U.S. Pat. No. 11,478,704
IN-GAME VISUALIZATION OF SPECTATOR FEEDBACK
AssigneeSony Interactive Entertainment Inc
Issue DateNovember 4, 2020
Illustrative Figure
Abstract
Methods and systems are provided for displaying voice input of a spectator in a video game. The method includes receiving, by a server, the voice input produced by the spectator while viewing video game video of the video game. The method includes examining, by the server, the voice input to identify speech characteristics associated with the voice input of the spectator. The method includes processing, by the server, the voice input to generate a spectator video that includes text images representing the voice input of the spectator. In one embodiment, the text images are configured to be adjusted in visual appearance based on the speech characteristics of the voice input, wherein the text images are directed in a field of view of an avatar of the spectator. The method includes combining, by the server, video game video with the spectator video to produce an overlay of the text images graphically moving in toward a game scene provided by the video game video. The method includes sending, to a client device, a spectator video stream that includes the overlay of the text images.
Description
DETAILED DESCRIPTION The following implementations of the present disclosure provide methods, systems, and devices for displaying voice input of a spectator in a video game. In particular, while viewing the gameplay of players playing a video game, spectators may comment and react to what is occurring in the gameplay. The comments and verbal reactions of the spectators can be depicted in the scenes of the gameplay and an avatar of the spectator is depicted verbalizing the comments of the spectator. This facilitates an in-game visualization of the spectator comments which can be seen and heard by viewers viewing the gameplay. For example, while watching an E-sports event that involves a soccer match, a spectator can comment on the gameplay and verbally cheer for their favorite players and team. The spectator comments are processed and text images representing the spectator comments are displayed within the scenes of the gameplay which can be seen by the players competing in the game and other spectators viewing the game. Generally, the methods described herein provides a way for spectator comments to be visually depicted in the game scenes which in turn can enhance viewer engagement and can further improve communication amongst all the individuals viewing and participating in the gameplay. As used herein, the term “walla” should be broadly understood to refer to the in-game visualization of sound or speech (e.g., talking, signing, laughing, crying, screaming, shouting, yelling, etc.) produced by spectators of a game. In one embodiment, the spectators may be a person or a combination of people which may be visually depicted (e.g., as characters or avatars) in the scenes of a video game or any other media content. For purposes of clarity, references to “walla” should be taken in the general broad sense where spectator feedback and/or reaction to a game ...
DETAILED DESCRIPTION
The following implementations of the present disclosure provide methods, systems, and devices for displaying voice input of a spectator in a video game. In particular, while viewing the gameplay of players playing a video game, spectators may comment and react to what is occurring in the gameplay. The comments and verbal reactions of the spectators can be depicted in the scenes of the gameplay and an avatar of the spectator is depicted verbalizing the comments of the spectator. This facilitates an in-game visualization of the spectator comments which can be seen and heard by viewers viewing the gameplay. For example, while watching an E-sports event that involves a soccer match, a spectator can comment on the gameplay and verbally cheer for their favorite players and team. The spectator comments are processed and text images representing the spectator comments are displayed within the scenes of the gameplay which can be seen by the players competing in the game and other spectators viewing the game. Generally, the methods described herein provides a way for spectator comments to be visually depicted in the game scenes which in turn can enhance viewer engagement and can further improve communication amongst all the individuals viewing and participating in the gameplay.
As used herein, the term “walla” should be broadly understood to refer to the in-game visualization of sound or speech (e.g., talking, signing, laughing, crying, screaming, shouting, yelling, etc.) produced by spectators of a game. In one embodiment, the spectators may be a person or a combination of people which may be visually depicted (e.g., as characters or avatars) in the scenes of a video game or any other media content. For purposes of clarity, references to “walla” should be taken in the general broad sense where spectator feedback and/or reaction to a game is visualized in-game, or in accordance with other specific examples described herein.
