U.S. Pat. No. 11,790,884
Generating Speech in the Voice of a Player of a Video Game
AssigneeELECTRONIC ARTS INC.
Issue DateOctober 28, 2020
Illustrative Figure
Abstract
A computer-implemented method of generating speech audio in a video game is provided. The method includes inputting, into a synthesizer module, input data that represents speech content. Source acoustic features for the speech content in the voice of a source speaker are generated and are input, along with a speaker embedding associated with a player of the video game into an acoustic feature encoder of a voice convertor. One or more acoustic feature encodings are generated as output of the acoustic feature encoder, which are inputted into an acoustic feature decoder of the voice convertor to generate target acoustic features. The target acoustic features are processed with one or more modules, to generate speech audio in the voice of the player.
Description
DETAILED DESCRIPTION General Definitions The following terms are defined to aid the present disclosure and not limit the scope thereof. A “user” or “player”, as used in some embodiments herein, refers to an individual and/or the computing system(s) or device(s) corresponding to (e.g., associated with, operated by) that individual. A “client” as used in some embodiments described herein, is a software application with which a user interacts, and which can be executed on a computing system or device locally, remotely, or over a cloud service. A “server” as used in some embodiments described here, is a software application configured to provide certain services to a client, e.g. content and/or functionality. A “video game” as used in some embodiments described herein, is a virtual interactive environment in which players engage. Video game environments may be facilitated through a client-server framework in which a client may connect with the server to access at least some of the content and functionality of the video game. “Speech” as used in some embodiments described herein may include sounds in the form of spoken words in any language, whether real or invented and/or other utterances including paralinguistics such as sighs, yawns, moans etc. “Speech audio” refers to audio (e.g. audio data) which includes or represents speech, and may comprise data in any suitable audio file format whether in a compressed or uncompressed format. “Text” as used in some in embodiments described herein refers to any suitable representation of characters, words or symbols that may be used to represent language and/or speech. In some cases, text may be input by use of a keyboard and/or stored in memory in the form of text data. Text may comprise text data in any suitable compressed or uncompressed format, e.g. ASCII format. A “speech audio generator” as used in some ...
DETAILED DESCRIPTION
General Definitions
The following terms are defined to aid the present disclosure and not limit the scope thereof.
A “user” or “player”, as used in some embodiments herein, refers to an individual and/or the computing system(s) or device(s) corresponding to (e.g., associated with, operated by) that individual.
A “client” as used in some embodiments described herein, is a software application with which a user interacts, and which can be executed on a computing system or device locally, remotely, or over a cloud service.
A “server” as used in some embodiments described here, is a software application configured to provide certain services to a client, e.g. content and/or functionality.
A “video game” as used in some embodiments described herein, is a virtual interactive environment in which players engage. Video game environments may be facilitated through a client-server framework in which a client may connect with the server to access at least some of the content and functionality of the video game.
“Speech” as used in some embodiments described herein may include sounds in the form of spoken words in any language, whether real or invented and/or other utterances including paralinguistics such as sighs, yawns, moans etc. “Speech audio” refers to audio (e.g. audio data) which includes or represents speech, and may comprise data in any suitable audio file format whether in a compressed or uncompressed format.
“Text” as used in some in embodiments described herein refers to any suitable representation of characters, words or symbols that may be used to represent language and/or speech. In some cases, text may be input by use of a keyboard and/or stored in memory in the form of text data. Text may comprise text data in any suitable compressed or uncompressed format, e.g. ASCII format.
A “speech audio generator” as used in some embodiments described herein, is a software module that receives an indication of an utterance and outputs speech audio corresponding to the indication. Various characteristics of the output speech audio may be varied by speech audio generator modules described herein, e.g. speech content, speaker identity, and speech style (for example the prosody of the output speech).
“Acoustic features” as used in some embodiments described herein may include any suitable acoustic representation of frequency, magnitude and/or phase information. For example, acoustic features may comprise linear spectrograms, log-mel-spectrograms, linear predictive coding (LPC) coefficients, Mel-Frequency Cepstral Coefficients (MFCC), log fundamental frequency (LFO), band aperiodicity (bap) or combinations thereof.
Example implementations provide systems and methods for generating speech audio in a video game, using a voice convertor to generate acoustic features for a player of the video game. Specifically, the voice convertor is configured to convert acoustic features relating to a source speaker into acoustic features for the player.
Some previous approaches to generating speech audio in a particular voice make use of a text-to-speech system which includes a synthesizer. The synthesizer receives text and outputs acoustic features used to synthesize speech audio corresponding to the text. However, such approaches usually require many speech samples (e.g. hours of speech samples) in order for the synthesizer to accurately capture the voice in the synthesized speech audio. In addition, existing approaches may require retraining of the synthesizer (or the entirety of the text-to-speech system) when training to generate speech audio in a different voice. Furthermore, existing text-to-speech systems may not capture the variety in performance (e.g. speaking style, such as prosody) of real speech audio.
In contrast, systems and methods as described in this specification enable speech audio to be generated in the voice of a player of a video game, using speech audio provided by the player (e.g. a small amount of speech audio such as minutes of speech audio from the player), and a voice convertor.
Example systems described in this specification include a synthesizer and a vocoder in addition to the voice convertor. The synthesizer receives input data representing speech content, and optionally, speech style features, and outputs acoustic features for the speech content, taking into account the (optional) speech style features. The acoustic features are processed by the vocoder to output speech audio corresponding to the acoustic features. The synthesizer and vocoder may be pre-trained using recordings or input from speakers for whom there are many speech samples, enabling the learning of an accurate/realistic mapping to the audio domain. Generally, the acoustic features output by the synthesizer closely match the characteristics of the acoustic features used to train the synthesizer. After refining the voice convertor with speech samples provided by the player, the voice convertor is used to convert/transform source acoustic features output by the synthesizer into target acoustic features corresponding to the player's voice. The target acoustic features are subsequently processed and the vocoder outputs the speech audio in the player's voice.
Various example implementations may allow speech audio to be generated in a player's voice using a small set of speech samples from the player relative to the number of speech samples required by other systems which do not employ a voice convertor as described herein. For example, training the speech audio generator system may use fewer computational resources than previous approaches which require more speech samples. In particular, using a voice convertor in the described systems and methods enables the addition of a player's voice to a speech audio generator system without requiring training of the synthesizer and/or vocoder, obviating the computational resources required to refine these components. In addition, in implementations where player speech samples (or indications thereof, e.g. acoustic features) are transmitted via a network, transmitting a small number of player speech samples may also use fewer network resources and consume less network bandwidth.
Methods and systems described herein also enable the learning of an accurate representation of a speaker's voice in the form of a speaker embedding. By learning a suitable speaker embedding for each speaker, and inputting this along with source acoustic features into the voice convertor module, the performance of the source speech audio (e.g. prosody) may be retained while realistically transforming the voice of the source speech audio into that of the player.
Example Video Game Environment
FIG.1illustrates an example of a computer system configured to provide a video game environment100to players of a video game.
The video game environment100includes video game server apparatus109, and one or more client computing devices101. Each client computing device101is operable by a user and provides a client in the form of gaming application102to the user. The client computing device101is configured to communicate with the video game server apparatus109which provides a game server114for providing content and functionality to the gaming application102. For the sake of clarity, the video game environment100is illustrated as comprising a specific number of devices. Any of the functionality described as being performed by a specific device may instead be performed across a number of computing devices, and/or functionality described as being performed by multiple devices may be performed on a single device. For example, multiple instances of the video game server apparatus109(or components thereof) may be hosted as virtual machines or containers on one or more computing devices of a public or private cloud computing environment.
