U.S. Pat. No. 11,738,271
METHOD AND APPARATUS FOR PREDICTING GAME DIFFICULTY BY USING DEEP-LEARNING BASED GAME PLAY SERVER
AssigneeNHN Corp
Issue DateNovember 26, 2020
Illustrative Figure
Abstract
A method and apparatus for predicting game difficulty by using a deep-learning based game play server predict a difficulty of stage maps of a match puzzle game using a deep-learning based game play server that performs the match puzzle game and modify the stage maps. The deep-learning based game play server includes: a communicator configured to receive first stage maps of a first size and second stage maps of a second size; memory configured to store an agent model; at least one processor configured to perform learning of the agent model and perform the match puzzle game using the learned agent model.
Description
DESCRIPTION OF EXEMPLARY EMBODIMENTS The present disclosure may have various modifications and various embodiments, and specific embodiments will be illustrated in the drawings and described in detail in the detailed description. The technical effect and feature of the present disclosure and the method for attain it become clear by referring to the embodiments described below together with the drawings. However, the present disclosure may not be limited to the embodiments disclosed below but may be implemented in various forms. In the following embodiments, the terms “first” and “second” are used to distinguish one element from another element, and the scope of the present disclosure should not be limited by these terms. In addition, a singular expression should be interpreted that the singular expression includes a plural expression unless it does not mean otherwise in the context. Furthermore, the term “include” or “have” indicates that a feature or a component described in the specification is present but does not exclude a possibility of presence or addition of one or more other features or components in advance. In addition, for the convenience of description, sizes of components are enlarged or reduced in the drawings. For example, a size and a thickness of each component shown in the drawings arbitrarily for the convenience of description, and the present disclosure is not limited thereto. Hereinafter, preferred embodiments of the present disclosure will be described in detail with reference to the accompanying drawings and in describing the preferred embodiments with reference to the accompanying drawings, the same reference numeral will refer to the same or corresponding component regardless of the reference numeral and a duplicated description thereof will be omitted. FIG.1illustrates a system for predicting game difficulty by using a deep-learning based game play server according to an embodiment of the present disclosure. Referring toFIG.1, ...
DESCRIPTION OF EXEMPLARY EMBODIMENTS
The present disclosure may have various modifications and various embodiments, and specific embodiments will be illustrated in the drawings and described in detail in the detailed description. The technical effect and feature of the present disclosure and the method for attain it become clear by referring to the embodiments described below together with the drawings. However, the present disclosure may not be limited to the embodiments disclosed below but may be implemented in various forms. In the following embodiments, the terms “first” and “second” are used to distinguish one element from another element, and the scope of the present disclosure should not be limited by these terms. In addition, a singular expression should be interpreted that the singular expression includes a plural expression unless it does not mean otherwise in the context. Furthermore, the term “include” or “have” indicates that a feature or a component described in the specification is present but does not exclude a possibility of presence or addition of one or more other features or components in advance. In addition, for the convenience of description, sizes of components are enlarged or reduced in the drawings. For example, a size and a thickness of each component shown in the drawings arbitrarily for the convenience of description, and the present disclosure is not limited thereto.
Hereinafter, preferred embodiments of the present disclosure will be described in detail with reference to the accompanying drawings and in describing the preferred embodiments with reference to the accompanying drawings, the same reference numeral will refer to the same or corresponding component regardless of the reference numeral and a duplicated description thereof will be omitted.
FIG.1illustrates a system for predicting game difficulty by using a deep-learning based game play server according to an embodiment of the present disclosure.
Referring toFIG.1, the system for predicting game difficulty by using the deep-learning based game play server according to an embodiment may include a terminal100, a puzzle game server200, a game play server300and a game difficulty prediction server400.
Each of the elements of the system ofFIG.1may be connected through a network500. The network500may mean a connection structure available to data, signal and information exchange among the nodes such as the terminal100, the puzzle game server200, the game play server300and the game difficulty prediction server400. An example of the network may include 3GPP (3rd Generation Partnership Project) network, LTE (Long Term Evolution) network, WIMAX (World Interoperability for Microwave Access) network, Internet, LAN (Local Area Network), Wireless LAN (Wireless Local Area Network), WAN (Wide Area Network), PAN (Personal Area Network), Bluetooth network, Satellite broadcasting network, Analogue broadcasting network, DMB (Digital Multimedia Broadcasting), and the like, but not limited thereto.
First, the terminal100is a terminal of a user intended to receive a puzzle game service. For example, the terminal100may be configured to provide a user interface for the puzzle game service through an application, web and program. In addition, the terminal100is one or more computer or other electronic device used by the user to execute applications for performing various tasks. For example, the terminal100includes a computer, a laptop computer, a smart phone, a mobile telephone, a PDA, a tablet PC or an arbitrary other device available to operate to communicate with the puzzle game server200, but not limited thereto. The terminal100may include a processing logic for interpreting and executing multiples commands stored in a memory, and may include other various elements like processors that display graphic information for a graphic user interface (GUI) on an external input/output device. Furthermore, the terminal100may be connected to an input device (e.g., a mouse, a keyboard, a touch sensitive surface, etc.) and an output device (e.g., a display device, a monitor, a screen, etc.). The applications executed by the terminal100may include a game application, a web browser, a web application operating in a web browser, word processors, media players, spreadsheets, image processors, security software or the like.
In addition, the terminal100may include at least one memory101for storing commands, data, information and instructions, at least one processor102and a communication unit or communicator103.
The memory101of the terminal100may store one or more of application programs or applications operated in the terminal100, data for operating the terminal100, and commands or instructions. The commands or instructions may be executable by the processor102such that the processor102performs the commands or instructions for operations, and the operations may include, for example, but not limited to, a transmission of a puzzle game execution request signal, a transmission/reception of game data, a transmission/reception of action information, a transmission/reception of success rate for a stage map, a reception of various types of information, and a transmission and/or reception of any signal, data, information associated with the game service. Furthermore, the memory101may be various types of storage device such as ROM, RAM, EPROM, flash drive, hard drive, and the like as hardware, and the memory101may be a web storage that performs a storage function of the memory101on internet.
