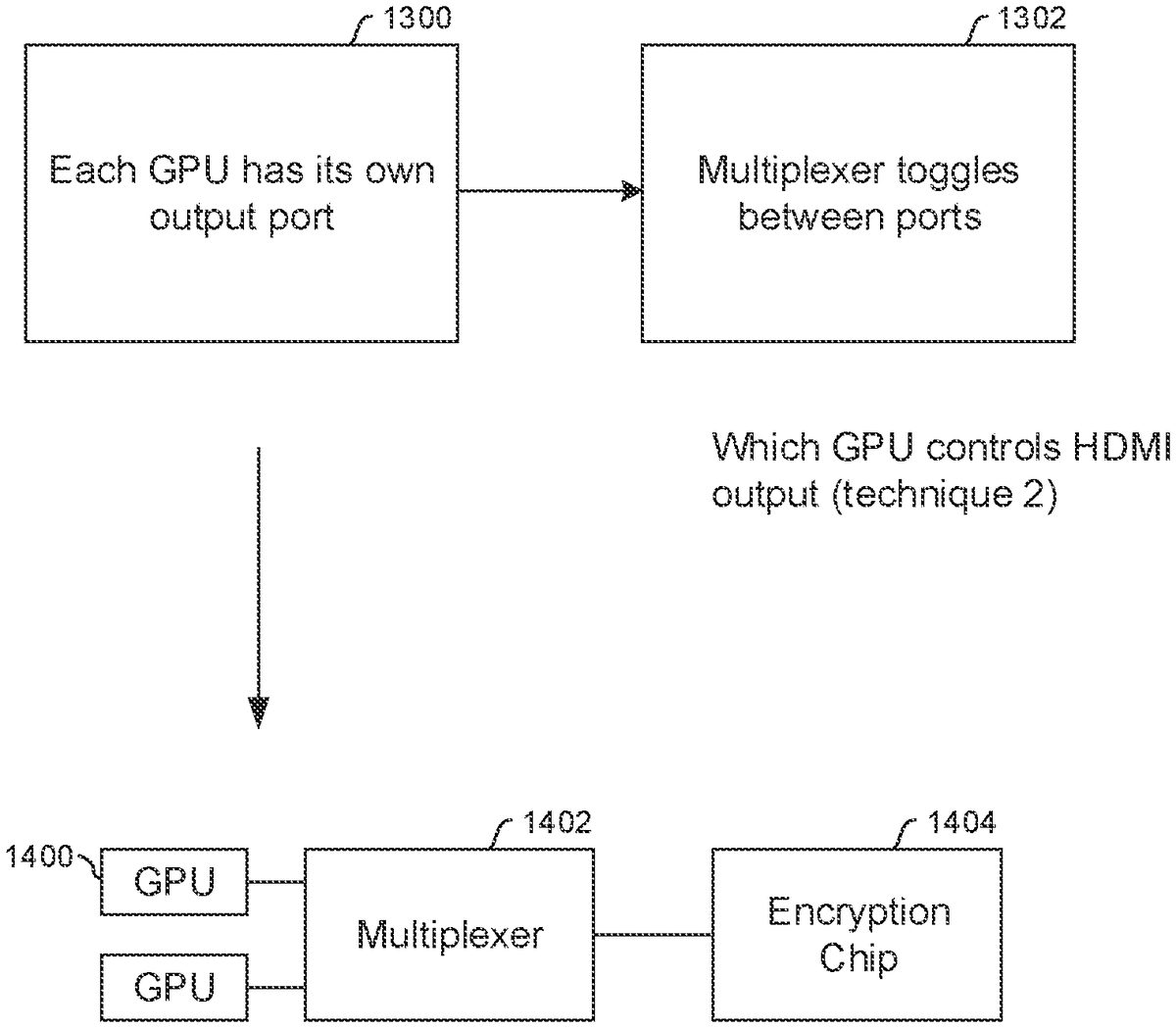
Determining which GPU Controls HDMI OutputFIG.12illustrates that a first approach to determining which GPU manages the output includes, at block1200, simply physically connecting, at manufacture time, the HDMI (or DisplayPort) output to a particular GPU. The mapping is thus controlled at manufacturing time.