The video game server apparatus109provides speech audio generator100. The speech audio generator receives input data representing speech content (e.g. an indication of an utterance to be synthesized as output), player identifier data for the player, and optionally, speech style features, and outputs speech audio in the player's voice corresponding to the speech content. The speech content may be determined from output of the speech content input module103, and/or from speech scripts108,117. The player identifier data is any data that can be associated with (e.g. used to identify) an individual player. In some embodiments, the player identifier data is a speaker identifier, which may be for example, a different one-hot vector for each speaker whose voice can be synthesized in output of the speech audio generator110. In other embodiments, the player identifier data are speech samples (or indications thereof, e.g. acoustic features) provided by that particular player. In some examples, the speech audio generator comprises a text-to-speech module configured to receive text data representing speech content, player identifier data for the player, and optionally, speech style features, and to output speech audio in the voice of the player.
The client computing device101can be any computing device suitable for providing the gaming application102to the user. For example, the client computing device101may be any of a laptop computer, a desktop computer, a tablet computer, a video games console, or a smartphone. For displaying the graphical user interfaces of computer programs to the user, the client computing device includes or is connected to a display (not shown). Input device(s) (not shown) are also included or connected to the client. Examples of suitable input devices include keyboards, touchscreens, mice, video game controllers, microphones and cameras.
Gaming application102provides a video game to the user of the client computing device101. The gaming application102may be configured to cause the client computing device101to request video game content from the video game server apparatus109while the user is playing the video game. Requests made by the gaming application102are received at the request router115of game server114, which processes the request, and returns a corresponding response (e.g. synthesized speech audio generated by the speech audio generator110) to gaming application102. Examples of requests include Application Programming Interface (API) requests, e.g. a representational state transfer (REST) call, a Simple Object Access Protocol (SOAP) call, a message queue; or any other suitable request.
The gaming application102provides a speech content input module103for use by user of computing device101. The speech content input module103is configured to enable the player of the video game to input any data (e.g. text, and/or tags for paralinguistic utterances) for use in speech synthesis in their voice. The speech content input module103transmits data representing speech content to the request router115, which is subsequently transmitted to the speech audio generator110.
The data representing speech content may comprise text data. The text data may be any digital data representing text. Additionally or alternatively, the data representing speech content may comprise one or more indications of paralinguistic information. Any paralinguistic utterance may be indicated in the speech content, such as sighs, yawns, moans, laughs, grunts, etc. The speech content may be encoded by a sequence of vectors with each vector representing a character of the speech content. For example, a character may be a letter, a number, and/or a tag indicating a paralinguistic utterance. The elements of a character vector may correspond with one character out of a set of possible characters, with each character represented by a character vector with only one non-zero element (also known as a one-hot vector). Additionally or alternatively, the speech content may be represented by continuous embeddings, e.g. character embeddings and/or word embeddings. Generally, embeddings are vectors of a learned embedding space. Phoneme information may also be included in the input data, which may be determined by the speech audio generator no.
The gaming application102provides an audio input module104for use by the user of computing device101. The audio input module104is configured to enable the player of the video game to input player speech samples for use in refining the voice convertor112(or components thereof) of speech audio generator110. The audio input module104transmits player speech audio to the request router115, which is subsequently transmitted to the speech audio generator no. The player speech audio may be any suitable digital data and may for example represent a waveform of the player speech samples (e.g. transmitted as an MP3 file, a WAV file, etc). The player speech audio may comprise acoustic features of the player speech sample. Acoustic features may comprise any low-level acoustic representation of frequency, magnitude and phase information such as linear spectrograms, log-mel-spectrograms, linear predictive coding (LPC) coefficients, Mel-Frequency Cepstral Coefficients (MFCC), log fundamental frequency (LFO), band aperiodicity (bap) or combinations thereof. The acoustic features may comprise a sequence of vectors, each vector representing acoustic information in a short time period, e.g. 50 milliseconds.
The gaming application102provides an audio receiver module105configured to receive output of the speech audio generator no. The audio receiver module105may be configured to request speech audio from the speech audio generator110throughout different stages of the video game. For example, some of the speech content may be predetermined (e.g. stored in speech scripts108,117) and so the audio receiver module105may request synthesized speech audio for the predetermined content at the same time, e.g. during a loading process. As another example, the audio receiver module105may request synthesized speech audio subsequent to the player inputting data into speech content input module103. The speech audio may be received at the audio receiver module105as a waveform (e.g. represented in an MP4 file, a WAV file, etc).
The gaming application102comprises game content106accessed while the video game is being played by the player. The game content106includes speech audio107, and speech script108, and other assets such as markup-language files, scripts, images and music. The speech audio107comprises audio data for entities/characters in the video game, which may be output by the gaming application102at appropriate stages of the video game, e.g. if a player decides not to add their voice to speech audio generator110. The speech audio107(or a portion thereof) has corresponding speech scripts108which are transcriptions of the speech audio107.
The speech audio107and/or speech scripts108are also used when the player is adding their voice to speech audio generator110. During an initialization process, the player is provided with examples of speech audio107and/or speech script108and is asked to provide player speech samples corresponding to the speech audio107and/or speech script108, which samples are used to refine (i.e. further train) the voice convertor112(or components thereof). For example, a transcript may be provided from speech script108for the user to recite. Additionally, or alternatively, the user may be asked to mimic an example of speech audio107such that the player speaks the same words as the example, in a speech style (e.g. prosody) similar to that of the example. The resulting player speech sample may be associated with the example of speech audio107as a “paired” training example for use in refining the voice convertor112(or components thereof), as will be described in relation toFIGS.6and7. In some implementations, speech audio107and/or speech scripts117may also be stored at game server114.
As will be described in further detail in relation toFIG.2, the speech audio generator110comprises a synthesizer111, a voice convertor112, and a vocoder113. The synthesizer111receives input data representing speech content to produce source acoustic features, which are transformed by the voice convertor112into target acoustic features in accordance with player identifier data. Speech audio in the player's voice is output by the vocoder113after processing the target acoustic features.
The video game server apparatus109provides the game server114, which communicates with the client-side gaming application102. As shown inFIG.1, the game server114includes request router115, and optionally, speech audio116and speech script117as described previously. The request router115receives requests from the gaming application102, and provides video game content responsive to the request to the gaming application102. Examples of requests include Application Programming Interface (API) requests, e.g. a representational state transfer (REST) call, a Simple Object Access Protocol (SOAP) call, a message queue; or any other suitable request.
AlthoughFIG.1shows the speech audio generator110implemented by video game server apparatus109, it will be appreciated that one or more components of the speech audio generator110may be implemented by computing device101. For example, one or more components of the voice convertor112may be implemented by computing device101, avoiding the need for player speech samples to be transmitted to video game server apparatus109.
Example Speech Audio Generator System
FIG.2is a schematic block diagram illustrating an example of a computer system200configured to provide a speech audio generator for generating speech audio in a voice of a player of a video game, using a voice convertor.
The speech audio generator201comprises a synthesizer202. The synthesizer202is a machine-learned model which receives input data representing speech content, and optionally, speech style features, and outputs a sequence of source acoustic features.