The processor102of the terminal100may control an overall operation of the terminal100and perform a data processing for a puzzle game service. When a puzzle game application is executed in the terminal100, a puzzle game environment is configured in the terminal100. And, the puzzle game application exchanges puzzle game data with the puzzle game server200through the network500to execute the puzzle game service on the terminal100. Such a processor102may be, for example, but not limited to, ASICs (application specific integrated circuits), DSPs (digital signal processors), DSPDs (digital signal processing devices), PLDs (programmable logic devices), FPGAs (field programmable gate arrays), controllers, micro-controllers, microprocessors, or any other processors for performing functions.
The communication unit103of the terminal100may transmit and receive a wireless or wired signal with at least one of a base station, an external terminal and a server on a network constructed based on the following communication scheme (e.g., GSM (Global System for Mobile communication), CDMA (Code Division Multi Access), HSDPA (High Speed Downlink Packet Access), HSUPA (High Speed Uplink Packet Access), LTE (Long Term Evolution), LTE-A (Long Term Evolution-Advanced), WLAN (Wireless LAN), Wi-Fi (Wireless-Fidelity), Wi-Fi (Wireless Fidelity) Direct, DLNA (Digital Living Network Alliance), WiBro (Wireless Broadband) and WiMAX (World Interoperability for Microwave Access).
A puzzle game may be, for example, but not limited to, a 3-match puzzle game, in which an action of arranging a manipulation puzzle is performed in a fixed puzzle arranged on a stage map, and when 3 or more puzzles of the same color is matched, the puzzles are removed and a score is obtained.
The puzzle game service provided by the puzzle game server200may be configured in a form in which a virtual computer player provided by the puzzle game server200and a real user take part in a game. Accordingly, in a puzzle game environment implemented on the terminal100of a user side, a real user and a virtual computer player play a game together. In other aspect, the puzzle game service provided by the puzzle game server200may be configured in a form in which a plurality of devices of user side takes part in a game and the puzzle game is played.
The puzzle game server200may include at least one memory201for storing commands, data, information and instructions, at least one processor202and a communication unit or communicator203.
The memory201of the puzzle game server200may store a plurality of application programs or applications operated in the puzzle game server200, data for operating the puzzle game server200, and commands or instructions. The commands or instructions may executable by the processor202such that the processor202performs operations of the puzzle game server200, and the operations may include a reception of a game execution request signal, a transmission/reception of game data, a transmission/reception of action information and various types of transmission operation, and a transmission and/or reception of any signal, data, information associated with the game service. Furthermore, the memory201may be various types of storage device such as ROM, RAM, EPROM, flash drive, hard drive, and the like as hardware, and the memory201may be a web storage that performs a storage function of the memory201on internet.
The processor202of the puzzle game server200may control an overall operation of the puzzle game server200and perform a data processing for a puzzle game service. Such a processor202may be ASICs (application specific integrated circuits), DSPs (digital signal processors), DSPDs (digital signal processing devices), PLDs (programmable logic devices), FPGAs (field programmable gate arrays), controllers, micro-controllers, microprocessors, or other processors of arbitrary shapes for performing functions.
The puzzle game server200may perform a communication with the terminal100, the game play server300and the game difficulty prediction server400via the network500through the communication unit or communicator203.
The game play server300may include a separate cloud server or a computing device. In addition, the game play server300may be a neural network system installed on the processor102of the terminal100or the data processor202of the puzzle game server200or a neural network system installed on a data processor402of the game difficulty prediction server400, but hereinafter, it is described that the game play server300is a separate device from the terminal100, the puzzle game server200or the game difficulty prediction server400for illustration purposes only.
The game play server300may include at least one memory301for storing commands, data, information and instructions, at least one processor302and a communication unit or communicator303.
The game play server300is an artificial intelligence computer that is available to construct an agent model which is a deep-learning model by learning autonomously a puzzle game rule and play a game in a stage map. The detailed exemplary embodiments for training the game play server300with the agent model will be described with reference toFIG.10toFIG.13.
The memory301of the game play server300may store a plurality of application programs or applications operated in the game play server300, data for operating the game play server300, and commands or instructions. The commands or instructions may be executable by the processor302such that the processor302performs operations of the game play server300, and the operations may include an agent model learning (training) operation, a transmission/reception of action information and various types of transmission operation. In addition, the memory301may store an agent model which is a deep-learning model. Furthermore, the memory301may store a success rate of the agent model, a stage map used in learning, a stage map not used in learning and training data set for learning. In addition, the memory301may be various types of storage device such as ROM, RAM, EPROM, flash drive, hard drive, and the like as hardware, and the memory301may be a web storage that performs a storage function of the memory301on internet.
The processor302of the game play server300reads out the agent model stored in the memory302and perform an agent model learning and manipulation puzzle action described below according to the constructed neural network system. In one embodiment, the processor302may include a main processor for controlling the whole units of the game play server300and a plurality of Graphic Processing Units (GPUs) for processing large amount of operations required when driving a neural network according to the agent model.
The game play server300may perform a communication with the puzzle game server200or the game difficulty prediction server400via the network500through the communication unit or communicator303.
The game difficulty prediction server400may include a separate cloud server or a computing device. In addition, the game difficulty prediction server400may be a neural network system installed on the processor102of the terminal100or the data processor202of the puzzle game server200, but hereinafter, it is described that the game difficulty prediction server400is a separate device from the terminal100or the puzzle game server200for illustration purposes only.
The game difficulty prediction server400may include at least one memory401for storing commands, data, information and instructions, at least one processor402and a communication unit or communicator403.