By way of example, in one embodiment, a method is disclosed that enables displaying voice input of a spectator in a video game. The method includes receiving, by a server, the voice input produced by one or more spectators while viewing video game video of the video game. In one embodiment, the method may further include examining, by the server, the voice input to identify speech characteristics associated with the voice input of the one or more spectators. In another embodiment, the method may include processing, by the server, the voice input to generate a spectator video that includes text images representing the voice input of the spectators. In one example, the text images can be configured to be adjusted in visual appearance based on the speech characteristics of the voice input. In another example, the text images are directed in a field of view of an avatar of the spectator. In some embodiments, the method includes combining, by the server, video game video with the spectator video to produce an overlay of the text images graphically moving in toward a game scene provided by the video game video. In another embodiment, the method includes sending, to a client device, a spectator video stream that includes the overlay of the text images. It will be obvious, however, to one skilled in the art that the present disclosure may be practiced without some or all of the specific details presently described. In other instances, well known process operations have not been described in detail in order not to unnecessarily obscure the present disclosure.
In accordance with one embodiment, a system is disclosed for displaying voice input of a spectator in a video game such as an online multiplayer video game. For example, a plurality of spectators may be connected to view a live gaming event such as an E-sports event. In one embodiment, the system includes a connection to a network. In some embodiments, a plurality of spectators can be connected over a network to view the players competing against one another in the live gaming event. In some embodiments, one or more data centers and game servers can execute the game and enable connections to a plurality of spectators and players when hosting the video game. The one or more game servers of the one or more data centers may be configured to receive, process, and execute data from a plurality of devices controlled by spectators and players.
In some embodiments, while viewing the live gaming event, the system can be configured to receive, process, and execute walla (e.g., voice input) produced by the spectators. For example, while watching a live E-sports event that includes a soccer game, a spectator may produce walla and verbally cheer for their favorite players and team by verbally expressing phrases such as “you can do it, don't give, up, goal!, defense, etc.” Each walla produced by the spectator can be examined and processed by the system to generate text images representing the walla which can be visually depicted in the gaming event. In some embodiments, the corresponding text images representing the walla of the spectator can be incorporated into the scenes of the video game which can be seen by various individuals viewing the game, e.g., players, spectators, etc. In one embodiment, the text images representing the walla may be directed in a field of view of the spectator's avatar in the video game. In other embodiments, the visual appearance of the walla may vary and is based on the speech characteristics associated with the walla.
With the above overview in mind, the following provides several example figures to facilitate understanding of the example embodiments.
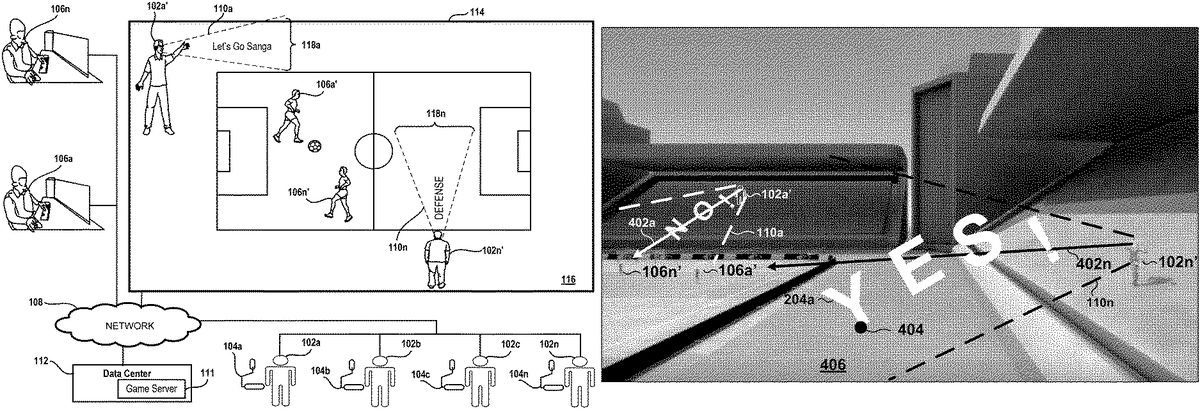
FIG. 1illustrates an embodiment of a system configured to execute a gameplay for a plurality of players106and to process walla produced by a plurality of spectators102in order to display text images representing the walla in the scene of the gameplay. As noted above, walla refers to sound or speech produced by a person or a combination of people, e.g., talking, singing, laughing, crying, screaming, shouting, yelling, grunting, etc. In one embodiment,FIG. 1illustrates spectators102a-102n, players106a-106n, a game server111, a data center112, and a network108. The system ofFIG. 1may be referred to as a cloud gaming system, where multiple game servers111and data centers112can work together to provide wide access to spectators102and players106in a distributed and seamless fashion.