The synthesizer202may be pre-trained using recordings or input from speakers for whom there are many speech samples. For example, the synthesizer202may be pre-trained using training examples derived from speech samples wherein each training example comprises ground-truth acoustic features for the respective speech sample, and a corresponding transcript for the speech content of the speech sample. In addition, each training example may further comprise speech style features (e.g. prosodic features) for the speech sample. The synthesizer processes the input data representing speech content and the (optional) speech style features of one or more training examples and generates predicted acoustic features for the one or more training examples. The synthesizer is trained in dependence on an objective function, wherein the objective function comprises a comparison between the predicted acoustic features and the ground-truth acoustic features. The parameters of the synthesizer202are updated by optimizing the objective function using any suitable optimization procedure. For example, the objective function may be optimized using gradient-based methods such as stochastic gradient descent, mini-batch gradient descent, or batch gradient descent.
The synthesizer202may comprise a speech content encoder to generate one or more speech content encodings for the input data. The input data comprises an indication of an utterance for each of a plurality of input time steps. The speech content encoder may comprise a recurrent neural network comprising one or more recurrent layers. Each recurrent layer comprises a hidden state that is updated as the recurrent neural network processes the input data. For each time step, recurrent layer receives its hidden state from the previous time step, and an input to the recurrent layer for the current time step. For example, an input for a first recurrent layer comprises a portion of the input data for a particular time step. An input for a subsequent recurrent layer may comprise a hidden state of a previous recurrent layer. A recurrent layer processes its previous hidden state and the current input in accordance with its parameters and generates an updated hidden state for the current time step. For example, recurrent layer may apply a first linear transformation to the previous hidden state and a second linear transformation to the current input and combine the results of the two linear transformations e.g. by adding the two results together. Recurrent layer may apply a non-linear activation function (e.g. a tanh activation function, a sigmoid activation function, a ReLU activation function, etc.) to generate an updated hidden state for the current time step.
In some embodiments, the synthesizer202may further comprise a speech style encoder to generate a speech style encoding from speech style features. The speech style encoder may comprise a feedforward network comprising one or more fully connected layers. Each fully connected layer receives an input and applies a learned linear transformation to the input. The fully connected layer may further apply a non-linear transformation to generate an output for the layer. The input of a first fully connected layer comprises the speech style features, and the input to subsequent fully connected layers comprises the output of a previous fully connected layer.
Speech content encodings and speech style encodings may be combined to generate one or more combined encodings. A combining operation may comprise any binary operation resulting in a single encoding. For example, the combination may be performed by an addition, an averaging, a dot product, or a Hadamard product. Source acoustic features may be generated from processing the combined output. The generating may comprise decoding the one or more combined encodings by a decoder of the synthesizer to generate source acoustic features. The decoder may comprise one or more recurrent layers. The decoder may further comprise an attention mechanism. For each output time step of a plurality of output time steps, the combined encoding for each input time step may be received. The attention mechanism may generate an attention weight for each combined encoding. The attention mechanism may generate a context vector for the output time step by averaging each combined encoding using the respective attention weight. The decoder may process the context vector of the output time step to generate source acoustic features for the output time step.
The speech content encoder and the decoder of the synthesizer may be implemented as a single encoder-decoder model. For example, they may be combined as an encoder-decoder (e.g. sequence-to-sequence) neural network with or without attention.
The speech audio generator201comprises a voice convertor203used to transform source acoustic features into target acoustic features. The voice convertor203comprises machine-learned models that may be initially trained using speech samples used to train the synthesizer, and then refined using model trainer207with speech samples provided by the player in order to generate target acoustic features corresponding to the speech content in the player's voice.
The voice convertor203comprises a speaker encoder204, acoustic feature encoder205, acoustic feature decoder206, and model trainer207.
The speaker encoder204receives player identifier data and outputs a speaker embedding. The speaker embedding is a representation of the voice of the player associated with player identifier data. The speaker embedding is a vector of a learned embedding space, such that different speakers are represented in different regions of the embedding space.
In some embodiments, and as will be discussed described relation toFIG.5, the speaker encoder204has been trained separately to acoustic feature encoder205and acoustic feature decoder206. In these embodiments, the speaker encoder204may comprise a recurrent neural network comprising one or more recurrent layers. The recurrent neural network is configured to receive player identifier data comprising speech audio (or acoustic features thereof) from a particular player.
In some embodiments, and as will be described in relation toFIG.7, the speaker encoder204has been trained jointly with acoustic feature encoder207. In these embodiments, the speaker encoder204may comprise a feedforward neural network comprising one or more fully connected layers. The feedforward neural network is configured to receive player identifier data comprising a speaker identifier for a particular player.
The acoustic feature encoder205receives a target speaker embedding and source acoustic features and outputs one or more acoustic feature encodings. The acoustic feature encoder205may comprise a recurrent neural network comprising one or more recurrent layers.
The acoustic feature decoder206receives one or more acoustic feature encodings and outputs a sequence of target acoustic features. The acoustic feature decoder206may comprise a recurrent neural network comprising one or more recurrent layers.
Although depicted inFIG.2as two separate components, it will be appreciated that the acoustic feature encoder205and acoustic feature decoder206may be combined as a single encoder-decoder model. For example, they may be combined as an encoder-decoder (e.g. sequence-to-sequence) neural network with or without attention.
Model trainer207is used, after an initial training procedure for the components of the voice convertor203, to refine components of the voice convertor203when adding a player's voice to the speech audio generator201. During the process of adding the player's voice to the speech audio generator201, the player provides speech samples from which acoustic features are determined to refine (i.e. further train) the acoustic feature encoder205, and acoustic feature decoder206. In some implementations, the speaker encoder204is also refined using the player speech samples.
The player speech samples may be used to form a “paired training example” or an “unpaired training example”. In a “paired training example”, the player speech sample closely matches an example used to train components of the voice convertor module203. For example, the user may be asked to mimic an example of speech audio such that the player speaks the same words as the example, in a speech style (e.g. prosody) similar to that of the example. In some embodiments, and as will be described in relation toFIG.7, paired training examples may be used to jointly train speaker encoder204, acoustic feature encoder205, and acoustic feature decoder206. In an “unpaired training example”, the player speech sample does not closely match an example used to train components of the voice convertor module203. In some embodiments, and as will be described in relation toFIG.5, unpaired training examples may be used to separately train speaker encoder204.
The speech audio generator201comprises a vocoder208. The vocoder208is a machine-learned model which is used during processing of the target acoustic features to produce a waveform of speech audio. The speech audio is synthesized speech audio in the player's voice corresponding to the speech content represented in the input data. The vocoder208may comprise a recurrent neural network comprising one or more recurrent layers.
The vocoder208may be pre-trained using recordings or input from speakers for whom there are many speech samples. In some cases, the same vocoder208may be used for many speakers without the need for retraining based on new speakers, i.e. the vocoder208may comprise a universal vocoder. For example, the vocoder208may be pre-trained using training examples derived from speech samples wherein each training example comprises acoustic features for the speech sample and a corresponding ground-truth waveform of speech audio. The vocoder208processes the acoustic features of one or more training examples and generates a predicted waveform of speech audio for the one or more training examples. The vocoder208is trained in dependence on an objective function, wherein the objective function comprises a comparison between the predicted waveform of speech audio and the ground-truth waveform of speech audio. The parameters of the vocoder208are updated by optimizing the objective function using any suitable optimization procedure. For example, the objective function may be optimized using gradient-based methods such as stochastic gradient descent, mini-batch gradient descent, or batch gradient descent.