The game difficulty prediction server400may receive a user success rate from the puzzle game server200or a success rate of an agent model from the game play server300through the communication unit403. The game difficulty prediction server400may learn a game difficulty prediction model using the received user success rate and the received success rate of the agent model. The detailed description for the game difficulty prediction server400for learning the game difficulty prediction model based on the game difficulty prediction model is described with reference toFIG.5. Furthermore, in the game difficulty prediction server400, a game difficulty adjusting unit may adjust a game difficulty of a stage map based on the predicted game difficulty. The detailed description for game difficulty adjustment is described with reference toFIG.6toFIG.9.
The memory401of the game difficulty prediction server400may store one or more of application programs or applications operated in the game difficulty prediction server400, data for operating the game difficulty prediction server400and commands or instructions. The commands or instructions may be executable by the processor402such that the processor402performs operations of the game difficulty prediction server400, and the operations may include a game difficulty prediction model learning (training) operation, a performance of game difficulty prediction, an adjustment of game difficulty of a stage map and various types of transmission operation. In addition, the memory401may store a game difficulty prediction model and a game difficulty adjustment unit which are a deep-learning model. Furthermore, the memory401may be various types of storage device such as ROM, RAM, EPROM, flash drive, hard drive, and the like as hardware, and the memory401may be a web storage that performs a storage function of the memory401on internet.
The processor402of the game difficulty prediction server400reads out a game difficulty prediction model stored in the memory402and perform a game difficulty prediction or a game difficulty adjustment for a stage map described below according to the constructed neural network system. In one embodiment, the processor402may include a main processor for controlling the whole units the game difficulty prediction server400and a plurality of Graphic Processing Units (GPUs) for processing large amount of operations required when driving a neural network according to the game difficulty prediction model.
The game difficulty prediction server400may perform a communication with the puzzle game server200or the game play server300via the network500through the communication unit or communicator403.
FIG.2is a diagram for illustrating an agent model for an action in a stage map in a deep-learning based game play server according to an embodiment of the present disclosure.FIG.3illustrates an example for showing an action scheme of the agent model shown inFIG.2, andFIG.4illustrates another example for showing an action scheme of the agent model shown inFIG.2.
An agent model310according to an embodiment of the present disclosure may be a deep-learning model of the game play server300. The agent model310may perform any one action O of available actions A for a current state S of a stage map. Particularly, the agent model310may perform an action O of obtaining a high score in the current state S of the stage map. For example, referring toFIG.2, the stage map may include 9 sections in horizontal and 12 sections in vertical. In the stage map, a fixed puzzle fp of 1 section size and 4 types of colors may be arranged. A manipulation puzzle cp has 2 section size and configured with 2 colors or only a color of the corresponding 4 types of colors of the fixed puzzle fp. The agent model310may manipulate or move the manipulation puzzle cp such that the colors of the manipulation puzzle cp and the fixed puzzle fp are matched as the same as each other. The available action A of the agent model310may include a position change, a rotation, and the like. In one example, referring toFIG.3, the available action A of the agent model310may include one or more basic actions BAs and one or more specific actions SAs. The basic action BA may be an action of changing a direction or a position of the manipulation puzzle cp to arrange it on the stage map. The basic action BA may include 432 (9×12×4) types of actions considering stage map sizes and puzzle colors. The specific action SA may include a skill action and a switch action. The switch action is an action of changing an order of the manipulation puzzles cp arranged in order, which are randomly generated. In another example, referring toFIG.4, the available action A of the agent model310may include one or more basic actions BAs, one or more specific actions SAs and one or more preparation actions PAs. The description of the basic action BA and the specific action SA are the same as the example described above. The preparation action PA is an action of selecting a candidate puzzle to be used in the basic action BA as much as a predetermined number in the manipulation puzzles cp before starting a game. That is, in the case that the agent model310performs an action A including the preparation action PA, the agent model310may select a candidate of the manipulation puzzles cp to be used in a game play through the preparation action PA before starting a game. In addition, the preparation action PA may select any one specific action of a plurality of specific actions SA as a candidate specific action before starting a game and perform the candidate specific action during the game play.
Furthermore, the agent model310may perform a 3-match puzzle game even in a new map which is not learned. The method of learning for the agent model310to perform 3-match puzzle game even in a new map is based on the agent model learning method shown inFIG.10toFIG.13.
FIG.5is a diagram for illustrating a method of generating a game difficulty prediction model in a game difficulty prediction server according to an embodiment of the present disclosure, andFIG.6is a diagram for illustrating a method of predicting a game difficulty and adjusting the game difficulty for a new map in a game difficulty prediction server according to an embodiment of the present disclosure.FIG.7is an exemplary diagram of a stage map according to a game difficulty according to an embodiment of the present disclosure, andFIG.8is a diagram for illustrating a method of adjusting a game difficulty of a stage map according to an embodiment of the present disclosure.FIG.9is an exemplary diagram of setting a game difficulty according to a stage of a stage map according to an embodiment of the present disclosure.
A game difficulty prediction model410may predict a game difficulty for a stage map which is not learned. Referring toFIG.5, in order for the game difficulty prediction model410to predict a game difficulty for a stage map which is not learned, learning needs to be performed by using a success rate of an agent model310(ASR) for a learned stage map SM and a success rate of a user110(USR). The success rate of the user110(USR) may be a success rate stored in the terminal100. The learning method of the game difficulty prediction model410is, for example, but not limited to, performing a linear analysis using a difference between the success rate of the user110(USR) for the learned stage map (SM) and the success rate of the agent model310(ASR) for the learned stage map (SM). One example of the linear analysis is binomial regression analysis. The success rate may be a rate of the number of successes of clearing a game with respect to the number of trials of a game play in a stage map. The learned stage map (SM) may be a learned stage map of the agent model310or a stage map provided from the puzzle game server200on the terminal100of the user110. Referring toFIG.6, as a result of the learning, according to the game difficulty prediction model410, when a user inputs the success rate of the agent model310(ASR), a predicted USR (PUSR) becomes predictable, and therefore, a game difficulty may be predicted. The game difficulty prediction model410may output the predicted stage rate of a user (PUSR) with the success rate of the agent model310(ASR) as an input according to Equation 1.