FIGS.13and14illustrate that in another approach, at block1300inFIG.13each GPU1400(shown inFIG.14) is implemented with its own respective video output. The outputs of the GPUs1400are multiplexed at block1302by one or more multiplexers1402that toggles between both GPU output ports.
Recognizing that signals are often encrypted, an encryption chip1404may be provided to receive the output of the multiplexer1402to address encryption. Essentially, the multiplexed output may establish a DisplayPort signal that is converted by the encryption chip1404to HDMI.
Video Composition
As understood herein, user experience (UX) graphics and simulation (e.g., game) video can both be rendered across the different GPUs. Given that UX rendering typically is not demanding, only a single GPU need render the UX, typically the GPU that is selected for also handling the HDMI output in the preceding section. This GPU composes the final frame buffer image to contain the UX and the game. The game, its framebuffer, may depend on the frame. The composition engine may read memory directly from the memory of each GPU or from the shared memory controller.
Power Management
Power management techniques may be implemented to lower thermal loads by restricting power consumption. Recognizing that power consumption varies linearly with frequency and as the square of the voltage, a computer simulation program such as a video game may be programmed to be responsible for maintaining power consumption within predetermined thresholds by reducing frequency and/or voltage automatically as frequency/voltage/power thresholds are approached. To do this, registers from the hardware such as one or more GPUs may be read to determine current usage allocation, throttling certain effects such as particle effects if needed. The same principles can apply to mobile telephones as well. Throttling may be implemented by over clock techniques, and GPUs may be throttled independently of CPUs in the architecture. Resolution of video may be reduced to maintain simulation execution while staying within power consumption-related thresholds. Audio and/or visual warnings (such as activating an LED) may be presented as power consumption-related thresholds are approached.
Users may be permitted to pay extra for additional thermal budgets. Similarly, a user may be allocated more dies (and hence more APUs) on a cloud server by paying extra fees, with only a single die being allocated to lower-paying users. This may be done when an application starts by programming an API to call for system metrics and spawn threads and determine quality of service based on the metrics. System metrics can be filtered for lower-paying users who are allocated for fewer dies. Higher-paying users desiring the benefit of a multi-threaded game with simultaneous processing can be allocated more dies than lower-paying users.
It will be appreciated that whilst present principals have been described with reference to some example embodiments, these are not intended to be limiting, and that various alternative arrangements may be used to implement the subject matter claimed herein.
Claims
- An apparatus comprising: at least a first graphics processing unit (GPU);at least a second GPU communicatively coupled to the first GPU;wherein the GPUs are programmed to: render respective portions of video, such that the first GPU renders first portions of video and the second GPU renders second portions of video, the first and second portions being different from each other, wherein the first GPU is programmed to combine the first and second portions to render an output establishing a combined video, the combined video rendered by throttling, using one or more over clock techniques, at least one effect based at least in part on a current GPU usage allocation, wherein throttling at least one effect comprises throttling at least one particle effect.
- The apparatus of claim 1, wherein the first and second GPUs are implemented on a common die.
- The apparatus of claim 1, wherein the first GPU is associated with a first central processing unit (CPU) and the second GPU is associated with a second CPU.
- The apparatus of claim 1, comprising a first memory controller and first memory associated with the first GPU and a second memory controller and second memory associated with the second GPU.
- The apparatus of claim 1, wherein the GPUs share a common memory controller controlling a common memory.
- The apparatus of claim 5, wherein the first GPU comprises at least one scanout unit pointing to at least a first buffer communicating with the common memory controller, the second GPU comprises a second buffer communicating with the common memory controller, the first GPU rendering 1-N lines associated with the first buffer and the second GPU rendering (N+1)-M lines associated with the second buffer, the 1-N lines and (N+1)-M lines being different lines of the frame of video.