Example Speech Audio Generator Method
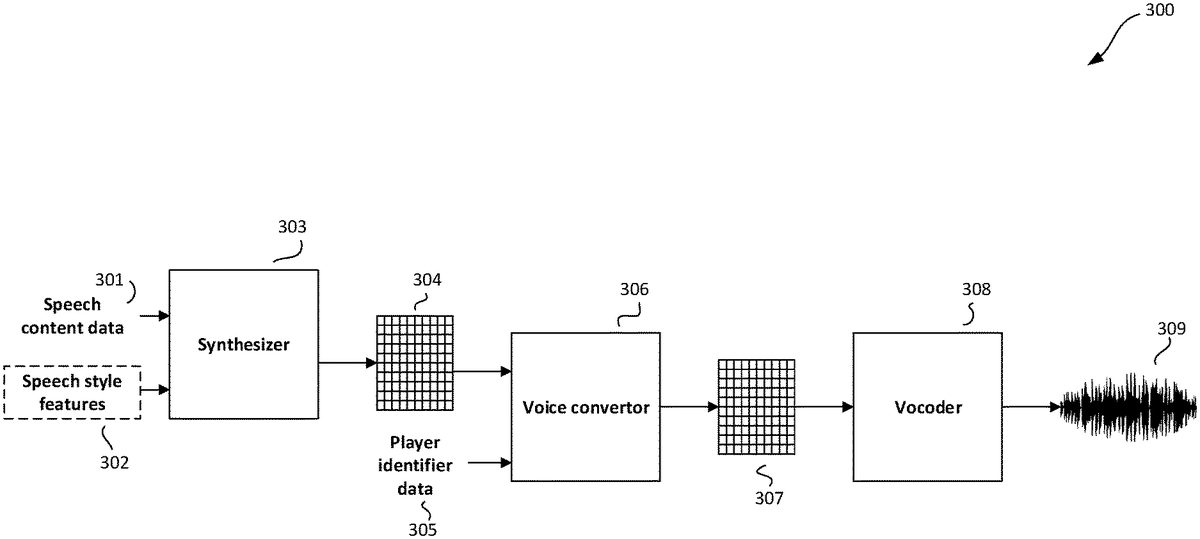
FIG.3illustrates an example method for a speech audio generator300for generating speech audio in a voice of a player of a video game, using a voice convertor. The method shown inFIG.3corresponds to the processing performed by components of the speech audio generator described in relation toFIG.2.
The synthesizer303is configured to receive input data representing speech content301, and optionally, speech style features302.
The input data may comprise any suitable representation of speech content. The speech content represented by the input data may include (or be) lexical utterances such as words, non-lexical utterances, or a combination of lexical and non-lexical utterances. Non-lexical utterances may include noises (e.g. a sigh or moan), disfluencies (e.g. um, oh, uk), and the like. Any paralinguistic utterance may be indicated in the input data, such as sighs, yawns, moans, laughs, grunts, etc. The speech content301may be encoded by a sequence of vectors with each vector representing a character of the speech content301. For example, a character may be a letter, a number, and/or a tag (e.g. indicating a paralinguistic utterance). The elements of a character vector may correspond with one character out of a set of possible characters, with each character represented by a character vector with only one non-zero element (also known as a one-hot vector). Additionally or alternatively, the speech content301may be represented by continuous embeddings, e.g. character embeddings and/or word embeddings. Generally, embeddings are vectors of a learned embedding space. Phoneme information may also be included in the input data. In some embodiments the input data may comprise text data. The text data may be any digital data representing text.
The speech style features may be any features representing aspects of speech style. For example, the speech style features may comprise prosodic features and/or source speaker attribute information. Prosodic features are features which capture aspects of speech prosody such as intonation, stress, rhythm, and style of speech. Speaker attribute information is information that captures characteristics of the source speaker in the synthesized source acoustic features. For example, source speaker attribute information may comprise at least one of an age, a gender, and an accent type.
The input data representing speech content301, and optionally, speech style features302, are processed by the synthesizer303to output source acoustic features304. The synthesizer303may comprise a speech content encoder to generate one or more speech content encodings for the speech content301. In some embodiments, the synthesizer303may further comprise a speech style encoder to generate a speech style encoding from speech style features302. Speech content encodings and speech style encodings may be combined to generate one or more combined encodings. A combining operation may comprise any binary operation resulting in a single encoding. For example, the combination may be performed by an addition, an averaging, a dot product, or a Hadamard product. Source acoustic features may be generated from processing the combined output. The generating may comprise decoding the one or more combined encodings by a decoder of the synthesizer to generate source acoustic features.
The source acoustic features304comprise acoustic features for the speech content301in a source speaker's voice (and, if appropriate, in a speech style specified by speech style features302). The source speaker may be a speaker whose voice samples were used to initially train synthesizer303. Acoustic features may comprise any low-level acoustic representation of frequency, magnitude and phase information such as linear spectrograms, log-mel-spectrograms, linear predictive coding (LPC) coefficients, Mel-Frequency Cepstral Coefficients (MFCC), log fundamental frequency (LFO), band aperiodicity (bap) or combinations thereof. The acoustic features may comprise a sequence of vectors, each vector representing acoustic information in a short time period, e.g. 50 milliseconds.
The voice convertor306is configured to receive the source acoustic features304and player identifier data305. The player identifier data305is any data that can be associated with (e.g. used to identify) an individual player. In some embodiments, the player identifier data305is a speaker identifier, which may be for example, a different one-hot vector for each speaker whose voice can be synthesized in output of the speech audio generator300. In other embodiments, the player identifier data305are speech samples (or acoustic features thereof) provided by that particular player. The source acoustic features304and player identifier data305are processed by the voice convertor module306to output target acoustic features307. The target acoustic features307comprise acoustic features for the speech content301, but in a voice of the player associated with player identifier data305(and, if appropriate, in a speech style specified by speech style features302).
The vocoder308is configured to receive the target acoustic features307. The vocoder308processes the target acoustic features to produce a waveform of speech audio309. The speech audio309is synthesized speech audio in the player's voice corresponding to the speech content301. The speech audio309comprises an amplitude sample for each of a plurality of audio frames.
Voice Convertor Method
FIG.4illustrates an example method400for a voice convertor configured to transform source acoustic features into target acoustic features.
The voice convertor401comprises a speaker encoder403, an acoustic feature encoder406, and an acoustic feature decoder407.
The speaker encoder403is configured to receive player identifier data402. The player identifier data402is any data that can be associated with (e.g. used to identify) an individual player. In some embodiments, the player identifier data is a speaker identifier, which may be for example, a different one-hot vector for each speaker whose voice can be synthesized in output of the speech audio generator110. In other embodiments, the player identifier data are speech samples (or indications thereof, e.g. acoustic features) provided by that particular player.
The speaker encoder403processes the player identifier data402and outputs speaker embedding405. The speaker embedding405is a representation of the voice of the player associated with player identifier data402. The speaker embedding405is a vector of a learned embedding space, such that different speakers are represented in different regions of the embedding space. In embodiments where the player identifier data402comprises player speech samples (or acoustic features thereof), the speaker embedding405may be determined from an average of one or more embeddings which each may be determined by inputting a different player speech sample (or acoustic features thereof) into speaker encoder403.