PUSR=λ1×ASR+λ2×F1+λ3×F2× (Equation 1)
In Equation 1, λ1is a hyper parameter of the success rate of the agent model310(ASR). F1, F2, . . . are one or more unique properties for a stage map. λ2, λ3, . . . are hyper parameters for respective unique properties of the stage map.
In addition, the game difficulty prediction server400may adjust a stage map which is not learned (NM), that is a game difficulty for a new map by using the game difficulty prediction model410and a game difficulty adjustment unit420. The difficulty of the stage map may be determined according to the number of fixed puzzles, a degree of adjacency of fixed puzzle, the number of usable manipulation puzzles, an arrangement of fixed puzzle, and the like. In one example,FIG.7shows an example of a stage map in which as a level of game difficulty increases from level1to level10, the number of fixed puzzles is increased, and an adjacency of a fixed puzzle of the same color is increased, and therefore, a game difficulty is also increased. That is, as the game difficulty increases, it becomes harder to remove a fixed puzzle with 3-match with an action of a manipulation puzzle. Furthermore, the game difficulty prediction server400may receive a success rate of the agent model310(ASR) by playing a stage map which is not learned (NM) with the agent model310. The game difficulty prediction server400may calculate a predicted stage rate of a user (PUSR) with the success rate of the agent model310(ASR) as an input by using the game difficulty prediction model410. The game difficulty prediction server400may adjust a game difficulty of the stage map which is not learned (NM) by the game difficulty adjustment unit420based on the predicted stage rate of a user (PUSR). The game difficulty adjustment is performed by adjusting the number of fixed puzzles, a degree of adjacency of fixed puzzle, the number of usable manipulation puzzles, an arrangement of fixed puzzle, and the like. In one example, in order to higher a game difficulty, the number of fixed puzzles may be increased, fixed puzzles of the same color are arranged farther, or the number of usable manipulation puzzles may be decreased. In order to lower a game difficulty, the number of fixed puzzles may be decreased, fixed puzzles of the same color are arranged closer with each other, or the number of usable manipulation puzzles may be increased. For example, referring toFIG.8, the game difficulty prediction server400evaluates a difficulty of a stage map. In the case that the difficulty is evaluated to be high, the game difficulty prediction server400may decrease the number of fixed puzzles and changes an adjustment of the fixed puzzles, and accordingly, may lower the difficulty of the game.
Referring toFIG.9, the game difficulty prediction server400may increase a difficulty of a stage map as a stage of the stage map goes up, and may decrease a difficulty of the next stage of n+5 stage lower than a difficulty of the previous stage. Herein, n is a natural number. That is, a difficulty of n+6 stage may be lower than a difficulty of n+5 stage. In the case that a game difficulty becomes higher continually as a stage goes up, a user may feel that the game is difficult and lose an interest on playing the game. Accordingly, the game difficulty prediction server400of the present disclosure may adjust a game difficulty in such a way of increasing and decreasing, and increasing again, and therefore, induce an interest of a user to enjoy playing the game.
Accordingly, an apparatus for predicting game difficulty by using a deep-learning based game play server according to an embodiment of the present disclosure may predict a difficulty of a stage map and modify the stage map by using the deep-learning based game play server that performs 3-match puzzle game. Furthermore, an apparatus for predicting game difficulty by using a deep-learning based game play server according to an embodiment of the present disclosure may provide a game play server for which a game play is available even in a new map which is not learned. In addition, a method and apparatus for predicting game difficulty by using a deep-learning based game play server according to embodiments of the present disclosure may predict a game difficulty for a new stage map. Furthermore, an apparatus for predicting game difficulty by using a deep-learning based game play server according to an embodiment of the present disclosure may adjust a game difficulty of a stage map and induce an interest in playing a game.
FIG.10is a flowchart for a deep-learning based game play service method according to an embodiment of the present disclosure, andFIG.11is an exemplary diagram for a plurality of second stage maps of the deep-learning based game play service method shown inFIG.10.FIG.12is an exemplary diagram for describing a method for generating a plurality of partition stage maps and generating a training data set of the deep-learning based game play service method shown inFIG.10.
A deep-learning based game play service method may perform a 3-match puzzle game in which an action of arranging a manipulation puzzle is performed in a fixed puzzle arranged on a stage map, and when three or more puzzles of the same color are matched, the puzzles are removed and a score is obtained.
Referring toFIG.10, the deep-learning based game play service method according to an embodiment of the present disclosure may include a step S1001of receiving a plurality of first stage maps of a first size and a plurality of second stage maps of a second size. Particularly, the first stage map is the first size, and the second stage map is the second size. The first stage map is a stage map that the actual puzzle game server200provides to the terminal100. The second stage map is a stage map used for an agent model's learning. The first size of the first stage map may be greater than the second size of the second stage map. That is, the second stage map may be a mini map of, or be smaller than, the first stage map. In one example, the first size of the first stage map may be 9×12 size as shown inFIG.2andFIG.7. The second size of the second stage map (MM) may be 5×5 size as shown inFIG.11.