In some embodiments, the players106can be playing a multiplayer online game where they are teammates or on opposing teams competing against one another. Players106can be configured to send game commands to the game server111and data center112through the network108. In one embodiment, the players106can be configured to receive encoded video streams and decode the video streams received by game server111and data center112. In some embodiments, the video streams may be presented to players106on a display and/or a separate device such as a monitor or television. In some embodiments, the devices of the players can be any connected device having a screen and internet connection.
In some embodiments, the spectators102can be coupled to and can communicate with the data center112and the game server111through the network108. The spectators102are configured to receive encoded video streams and decode the video streams received from the data center112and game server111. The encoded video streams, for example, are provided by the cloud gaming system, while player and spectator devices provide inputs for interacting with the game. In one embodiment, the spectators102can receive video streams such as a video stream from a multiplayer online game that is being executed by players106. In some embodiments, the video streams may be presented to the spectators102on a display of the spectator or on a separate device such as a monitor, or television or head mounted display, or portable device.
In some embodiments, a device such as microphone104can be used to capture the walla produced by the spectators102or sound from the environment where the spectators102are located. The walla captured by the microphones104can be examined to identify various speech characteristics associated with the walla. In some embodiments, the walla produced by each of the spectators102can be processed to generate text images representing the walla which can be displayed in the scenes of the gameplay and are viewable by the spectators and other individuals viewing the gameplay.
In one example, according to the embodiment shown inFIG. 1, the spectators102are shown connected and viewing the gameplay of players106on a display114. As shown on the display114, the gameplay of the players106illustrates a scene116of the players106playing a soccer game. As shown in the scene116, player characters106a′-106n′ representing players106a-106nare shown on the soccer field competing against each other in the game. During the progression of the gameplay, the players106a-106ncan control the various actions and movements of their corresponding player characters106a′-106n′ and the spectators102can view and react to what is occurring throughout the game.
As further illustrated in the scene116, spectator avatars102a′-102n′ represent the spectators102a-102nare shown along the terrace section of the soccer field watching the gameplay and cheering for their team. As noted above, when a spectator102speaks and produces walla, the walla produced by the spectator102is captured by the system and processed to generate text images representing the walla and the text images are displayed in a field of view of the spectator avatar associated with the spectator. For example, as shown inFIG. 1, while viewing the gameplay of the players, spectator102aand spectator102nmay respectively verbally express the words “Let's GO Sanga” and “Defense” which are captured by microphones104aand104n. The walla (e.g., Let's Go Sanga, Defense) produced by the spectators102are processed and text images representing the walla are generated and displayed in the scene116of the gameplay. In particular, as shown in the scene116, spectator avatar102a′ is shown verbally expressing the walla of spectator102a(e.g., Let's Go Sanga) and text image118arepresenting the walla is shown in the field of view110aof the spectator avatar102a′. As further illustrated in the scene116, spectator avatar102n′ is shown verbally expressing the walla of spectator102n(e.g., Defense) and text image118nrepresenting the walla is shown in the field of view110nof the spectator avatar102n′.
FIG. 2Aillustrates an embodiment of a scene of a video game with a camera point of view (POV) that captures a unique view into the scene of the video game. As illustrated inFIG. 2A, the scene shows a gameplay involving a soccer match. As shown, a camera with a camera POV may be in a position that is pointed toward one end of the soccer stadium that is configured to capture a portion of a terrace201and a portion of the soccer field203. A spectator avatar102n′ is shown in the terrace201watching the player characters106a′-106n′ compete in the soccer match. In some embodiments, the camera POV may be dynamically adjusted throughout the progression of the gameplay to provide each of the spectators102a-102nwith the most optimal view into the scene of the video game. For example, in one embodiment, the position of the camera may be adjusted so that the camera POV includes various viewpoints of the soccer stadium such as a bird's-eye view, a side-view, an upper-tier view, a lower-tier view, an end-view, or a zoomed-in view that captures a specific part of the gameplay.