Acoustic feature encoder406is configured to receive source acoustic features404and target speaker embedding405. The acoustic feature encoder outputs one or more acoustic feature encodings. An acoustic feature encoding may be determined for each input time step of a plurality of input time steps of the source acoustic features. The acoustic feature encoding for each input time step may comprise a combination of the speaker embedding for the player and an encoding of the source acoustic features for the input time step. For example, the combination may be performed by a concatenation operation, an addition operation, a dot product operation, etc.
Acoustic feature decoder407is configured to receive the one or more acoustic feature encodings output by acoustic feature encoder406. The acoustic feature decoder407outputs target acoustic features408. The target acoustic features408comprises target acoustic features for a plurality of output time steps. The acoustic feature decoder407may comprise an attention mechanism. For each output time step of the plurality of output time steps, the acoustic feature encoding for each input time step may be received. The attention mechanism may generate an attention weight for each acoustic feature encoding. The attention mechanism may generate a context vector for the output time step by averaging each acoustic feature encoding using the respective attention weight. The acoustic feature decoder407may process the context vector of the output time step to generate target acoustic features for the output time step.
Speaker Encoder Training Method
FIG.5illustrates an example method500for training a speaker encoder to generate speaker embeddings. In the embodiment depicted inFIG.5, the speaker encoder506is trained separately to the acoustic feature encoder and acoustic feature decoder. The separate training of the acoustic feature encoder and acoustic feature decoder will be described in relation toFIG.6.
As shown inFIG.5, the speaker encoder is being trained on a speaker verification task, although it will be appreciated that the speaker encoder may be trained on other similar tasks (such as speaker classification). In the speaker verification task, speech audio (or acoustic features thereof) is processed in order to verify the speaker's identity. Separate training of the speaker encoder506may result in a more representative speaker encoder, such that speaker embeddings507output by the speaker encoder506more accurately reflect the characteristics of a speaker's voice. For example, speech samples spoken by the same speaker may have different embeddings, which are close to each other (in an embedding space) compared to embeddings for speech samples from different speakers. In cases where the performance of the speaker is different in speech samples provided by that speaker (for example whispering compared to screaming), the variety in performance may be captured in the embeddings since a different embedding is output for each speech sample. In addition, speaker encoder506may have sufficient representation power to encode speech audio from speakers that are not present in the training set used to train the speaker encoder506. Given a new speaker, the speaker encoder506may not need to be retrained and can be used as preprocessing module to obtain speaker embeddings. Furthermore, unpaired training examples may be used to train speaker encoder506, allowing a large corpus of publicly available data to be used to train the speaker encoder506.
The speaker encoder506is trained using training set501comprising training examples502-1,502-2,502-3. Each training example502comprises speech audio504and a speaker label503corresponding to the speaker identity of the respective speech audio504. For example, if speech audio504-1and speech audio504-2were provided by the same speaker, then speaker labels503-1and503-2are identical. Speaker label503-3is different to that of speaker labels503-1,503-2if speech audio504-3was provided by a different speaker to that of speech audio504-1,504-2. Speaker labels503may be represented by one hot vectors such that a different one-hot vector indicates each speaker in the training set501. In general, the training set501comprises a plurality of examples of speech audio504for each speaker.
As shown inFIG.5, speech audio504-2of training example502-2is processed by acoustic feature extractor505to determine acoustic features for speech audio504-2. Acoustic feature extractor505may determine acoustic features in any suitable manner, e.g. by performing a Fast Fourier Transform on speech audio504. Acoustic features determined by the acoustic feature extractor505may comprise any low-level acoustic representation of frequency, magnitude and phase information such as linear spectrograms, log-mel-spectrograms, linear predictive coding (LPC) coefficients, Mel-Frequency Cepstral Coefficients (MFCC), log fundamental frequency (LFO), band aperiodicity (bap) or combinations thereof. The acoustic features may comprise a sequence of vectors, each vector representing acoustic information in a short time period, e.g. 50 milliseconds.
The acoustic features are received by speaker encoder506, which processes the acoustic features in accordance with a current set of parameters and outputs a speaker embedding507for speech audio504-2.
The speaker embedding507is processed in order to verify the speaker identity of speech audio504-2. For example, the speaker embedding507may be used as part of a generalized end-to-end speaker loss, with the speaker encoder506trained to optimize the loss. The generalized end-to-end speaker loss may be used to train the speaker encoder506to output embeddings of utterances from the same speaker with a high similarity (which may be measured by cosine similarity), while those of utterances from different speakers are far apart in the embedding space. For example, the generalized end-to-end speaker loss may involve finding a centroid for each speaker by averaging embeddings for speech samples provided by the speaker. A similarity matrix may be determined measuring the similarity (e.g. cosine similarity, or a linear transformation thereof) between the embedding for each utterance in a training batch and the centroid for each speaker. The generalized end-to-end speaker loss may encourage the similarity matrix to have high values for matching speaker-centroid values (e.g. values representing a similarity between an embedding for an utterance by a speaker and the centroid for the same speaker), and low values for non-matching speaker-centroid values. Alternatively, the speaker embedding for speech audio504-2may be received by an output classification layer which processes the speaker embedding in accordance with a current set of parameters, and outputs a speaker identity output. For example, the output classification layer may comprise a softmax layer, and the speaker identity output may comprise a probability vector indicating a probability, for each speaker out of the set of speakers included in the training set501, that speech audio504-2was provided by the speaker.
Model trainer508receives speaker embedding507for speech audio504-2, and speaker label503-2for speech audio504-2and updates the parameters of speaker encoder506in order to optimize an objective function. The objective function comprises a loss in dependence on the speaker label503-2and speaker embedding507. For example, the loss may measure a cross-entropy loss between speaker label503-2and a speaker identity output. The objective function may additionally comprise a regularization term, for example the objective function may be a linear combination of the loss and the regularization term. The parameters of the speaker encoder506may be updated by optimizing the objective function using any suitable optimization procedure. For example, the objective function may be optimized using gradient-based methods such as stochastic gradient descent, mini-batch gradient descent, or batch gradient descent, including momentum-based methods such as Adam, RMSProp, and AdaGrad. In the event that an output classification layer is included, optimizing the objective function using the model trainer508may include updating the parameters of the output classification layer.
AlthoughFIG.5shows the training process with processing of a single training example, it will be appreciated that any number of training examples may be used when updating the parameters of the speaker encoder506. The training process is repeated for a number of passes through the training set501, and is terminated at a suitable point in time, e.g. when a speaker identity output derived from speaker embedding507can be reliably used to correctly verify speaker identity. After training has completed, the speaker encoder506is retained for use in generating speaker embeddings for speech samples, as described previously.
Acoustic Feature Encoder/Decoder Training Method
FIG.6illustrates an example method600for training an acoustic feature encoder and an acoustic feature decoder to generate target acoustic features. The method displayed inFIG.6occurs after separate training of the speaker encoder, resulting in a pre-trained speaker encoder604, as described in relation toFIG.5. During the training process displayed inFIG.6, the parameters of the pre-trained speaker encoder604are fixed. The acoustic feature encoder605and acoustic feature decoder606are initially trained prior to adding a new player's voice and are subsequently refined when the player adds their voice and provides player speech samples.
As shown inFIG.6, acoustic feature encoder605and acoustic feature decoder606are trained on a voice conversion task using one or more training examples601. In a voice conversion task, source acoustic features are transformed into target acoustic features such that synthesized speech audio from the target acoustic features closely match the content and performance of the source acoustic features, while changing the voice represented in the source acoustic features into that of the target speaker.