In addition, the deep-learning based game play service method according to an embodiment of the present disclosure may include a step S1002of performing first reinforcement learning of the agent model310so as to perform an action of obtaining a high score for a plurality of second stage maps (MM). Particularly, the game play server300may perform a reinforcement learning using the second stage map (MM), not the first stage map to perform the first reinforcement learning. In the case of performing the reinforcement learning using the first stage map from the start, there are many numbers of cases since the size of the first stage map is too large. Accordingly, there is a problem that the agent model310cannot be learned. Therefore, in the case of using the second stage map, which is a mini map of, or is smaller than, the first stage map of small number of cases, the agent model310may perform a game play for the second stage map and obtain a score to perform a reinforcement learning. The first reinforcement learning may use Random Network Distillation (RND). The RND may include target, prediction and policy neural networks. The policy neural network is a neural network for determining an action of the agent, and the target and prediction neural networks are neural network of receiving a next state value as an input and outputting a certain feature value. A weight for the target neural network is randomly set and fixed. The prediction neural network is a neural network having the same structure as the target neural network and learned to output the same output of the target neural network. That is, since there is an effect of distillation of a random neural network to the prediction neural network, it is called a random network distillation. In the RND, a method is selected, in which a value function for an intrinsic reward and a value function for an extrinsic reward are obtained separately and combined, and Proximal Policy Optimization (PPO) is used for optimizing the policy neural network. Furthermore, when performing the first reinforcement learning of the agent model310, the game play server300may mix the second stage map (MM) with gaussian noise to input. In this case, the learning of the agent model310may be more efficiently performed. In addition, when inputting a plurality of second stage maps in the case of performing the first reinforcement learning of the agent model310, the game play server300may perform the reinforcement learning by inputting in an order from a map of which game difficulty is low to a map of which game difficulty is high. Accordingly, the learning of the agent model may be more efficiently performed.
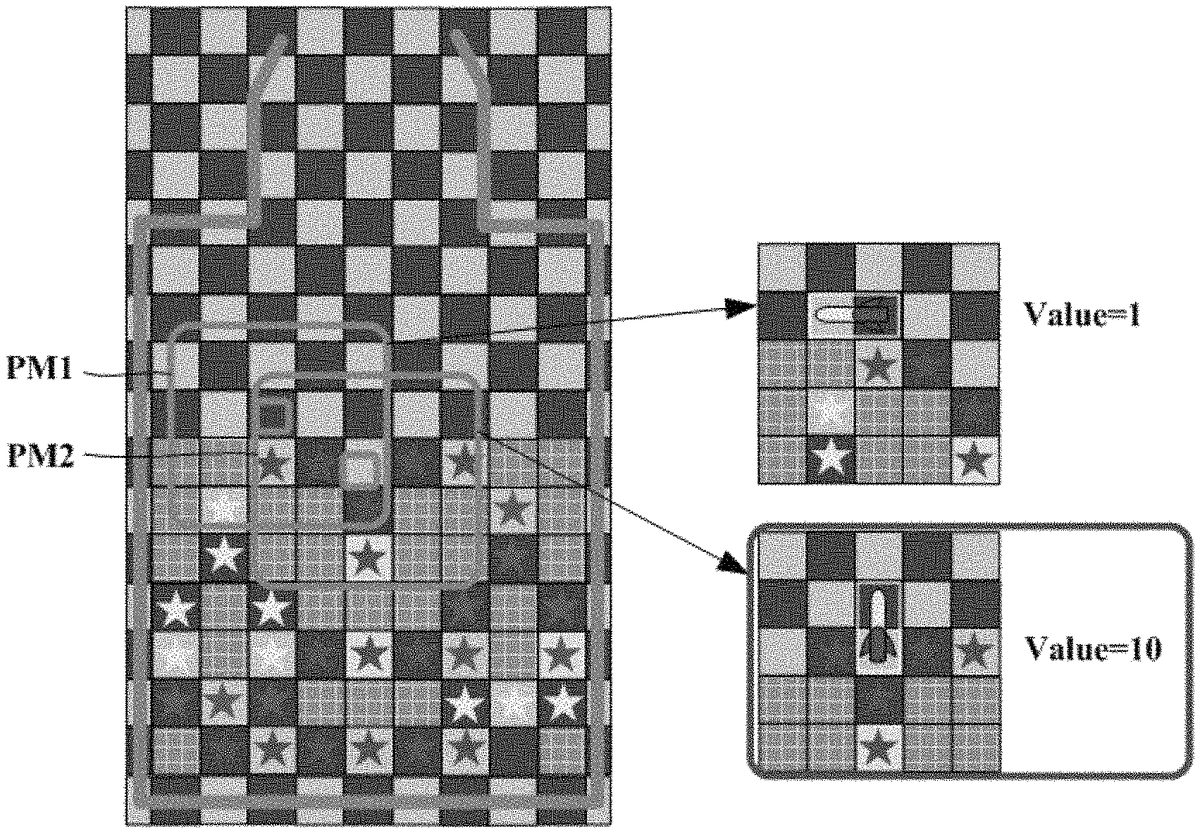
Furthermore, the deep-learning based game play service method according to an embodiment of the present disclosure may include a step S1003of arranging a plurality of first stage maps around a fixed puzzle at the center as much as the number of fixed puzzles and generating a plurality of partition stage maps of a second size. In one example, as shown inFIG.12, a plurality of partition stage maps (PM) may be generated around a fixed puzzle at the center in a certain stage map.FIG.12shows a first partition stage map PM1and a second partition stage map PM2. The partition stage map PM partitions a window as much as a predetermined area in a stage map. In one example, a size of the partition stage map may be 5×5 size. The game play server300enables the agent model310learned with a stage map of a second size to determine an action of a manipulation puzzle for each of the partition stage maps of the second size in a first stage map.