- The apparatus of claim 1, wherein each GPU is programmed to render all of some, but not all, frames of video different from frames of video rendered by the other GPU to provide a respective output, the outputs of the GPUs being combined to render the combined video.
- The apparatus of claim 7, wherein the first GPU comprises at least one scanout unit pointing to at least one buffer managed by the second GPU, the first GPU programmed to cycle through buffers to output a complete sequence of frames of the combined video.
- The apparatus of claim 7, wherein the first GPU comprises at least one scanout unit pointing only to buffers managed by the first GPU, the first GPU programmed to receive frames of video from the second GPU via direct memory access (DMA) and output a complete sequence of frames as the combined video.
- The apparatus of claim 1, wherein each GPU is programmed to render all of some, but not all, lines of a frame of video, lines of a frame of video rendered by a GPU being different from lines of the frame rendered by the other GPU to provide a respective output, the outputs of the GPUs for being combined to render the combined video.
- The apparatus of claim 1, wherein the first GPU comprises at least one scanout unit pointing to at least a first buffer managed by the first GPU and a second buffer managed by the second GPU, the first GPU programmed to cycle through buffers to output a complete sequence of frame of video using 1-N lines associated with the first buffer and (N+1) -M lines associated with the second buffer, the 1-N lines and (N+1)-M lines being different lines of the frame of video.
- The apparatus of claim 1, wherein the first GPU comprises at least one scanout unit pointing to at least a first buffer managed by the first GPU and not to a second buffer managed by the second GPU, the first GPU programmed to cycle through buffers to output a complete sequence of frame of video using 1-N lines associated with the first buffer and (N+1)-M lines associated with the second buffer and received by the first GPU via direct memory access (DMA), the 1-N lines and (N+1)-M lines being different lines of the frame of video.
- The apparatus of claim 1, wherein the first GPU also manages high definition multimedia interface (HDMI) output of the combined video.
- In a multi-graphics processing unit (GPU) simulation environment, a method comprising: causing plural GPUs to render respective frames of video, or to render respective portions of each frame of video, or to render respective frames and respective portions of frames of video;controlling frame output using a first one of the GPUs receiving frame information from at least one other of the GPU(s), or multiplexing outputs of the GPUs together, or both using a first one of the GPUs receiving frame information from at least one other of the GPU(s) and multiplexing outputs of the GPUs together, wherein the first one of the GPUs combines respective video components from the GPUs to render a combined video, the combined video rendered by throttling, using one or more over clock techniques, at least one effect based at least in part on a current usage allocation, wherein throttling at least one effect comprises throttling at least one particle effect.
- The method of claim 14, wherein the first one of the GPUs also manages high definition multimedia interface (HDMI) output of the final frame buffer images.
- A computer simulation apparatus, comprising: at least a first graphics processing unit (GPU) programmed for rendering a respective first portion of simulation video;at least a second GPU programmed for rendering a respective second portion of simulation video;and at least the first GPU programmed to combine the first and second portions and to render an output establishing a complete simulation video, the first GPU reading registers from at least one of the GPUs to determine current usage allocation and throttling, using one or more over clock techniques, at least one effect of the complete simulation video based at least in part on the current usage allocation.
- The computer simulation apparatus of claim 16, wherein the computer simulation apparatus provides users with extra power consumption limits based on remuneration from the users.
- The computer simulation apparatus of claim 16, wherein throttling at least one effect comprises reducing resolution of one or more video frames.
- The computer simulation apparatus of claim 16, wherein the computer simulation apparatus presents audio and/or visual warnings as a power consumption-related threshold is approached.
- The computer simulation apparatus of claim 19, wherein the computer simulation apparatus presents a visual warning as the power consumption-related threshold is approached, the visual warning presented by activating a light-emitting diode.
Disclaimer: Data collected from the USPTO and may be malformed, incomplete, and/or otherwise inaccurate.