Training example601comprises source acoustic features603and corresponding target acoustic features602. During training, the goal of the acoustic feature encoder605and the acoustic feature decoder606is to transform source acoustic features603of a training example601into the target acoustic features602of the training example601. The training example may be referred to as a “paired” training example, wherein the source speech audio (from which the source acoustic features603are determined) and the target speech audio (from which the target source acoustic features602are determined) differ only in speaker identity. Alternatively said, the content (e.g. the words spoken) and the performance of the source and target speech audio may closely match each other in a paired training example.
When adding a new player's voice, the target acoustic features602correspond to acoustic features from player speech samples provided by the player. As described previously, the player speech samples may be paired with source speech audio (e.g. when the player is asked to mimic the source speech audio).
The target acoustic features602are received by the pre-trained speaker encoder, which processes the target acoustic features602in accordance with a learned set of parameters, and outputs a target speaker embedding for the target acoustic features602.
The target speaker embedding and source acoustic features603are received by acoustic feature encoder605, which processes the received inputs in accordance with a current set of parameters to output one or more acoustic feature encodings. The one or more acoustic feature encodings are processed by the acoustic feature decoder606in accordance with a current set of parameters to output predicted target acoustic features607.
Model trainer608receives the predicted target acoustic features607and the “ground-truth” target acoustic features602, and updates the parameters of acoustic feature encoder605and acoustic feature decoder606in order to optimize an objective function. The objective function comprises a loss in dependence on the predicted target acoustic features607and the ground-truth target acoustic features602. For example, the loss may measure a mean-squared error between the predicted target acoustic features607and the ground-truth target acoustic features602. The objective function may additionally comprise a regularization term, for example the objective function may be a linear combination of the loss and the regularization term. The objective function may further comprise other weighted losses such as speaker classifier (to emphasize that the target acoustic features have target speaker characteristics) or alignment loss (to emphasize the correct alignment between paired source and target acoustic features). The parameters of the acoustic feature encoder605and acoustic feature decoder606may be updated by optimizing the objective function using any suitable optimization procedure. For example, the objective function may be optimized using gradient-based methods such as stochastic gradient descent, mini-batch gradient descent, or batch gradient descent, including momentum-based methods such as Adam, RMSProp, and AdaGrad.
The training process is repeated for a number of training examples, and is terminated at a suitable point in time, e.g. when predicted target acoustic features607closely match ground-truth target acoustic features602. After an initial training process, the acoustic feature encoder605and acoustic feature decoder606are further trained/refined using target acoustic features602determined from player speech samples. Subsequently, the speaker encoder604, acoustic feature encoder605and acoustic feature decoder606can be used to convert any source acoustic features into target acoustic features corresponding to the player's voice.
Joint Training Method
FIG.7illustrates an example method700for training a speaker encoder, an acoustic feature encoder, and an acoustic feature decoder to generate target acoustic features. In the embodiment depicted inFIG.7, the speaker encoder705is trained jointly with the acoustic feature encoder706and acoustic feature decoder707on a voice conversion task.
Training example701comprises source acoustic features704, corresponding target acoustic features702, and a target speaker identifier703. During training, the goal is to transform source acoustic features704of a training example701into the target acoustic features702of the training example701. The training example may be referred to as a “paired” training example, wherein the source speech audio (from which the source acoustic features704are determined) and the target speech audio (from which the target source acoustic features702are determined) differ only in speaker identity. Alternatively said, the content (e.g. the words spoken) and the performance of the source and target speech audio may closely match each other in a paired training example. The target speaker identifier703is a label used to identify the speaker corresponding to target acoustic features702. Training examples701with target acoustic features corresponding to the same speaker have identical target speaker identifiers703. Target speaker identifiers703may be represented by one hot vectors such that a different one-hot vector indicates each speaker in the training set501. In addition, one or more one-hot vectors may be reserved as target speaker identifiers703for players who wish to synthesize speech audio in their voice.
Target speaker identifier703is received by speaker encoder705, which processes the target speaker identifier703in accordance with a current set of parameters and outputs a target speaker embedding for the target speaker.
The target speaker embedding and source acoustic features704are received by acoustic feature encoder706, which processes the received inputs in accordance with a current set of parameters to output one or more acoustic feature encodings. The one or more acoustic feature encodings are processed by the acoustic feature decoder707in accordance with a current set of parameters to output predicted target acoustic features708.
Model trainer709receives the predicted target acoustic features708and the “ground-truth” target acoustic features702, and updates the parameters of the speaker encoder705, acoustic feature encoder706and acoustic feature decoder707in order to optimize an objective function. The objective function comprises a loss in dependence on the predicted target acoustic features708and the ground-truth target acoustic features702. For example, the loss may measure a mean-squared error between the predicted target acoustic features708and the ground-truth target acoustic features702. The objective function may additionally comprise a regularization term, for example the objective function may be a linear combination of the loss and the regularization term. The parameters of the speaker encoder705, acoustic feature encoder706and acoustic feature decoder707may be updated by optimizing the objective function using any suitable optimization procedure. For example, the objective function may be optimized using gradient-based methods such as stochastic gradient descent, mini-batch gradient descent, or batch gradient descent, including momentum-based methods such as Adam, RMSProp, and AdaGrad.
The training process is repeated for a number of training examples, and is terminated at a suitable point in time, e.g. when predicted target acoustic features708closely match ground-truth target acoustic features702. After an initial training process, the speaker encoder705, acoustic feature encoder706and acoustic feature decoder707are further trained/refined using target acoustic features702determined from player speech samples. Subsequently, the speaker encoder705, acoustic feature encoder706and acoustic feature decoder707can be used to convert any source acoustic features into target acoustic features corresponding to the player's voice.
FIG.8is a flow diagram800illustrating an example method for generating speech audio in a video game using a voice convertor that has been trained to convert acoustic features for a source speaker into acoustic features for a player of the video game.
In step8.1, input data is inputted into a synthesizer module. The input data represents speech content. The speech content may be determined from an input of the player of the video game. Additionally, or alternatively, the speech content may be determined from content in the video game. The input data may comprise a representation of text. Additionally, or alternatively, the input data may comprise one or more indications of paralinguistic information (e.g. sighs, yawns, moans, etc.) The input data may further comprise source speaker attribute information. For example, source speaker attribute information may comprise at least one of an age, a gender, or an accent type. Additionally, or alternatively, the input data may further comprise speech style features. For example, the speech style features may comprise prosodic features.
The synthesizer may comprise neural network layers. For example, the neural network layers may comprise feedforward layers, e.g. fully connected layers and/or convolutional layers. Additionally or alternatively, the neural network layers may comprise recurrent layers, e.g. LSTM layers and/or bidirectional LSTM layers. The synthesizer202may comprise encoder-decoder (e.g. sequence-to-sequence) neural networks with and without attention, transformer networks, etc.
In step8.2, source acoustic features are generated as output of the synthesizer module. The source acoustic features are acoustic features for the speech content in the voice of a source speaker.
In step8.3, a target speaker embedding and the source acoustic features are inputted into an acoustic feature encoder of the voice convertor. The speaker embedding is a learned representation of the voice of a player of the video game. The speaker embedding may be generated from output of a speaker encoder of the voice convertor, the generating comprising inputting player identifier data into the speaker encoder. Player identifier data is any data that can be associated with (e.g. used to identify) an individual player. In some embodiments, the player identifier data may be a speaker identifier, which may be for example, a different one-hot vector for each speaker whose voice can be synthesized in output of the speech audio generator no. In other embodiments, the player identifier data may be speech samples (or indications thereof, e.g. acoustic features) provided by that particular player.