In addition, the deep-learning based game play service method according to an embodiment of the present disclosure may include a step S1004of generating a training data set with each of a plurality of first stage maps as an input data and an action of a partition stage map of an action of obtaining a highest score among actions for a plurality of partition stage maps of a second size as a correct answer label. More particularly, the game play server300selects an action in a partition game map of performing an action of the agent model310obtaining a highest score among actions for a plurality of partition stage maps existed in a predetermined first stage map and performs an action in the first stage map. That is, the agent model310selects the best action among a plurality of partition stage maps. In one example, as shown inFIG.12, there are the first partition stage map PM1and the second partition stage map PM2in the first stage map. The score obtained by arranging a manipulation puzzle on a fixed puzzle and 3-match removing in the first partition stage map PM1is 1 point. The score obtained by arranging a manipulation puzzle on a fixed puzzle and 3-match removing in the second partition stage map PM2is 10 points. The action in the second partition stage map PM2may obtain higher score than the action in the first partition stage map PM1. In addition, the game play server300may designate an action in the second partition stage map PM2as a correct answer label for the first stage map and include a predetermined first stage map and the second partition stage map PM2in a training data set. The game play server may generate a correct answer label for a plurality of the first stage map and collect a training data set in the same way. Furthermore, when inputting a plurality of first stage maps in the case of performing teacher learning of the agent model310, the game play server300may perform the reinforcement learning by inputting in an order from a map of which game difficulty is low to a map of which game difficulty is high. In this case, the training data set may be configured in an order from a map of which game difficulty is low to a map of which game difficulty is high.
Furthermore, the deep-learning based game play service method according to an embodiment of the present disclosure may include a step S11005of performing teacher learning of a first reinforcement learned agent model by using a training data set. More particularly, the game play server300may perform teacher learning of the agent model310which is first reinforcement-learned for the second stage map of the second size by using the training data set which is obtained using the partition stage map of the first stage map. Accordingly, the teacher-learned agent model310may perform a game play even for the first stage map of the first size even in the case of not partitioning the stage map. Furthermore, the game play server300may sequentially input the training data set in an order from a map of which game difficulty is low to a map of which game difficulty is high and may learn it more efficiently.
In addition, the deep-learning based game play service method according to an embodiment of the present disclosure may include a step S1006of performing second reinforcement learning of the agent model which is teacher-learned for a plurality of the first stage maps. More particularly, the teacher-learned agent model may perform a game play in some degree for the first stage map having many numbers of cases, but since the agent model is not learned with a partition stage may and considering an empty space between the partition stage maps, a case may occur that the agent model does not perform an action of obtaining the highest score. Accordingly, the game play server300makes the agent model310, which is available to play in the first stage map, perform the second reinforcement learning for a plurality of first stage maps one more time. The second reinforcement learning may use the RND and the PPO like the first reinforcement learning. In addition, when performing the second reinforcement learning, the game play server300may mix the first stage map with gaussian noise to input. In this case, learning of the agent model310may be more efficiently performed.
Accordingly, the method for predicting game difficulty by using a deep-learning based game play server according to an embodiment of the present disclosure may provide a game play server for which a game play is available for a new stage map which is not learned.
FIG.13illustrates a graph for comparison between an agent model of an exemplary embodiment of the present disclosure and an agent model of conventional art.
Referring toFIG.13, the performance between the case of learning an agent model according to a deep-learning based game play service method according to the exemplary embodiment of the present disclosure and the case of learning an agent model according to the conventional art is compared. The performances of the agent models are similar for level5or lower in a stage map. However, there is a difference in performance in level10which is the highest level in the stage map. First, the success rate of the agent model learned with MCTS algorithm, CNN teacher learning and 9×12 reinforcement learning, which are learning methods according to the conventional art is abruptly decreased. However, the method of partitioning a stage map and reinforcement learning according to the exemplary embodiment of the present disclosure shows high success rate even in the stage map of level10. Furthermore, the agent model reinforcement learned in 9×12 stage map after reinforcement learned in the partition stage map shows the highest success rate in level10.
FIG.14is a flowchart for illustrating a method for predicting game difficulty based on deep-learning according to an embodiment of the present disclosure.
The method for predicting game difficulty based on deep-learning according to an embodiment of the present disclosure relates to a 3-match puzzle game in which a deep-learning based game difficulty prediction server performs an action of arranging a manipulation puzzle in a fixed puzzle arranged on a stage map, and when three or more puzzles of the same color are matched, the puzzles are removed and a score is obtained, and accordingly, may predict a user difficulty for a stage map which is not learned.
Referring toFIG.14, the method for predicting game difficulty based on deep-learning according to an embodiment of the present disclosure may include a step S1401of receiving a user success rate for a stage map which is not learned and a stage map which is learned.
In addition, the method for predicting game difficulty based on deep-learning according to an embodiment of the present disclosure may include a step S1402of learning a game difficulty prediction model through binomial regression analysis using a difference between a success rate of an agent model and a success rate of a user. The method of learning the game difficulty prediction model410is described with reference toFIG.5.
Furthermore, the method for predicting game difficulty based on deep-learning according to an embodiment of the present disclosure may include a step S1403of calculating a success rate of the agent model for the stage map which is not learned. More particularly, the success rate of the learned agent model is a success rate the agent model310performs a game for the stage map which is not learned to obtain.
In addition, the method for predicting game difficulty based on deep-learning according to an embodiment of the present disclosure may include a step S1404of predicting a success rate of a user for the stage map which is not learned with a success rate of the agent model for the stage map which is not learned through the game difficulty prediction model as an input. The method of predicting a success rate of a user is described with respect toFIG.6.
Furthermore, the method for predicting game difficulty based on deep-learning according to an embodiment of the present disclosure may include a step S1405of modifying a difficulty of the stage map which is not learned using the predicted success rate of a user for the stage map which is not learned. The method of modifying a difficulty of the stage map which is not learned is described with respect toFIG.6toFIG.9.