The acoustic feature encoder may comprise neural network layers. For example, the neural network layers may comprise feedforward layers, e.g. fully connected layers and/or convolutional layers. Additionally or alternatively, the neural network layers may comprise recurrent layers, e.g. LSTM layers and/or bidirectional LSTM layers.
The speaker encoder may comprise neural network layers. For example, the neural network layers may comprise feedforward layers, e.g. fully connected layers and/or convolutional layers. Additionally or alternatively, the neural network layers may comprise recurrent layers, e.g. LSTM layers and/or bidirectional LSTM layers.
In step8.4, one or more acoustic feature encodings are generated as output of the acoustic feature encoder. The generating may comprise combining one or more source acoustic feature encodings with the target speaker embedding to generate one or more acoustic feature encodings. A combining operation may comprise any binary operation resulting in a single encoding. For example, the combination may be performed by an addition, an averaging, a dot product, or a Hadamard product.
The acoustic feature decoder may comprise neural network layers. For example, the neural network layers may comprise feedforward layers, e.g. fully connected layers and/or convolutional layers. Additionally or alternatively, the neural network layers may comprise recurrent layers, e.g. LSTM layers and/or bidirectional LSTM layers.
The acoustic feature encoder and acoustic feature decoder may be combined as a single encoder-decoder model. For example, they may be combined as an encoder-decoder (e.g. sequence-to-sequence) neural network with or without attention, or as a transformer network, etc. Furthermore, an encoder-decoder model may be implemented by architectures such as Variational Autoencoders (VAEs) and Generative Adversarial Networks (GANs).
In step8.5, the one or more acoustic feature encodings are inputted into an acoustic feature decoder of the voice convertor module.
In step8.6, target acoustic features are generated. The target acoustic features comprise acoustic features for the speech content in the voice of the player. The generating comprises decoding the one or more acoustic feature encodings using the acoustic feature decoder.
In step8.7, speech audio in the voice of the player is generated. This step comprises processing the target acoustic features with one or more modules, the one or more modules comprising a vocoder configured to generate speech audio in the voice of the player.
The vocoder may comprise neural network layers. For example, the neural network layers may comprise feedforward layers, e.g. fully connected layers and/or convolutional layers. Additionally or alternatively, the neural network layers may comprise recurrent layers, e.g. LSTM layers and/or bidirectional LSTM layers.
FIG.9is a flow diagram900is a flow diagram illustrating an example method for generating speech audio data in a video game using a voice convertor that has been trained to convert acoustic features for a source speaker into acoustic features for a player of the video game.
In step9.1, a target speaker embedding and source acoustic features are inputted into an acoustic feature encoder of the voice convertor. The speaker embedding is a learned representation of the voice of a player of the video game. The source acoustic features are acoustic features for speech content in the voice of a source speaker.
The speaker embedding may be generated from output of a speaker encoder of the voice convertor. The generating may comprise: inputting, into the speaker encoder, one or more examples of speech audio provided by the player; generating, as output of the speaker encoder, an embedding for each example of speech audio; and generating the speaker embedding for the player based on the embeddings for each example. The speaker embedding for the player may be an average of the embeddings generated for each example. Alternatively, the generating may comprise: inputting, into the speaker encoder, a speaker identifier for the player; and generating, as output of the speaker encoder, the speaker embedding for the player.
The speaker encoder may comprise one or more recurrent layers. Additionally or alternatively, the speaker encoder may comprise one or more fully connected layers.
In step9.2, one or more acoustic features encodings are generated as output of the acoustic feature encoder. Each of the one or more acoustic feature encodings may comprise a combination of the target speaker embedding and an encoding of the source acoustic features. The generating may comprise generating an acoustic feature encoding for each input time step of a plurality of input time steps of the source acoustic features, wherein the acoustic feature encoding for each input time step comprises a combination of the speaker embedding for the player and an encoding of the source acoustic features for the input time step.
In step9.3, the one or more acoustic feature encodings are inputted into an acoustic feature decoder of the voice convertor.
At least one of the acoustic feature encoder or the acoustic feature decoder may comprise one or more recurrent layers.
In step9.4, target acoustic features are generated. The target acoustic features comprise acoustic features for the speech content in the voice of the player. The generating comprises decoding the one or more acoustic feature encodings using the acoustic feature decoder. Decoding the one or more acoustic feature encodings may comprise, for each output time step of a plurality of output time steps: receiving the acoustic feature encoding for each input time step; generating, by an attention mechanism, an attention weight for each acoustic feature encoding; generating, by the attention mechanism, a context vector for the output time step by averaging each acoustic feature encoding using the respective attention weight; and processing, by the acoustic feature decoder, the context vector of the output time step to generate target acoustic features for the output time step. Speech audio data may be generated from the target acoustic features, e.g. a waveform of speech, or any other suitable representation of speech audio.
FIG.10shows a schematic example of a system/apparatus for performing methods described herein. The system/apparatus shown is an example of a computing device. It will be appreciated by the skilled person that other types of computing devices/systems may alternatively be used to implement the methods described herein, such as a distributed computing system.
The apparatus (or system)1000comprises one or more processors1002. The one or more processors control operation of other components of the system/apparatus1000. The one or more processors1002may, for example, comprise a general purpose processor. The one or more processors1002may be a single core device or a multiple core device. The one or more processors1002may comprise a central processing unit (CPU) or a graphical processing unit (GPU). Alternatively, the one or more processors1002may comprise specialised processing hardware, for instance a RISC processor or programmable hardware with embedded firmware. Multiple processors may be included.
The system/apparatus comprises a working or volatile memory1004. The one or more processors may access the volatile memory1004in order to process data and may control the storage of data in memory. The volatile memory1004may comprise RAM of any type, for example Static RAM (SRAM), Dynamic RAM (DRAM), or it may comprise Flash memory, such as an SD-Card.
The system/apparatus comprises a non-volatile memory1006. The non-volatile memory1006stores a set of operation instructions1008for controlling the operation of the processors1002in the form of computer readable instructions. The non-volatile memory1006may be a memory of any kind such as a Read Only Memory (ROM), a Flash memory or a magnetic drive memory.
The one or more processors1002are configured to execute operating instructions1008to cause the system/apparatus to perform any of the methods described herein. The operating instructions1008may comprise code (i.e. drivers) relating to the hardware components of the system/apparatus1000, as well as code relating to the basic operation of the system/apparatus1000. Generally speaking, the one or more processors1002execute one or more instructions of the operating instructions1008, which are stored permanently or semi-permanently in the non-volatile memory1006, using the volatile memory1004to temporarily store data generated during execution of said operating instructions1008.
Implementations of the methods described herein may be realised as in digital electronic circuitry, integrated circuitry, specially designed ASICs (application specific integrated circuits), computer hardware, firmware, software, and/or combinations thereof. These may include computer program products (such as software stored on e.g. magnetic discs, optical disks, memory, Programmable Logic Devices) comprising computer readable instructions that, when executed by a computer, such as that described in relation toFIG.10, cause the computer to perform one or more of the methods described herein.
Any system feature as described herein may also be provided as a method feature, and vice versa. As used herein, means plus function features may be expressed alternatively in terms of their corresponding structure. In particular, method aspects may be applied to system aspects, and vice versa.