Accordingly, a method for predicting game difficulty by using a deep-learning based game play server according to an embodiment of the present disclosure may predict a difficulty of a stage map and modify the stage map by using the deep-learning based game play server that performs 3-match puzzle game. In addition, a method for predicting game difficulty by using a deep-learning based game play server according to an embodiment of the present disclosure may predict a game difficulty for a new stage map. Furthermore, a method for predicting game difficulty by using a deep-learning based game play server according to an embodiment of the present disclosure may adjust a game difficulty of a stage map and induce an interest in playing a game.
Some embodiments of the present disclosure described so far may be implemented in a form of program commands to be executed by various computer elements and recorded in a storage medium which is readable by a computer. The storage medium readable by a computer may include program commands, data files, data structures, and the like separately or in combined manner. The program commands recorded in the storage medium readable by a computer may be designed specifically for the present disclosure or published and usable by a skilled person in the art of a computer software field. An example of the storage medium readable by a computer may include a magnetic medium including a hard disk, a floppy disk and a magnetic tape, an optical recording medium like CD-ROM and DVD, a magneto-optical medium like a floptical disk, and a hardware device specifically configured to store and execute program commands such as ROM, RAM, flash memory, and the like. An example of program commands include a high level language executable by a computer using an interpreter as well as a machine language such as those made by a compiler. The hardware device may be modified by one or more software modules to perform a process according to the present disclosure, and vice versa.
The specific executions described in the present disclosure are embodiments but does not limit the scope of the present disclosure in any way. For the conciseness of the specification, the conventional electronic elements, control systems, software and description of other functional aspects of the systems may be omitted. Furthermore, connection lines or connection elements between elements shown in the drawing illustrate exemplary functional connection and/or physical or circuit connections, but may be represented by various functional connections, physical connections or circuit connections which are replaceable or additional. In addition, unless there are detailed mentions such as “essential” or “important”, the element may not be an essential element for operation of the present disclosure.
Although the description of the present disclosure has been described with reference to a preferred embodiment, but it will be appreciated by those skilled in the art to which the present disclosure pertains that various modifications and changes may be made from the above description within the range of the concept and technical area of the present disclosure written in the claims. Accordingly, the technical scope of the present disclosure is not limited by the contents described in the specification but determined by the claims.
DETAILED DESCRIPTION OF MAIN ELEMENTS
100: terminal200: puzzle game server210: agent model300: game play server400: game difficulty prediction server410: game difficulty prediction model
Claims
- A deep-learning based game play server configured to perform an action of arranging a manipulation puzzle in fixed puzzles arranged on a stage map and perform a match puzzle game in which when a predetermined number or more puzzles of a same color are arranged to be matched, the matched puzzles are removed and a score is provided, the deep-learning based game play server comprising: at least one communicator configured to receive a plurality of first stage maps of a first size and a plurality of second stage maps of a second size;a memory configured to store a deep-learning based agent model;at least one processor configured to perform learning of the deep-learning based agent model by reading out the deep-learning based agent model and perform the match puzzle game using the learned deep-learning based agent model, the at least one processor configured to: perform first reinforcement learning of the deep-learning based agent model to perform an action of obtaining the score on the plurality of second stage maps, generate a plurality of partition stage maps, wherein each of the plurality of partition stage maps is a part of the plurality of first stage maps with the second size, and includes one or more of the fixed puzzles, generate a training data set with each of the plurality of first stage maps as an input data and an action of obtaining a highest score among actions on the plurality of partition stage maps as a correct answer label, perform teacher learning of the deep-learning based agent model, performed of the first reinforcement learning, by using the training data set, and perform second reinforcement learning of the deep-learning based agent model, performed of the teacher-learning, for the plurality of the first stage maps.
- The deep-learning based game play server of claim 1, wherein the plurality of first stage maps and the plurality of second stage maps have game difficulties according to arrangement of the fixed puzzles, and wherein the at least one processor is configured to perform the learning of the deep-learning based agent model by inputting in an order from a map of which game difficulty is lowest to a map of which game difficulty is highest, when the plurality of first stage maps and the plurality of second stage maps are input into the deep-learning based agent model.
- The deep-learning based game play server of claim 1, wherein the at least one processor is configured to perform the learning of the deep-learning based agent model by additionally inputting gaussian noise to the first reinforcement learning and/or the second reinforcement learning.
- The deep-learning based game play server of claim 1, wherein a selection order of the manipulation puzzle is determined randomly with a predetermined number of colors when the match puzzle game starts, wherein the action includes a basic action and a switch action, wherein the basic action is an action of changing a direction or a position of the manipulation puzzle to arrange the manipulation puzzle on the stage map, and wherein the switch action is an action of changing an order of the manipulation puzzle.
- The deep-learning based game play server of claim 1, wherein the manipulation puzzle has a predetermined number of colors, wherein the action includes a preparation action and a basic action, wherein the preparation action is an action of selecting a candidate puzzle to be used as the basic action, and wherein the basic action is an action of changing a direction or a position of the candidate puzzle to arrange the manipulation puzzle on the stage map.