Furthermore, any, some and/or all features in one aspect can be applied to any, some and/or all features in any other aspect, in any appropriate combination. It should also be appreciated that particular combinations of the various features described and defined in any aspects of the invention can be implemented and/or supplied and/or used independently.
Although several embodiments have been shown and described, it would be appreciated by those skilled in the art that changes may be made in these embodiments without departing from the principles of this disclosure, the scope of which is defined in the claims.
Claims
- A computer-implemented method of generating speech audio in a video game using a voice convertor that has been trained to convert acoustic features for a source speaker into acoustic features for a player of the video game, the method comprising: inputting, into a synthesizer module, input data representing speech content;generating, as output of the synthesizer module, source acoustic features for the speech content in the voice of the source speaker;inputting, into an acoustic feature encoder of the voice convertor, (i) a target speaker embedding associated with the player of the video game, wherein the target speaker embedding is a learned representation of the voice of the player, and (ii) the source acoustic features;generating, as output of the acoustic feature encoder, one or more acoustic feature encodings, wherein generating the one or more acoustic feature encodings comprises generating an acoustic feature encoding for each input time step of a plurality of input time steps of the source acoustic features, wherein the acoustic feature encoding for each input time step comprises a combination of the target speaker embedding for the player and an encoding of the source acoustic features for the input time step;inputting, into an acoustic feature decoder of the voice convertor, the one or more acoustic feature encodings;generating target acoustic features, comprising decoding the one or more acoustic feature encodings using the acoustic feature decoder, wherein the target acoustic features comprise acoustic features for the speech content in the voice of the player, wherein decoding the one or more acoustic feature encodings comprises, for each output time step of a plurality of output time steps: receiving the acoustic feature encoding for each input time step, generating, by an attention mechanism, an attention weight for each acoustic feature encoding, generating, by the attention mechanism, a context vector for the output time step by averaging each acoustic feature encoding using the respective attention weight, and processing, by the acoustic feature decoder, the context vector of the output time step to generate target acoustic features for the output time step;and processing the target acoustic features with one or more modules, the one or more modules comprising a vocoder configured to generate speech audio in the voice of the player.
- The method of claim 1, wherein the speech content is determined from an input of the player of the video game.
- The method of claim 1, wherein the speech content is determined from content in the video game.
- The method of claim 1, wherein the input data further comprises at least one of source speaker attribute information or speech style features.
- The method of claim 1, wherein the input data comprises text data.
- The method of claim 1, wherein the speech content comprises paralinguistics.
- The method of claim 1, wherein the target speaker embedding is generated from output of a speaker encoder of the voice convertor, the generating comprising inputting player identifier data into the speaker encoder.
- A computer-implemented method of generating speech audio data in a video game using a voice convertor that has been trained to convert acoustic features for a source speaker into acoustic features for a player of the video game, the method comprising: inputting, into an acoustic feature encoder of the voice convertor, (i) a target speaker embedding associated with a player of the video game, wherein the target speaker embedding is a learned representation of the voice of the player, and (ii) source acoustic features for speech content in the voice of a source speaker;generating, as output of the acoustic feature encoder, one or more acoustic feature encodings, wherein generating the one or more acoustic feature encodings comprises generating an acoustic feature encoding for each input time step of a plurality of input time steps of the source acoustic features, wherein the acoustic feature encoding for each input time step comprises a combination of the target speaker embedding for the player and an encoding of the source acoustic features for the input time step;inputting, into an acoustic feature decoder of the voice convertor, the one or more acoustic feature encodings;and generating target acoustic features for generating speech audio data, comprising decoding the one or more acoustic feature encodings using the acoustic feature decoder, wherein the target acoustic features comprise acoustic features for the speech content in the voice of the player, wherein decoding the one or more acoustic feature encodings comprises, for each output time step of a plurality of output time steps: receiving the acoustic feature encoding for each input time step, generating, by an attention mechanism, an attention weight for each acoustic feature encoding, generating, by the attention mechanism, a context vector for the output time step by averaging each acoustic feature encoding using the respective attention weight, and processing, by the acoustic feature decoder, the context vector of the output time step to generate target acoustic features for the output time step.
- The method of claim 8, wherein the target speaker embedding is generated from output of a speaker encoder of the voice convertor, the generating comprising: inputting, into the speaker encoder, one or more examples of speech audio provided by the player;generating, as output of the speaker encoder, an embedding for each example of speech audio;and generating the target speaker embedding for the player based on the embeddings for each example.
- The method of claim 9, wherein the target speaker embedding for the player is an average of the embeddings generated for each example.
- The method of claim 9, wherein the speaker encoder comprises one or more recurrent layers.
- The method of claim 8, wherein the target speaker embedding is generated from output of a speaker encoder of the voice convertor, the generating comprising: inputting, into the speaker encoder, a speaker identifier for the player;and generating, as output of the speaker encoder, the target speaker embedding for the player.
- The method of claim 12, wherein the speaker encoder comprises one or more fully connected layers.
- The method of claim 8, wherein each of the one or more acoustic feature encodings comprise a combination of the target speaker embedding and an encoding of the source acoustic features.
- The method of claim 8, wherein at least one of the acoustic feature encoder or the acoustic feature decoder comprises one or more recurrent layers.
- A system for generating speech audio in a video game using a voice convertor that has been trained to convert acoustic features for a source speaker into acoustic features for a player of the video game, the system comprising: a synthesizer being configured to: receive input data representing speech content;and output source acoustic features for the speech content in the voice of a source speaker;a voice convertor comprising an acoustic feature encoder and an acoustic feature decoder, the voice convertor being configured to: input, into the acoustic feature encoder, (i) a target speaker embedding associated with a player of the video game, wherein the target speaker embedding is a learned representation of the voice of the player, and (ii) the source acoustic features;generate, as output of the acoustic feature encoder, one or more acoustic feature encodings, wherein generating the one or more acoustic feature encodings comprises generating an acoustic feature encoding for each input time step of a plurality of input time steps of the source acoustic features, wherein the acoustic feature encoding for each input time step comprises a combination of the target speaker embedding for the player and an encoding of the source acoustic features for the input time step;input, into the acoustic feature decoder, the one or more acoustic feature encodings;and output target acoustic features for generating speech, comprising decoding the one or more acoustic feature encodings using the acoustic feature decoder, wherein the target acoustic features comprise acoustic features for the speech content in the voice of the player, wherein decoding the one or more acoustic feature encodings comprises, for each output time step of a plurality of output time steps: receiving the acoustic feature encoding for each input time step, generating, by an attention mechanism, an attention weight for each acoustic feature encoding, generating, by the attention mechanism, a context vector for the output time step by averaging each acoustic feature encoding using the respective attention weight, and processing, by the acoustic feature decoder, the context vector of the output time step to generate target acoustic features for the output time step;and one or more modules configured to process the target acoustic features, the one or more modules comprising a vocoder configured to generate speech audio in the voice of the player.
- The system of claim 16, wherein the target speaker embedding is generated from output of a speaker encoder of the voice convertor, the generating comprising inputting player identifier data into the speaker encoder, wherein the player identifier data comprises one of: (i) acoustic features of one or more examples of speech audio provided by the player, or (ii) a speaker identifier for the player.
- The system of claim 16, wherein the voice convertor is further configured to: receive one or more examples of speech audio provided by the player;and update parameters of at least one of the acoustic feature encoder or the acoustic feature decoder, comprising processing the one or more examples of speech audio.
Disclaimer: Data collected from the USPTO and may be malformed, incomplete, and/or otherwise inaccurate.