- A deep-learning based game difficulty prediction server associated with a match puzzle game in which an action of arranging a manipulation puzzle in fixed puzzles arranged on a stage map is performed and, when a predetermined number or more puzzles of a same color are matched, the matched puzzles are removed and a score is provided to a user, and predicting a user difficulty for a stage map which is not learned, the deep-learning based game difficulty prediction server comprising: at least one communicator configured to receive a success rate of the user for the stage map which is not learned and a success rate of the user for a stage map which is learned;at least one memory configured to store a deep-learning based agent model, a game difficulty prediction model and a success rate of the deep-learning based agent model for the stage map which is learned;and at least one processor configured to perform learning of the game difficulty prediction model by reading out the game difficulty prediction model and predict a game difficulty for the stage map, which is not learned, by using the learned game difficulty prediction model, wherein the at least one processor is configured to: perform learning of the game difficulty prediction model through binomial regression analysis using a difference between the success rate of the deep-learning based agent model for the stage map which is learned and the success rate of the user for the stage map which is learned, calculate a success rate of the deep-learning based agent model for a remaining stage map which is not learned, predict a success rate of the user for the remaining stage map, which is not learned, by inputting the success rate of the deep-learning based agent model for the remaining stage map, which is not learned, to the game difficulty prediction model, wherein the communicator is configured to receive a plurality of first stage maps of a first size and a plurality of second stage maps of a second size, and wherein the at least one processor is configured to: perform first reinforcement learning of the deep-learning based agent model to perform an action of obtaining the score on the plurality of second stage maps, generate a plurality of partition stage maps, wherein each of the plurality of partition stage maps is a part of the plurality of first stage maps with the second size, and includes one or more of the fixed puzzles, generate a training data set with each of the plurality of first stage maps as an input data and an action of obtaining a highest score among actions on the plurality of partition stage maps as a correct answer label, perform teacher learning of the deep-learning based agent model, performed of the first reinforcement learning, by using the training data set, and perform second reinforcement learning of the deep-learning based agent model, performed of the teacher-learning, for the plurality of the first stage maps.
- The deep-learning based game difficulty prediction server of claim 6, wherein the at least one processor is configured to modify a difficulty of the stage map which is not learned using the success rate of the user for the stage map which is not learned.
- The deep-learning based game difficulty prediction server of claim 7, wherein the at least one processor is configured to increase a difficulty of the stage map which is not learned as a stage of the stage map goes up and decrease the difficulty of the stage map at predetermined stages.
- The deep-learning based game difficulty prediction server of claim 7, wherein the at least one processor is configured to decrease the difficulty by arranging one of the fixed puzzles on a position adjacent to another of the fixed puzzles, of which color is identical to a color of the one of the fixed puzzles, in the stage map which is not learned.
- A deep-learning based game play service method performing an action of arranging a manipulation puzzle in fixed puzzles arranged on a stage map and performing a match puzzle game in which when a predetermine number or more puzzles of a same color are arranged to be matched, the matched puzzles are removed and a score is provided, the method performed by a deep-learning based game play server comprising: receiving, by a communicator, a plurality of first stage maps of a first size and a plurality of second stage maps of a second size;performing, by a processor, first reinforcement learning of the deep-learning based agent model to perform an action of obtaining the score on the plurality of second stage maps, generating, by the processor, a plurality of partition stage maps, wherein each of the plurality of partition stage maps is a part of the plurality of first stage maps with the second size, and includes one or more of the fixed puzzles, generating, by the processor, a training data set with each of the plurality of first stage maps as an input data and an action of obtaining a highest score among actions on the plurality of partition stage maps as a correct answer label, performing, by the processor, teacher learning of the deep-learning based agent model, performed of the first reinforcement learning, by using the training data set, and performing, by the processor, second reinforcement learning of the deep-learning based agent model, performed of the teacher-learning, for the plurality of the first stage maps.
- The deep-learning based game play service method of claim 10, wherein the plurality of first stage maps and the plurality of second stage maps have game difficulties according to arrangement of the fixed puzzles, and wherein the performing of the first reinforcement learning of the deep-learning based agent model comprises inputting in an order from a map of which game difficulty is lowest to a map of which game difficulty is highest, when the plurality of second stage maps are input into the deep-learning based agent model to perform learning of the deep-learning based agent model.
- The deep-learning based game play service method of claim 10, wherein the plurality of first stage maps and the plurality of second stage maps have game difficulties according to arrangement of the fixed puzzles, and wherein the performing of the second reinforcement learning of the deep-learning based agent model comprises inputting in an order from a map of which game difficulty is low to a map of which game difficulty is high, when the plurality of first stage maps are input into the deep-learning based agent model to perform learning of the deep-learning based agent model.
- The deep-learning based game play service method of claim 10, further comprising inputting gaussian noise to input of the first reinforcement learning and/or the second reinforcement learning of the deep-learning based agent model.
- The deep-learning based game play service method of claim 10, wherein a selection order of the manipulation puzzle is determined randomly with a predetermined number of colors when the match puzzle game starts, wherein the action includes a basic action and a switch action, wherein the basic action is an action of changing a direction or a position of the manipulation puzzle to arrange the manipulation puzzle on the stage map, and wherein the switch action is an action of changing an order of the manipulation puzzle.
- The deep-learning based game play service method of claim 10, further comprising: performing learning of a game difficulty prediction model by reading out the game difficulty prediction model and predicting a game difficulty for a stage map, which is not learned, by using the learned game difficulty prediction model.
- The deep-learning based game play service method of claim 15, wherein the performing of the learning of the game difficulty prediction model includes: performing learning of the game difficulty prediction model through binomial regression analysis using a difference between a success rate of the deep-learning based agent model for a stage map which is learned and a success rate of a user for the stage map which is learned, calculating a success rate of the deep-learning based agent model for a remaining stage map which is not learned, and predicting a success rate of the user for the remaining stage map, which is not learned, by inputting the success rate of the deep-learning based agent model for the remaining stage map, which is not learned, to the game difficulty prediction model.
- The deep-learning based game play service method of claim 16, further comprising modifying a difficulty of the stage map which is not learned using the success rate of the user for the stage map which is not learned.
- The deep-learning based game play service method of claim 17, wherein the modifying of the difficulty of the stage map which is not learned includes increasing a difficulty of the stage map which is not learned as a stage of the stage map goes up and decreasing the difficulty of the stage map at predetermined stages.
- The deep-learning based game play service method of claim 17, wherein the modifying of the difficulty of the stage map which is not learned includes decreasing the difficulty by arranging one of the fixed puzzles on a position adjacent to another of the fixed puzzles of which color is identical to a color of the one of the fixed puzzles, in the stage map which is not learned.
Disclaimer: Data collected from the USPTO and may be malformed, incomplete, and/or otherwise inaccurate.