FIG. 2Billustrates an embodiment of the scene shown inFIG. 2Aillustrating a spectator avatar102n′ verbally expressing the walla produced by spectator102nand the corresponding text image118nrepresenting the walla. As illustrated inFIG. 2B, a spectator avatar102n′ corresponding to spectator102nis shown standing in the terrace201watching the player characters106a′-106n′ compete in a soccer match. In some embodiments, when the spectator102nwatches the gameplay and produces walla in response to the gameplay, the walla is processed and text images representing the walla is displayed in the field of view110nof the spectator avatar102n′. Since the spectator avatar102n′ represents the spectator102nin the video game, when the spectator102nspeaks and produces walla, the spectator avatar102n′ also verbally expresses the same walla expressed by the spectator102n. In the example shown inFIG. 2B, the spectator avatar102n′ is shown yelling, “RUN!,” which corresponds to the walla produced by the spectator102n. The text images are shown floating toward the game scene from a location associated with the spectator avatar102n′ viewing the game scene. As further illustrated, text images118nrepresenting the walla is displayed in a field of view110nof the spectator avatar102n′ to depict the spectator avatar cheering for their team.
In one embodiment, the text images118can be made up of one or more glyphs204. As used herein, the term “glyph” should be broadly understood to refer to a letter, character, symbol, mark, etc., or any combination thereof that is used to collectively represent a text image118. In some embodiments, each glyph204may be configured to have specific shapes (e.g., 2-dimensional, 3-dimensional), sizes, fonts, colors, thicknesses or any other physical feature that can contribute to the overall appearance of the text image118. Text images118and glyphs204are discussed in greater detail below with reference toFIG. 6.
As further illustrated inFIG. 2B, player characters106a′ and106n′ are shown on the soccer field203which can be controlled by players106aand106nduring the gameplay. In some embodiments, player characters106a′ and106n′ may each have a corresponding field of view (FOV)202which allows the players to see the text images and objects within its FOV. In one embodiment, as the players106control the various movements and actions of their corresponding player characters106′ in the video game, the viewpoint that is observed by the player106is the same as the FOV of the player character106′ in the game. For example, as illustrated inFIG. 2B, player character106n′ is shown facing in a direction toward player character106a′ and the terrace201. Since the FOV202nof player character106n′ includes the player character106a′ and the text image118n, player102ncan also view the player character106a′ and the text image118n. In some cases, the viewpoint observed by the players106or the spectators102are not the same viewpoint that is provided by the FOV of the player characters106′ and the spectator avatars102′. In some embodiments, different camera views may be provided as options to switch to, instead of just the FOV of the player characters106′ and the spectator avatars102′.
FIG. 2Cillustrates an embodiment of the scene shown inFIG. 2Aillustrating a plurality of spectator avatars102a′-102n′ verbally expressing the walla produced by spectators102a-102nand the corresponding text images118a-118nrepresenting the walla. In some embodiments, a plurality of spectators102a-102nmay be viewing the gameplay of a video game and producing walla in response to the activity occurring in the gameplay. As noted above, the walla associated with each spectator is processed and text images representing the walla is visually depicted in the scene of the gameplay within a FOV of the corresponding avatar of the spectator. As illustrated inFIG. 2C, a plurality of spectator avatars102′ are shown standing in the terrace201watching the soccer game. Each spectator avatar102′ includes corresponding text images118that are directed in their field of view110which represents the walla produced by the corresponding spectators102. For example, spectator avatar102a′ is shown verbally expressing the word, “Sanga,” which is represented by text image118a. Spectator avatar102b′ is shown verbally expressing the word, “YES,” which is represented by text image118b. Spectator avatar102c′ is shown verbally expressing the words, “You can do it,” which is represented by text image118c. Spectator avatar102n′ is shown verbally expressing the word, “RUN!,” which is represented by text image118n.
As further illustrated inFIG. 2C, spectator avatars102d′-102g′ are shown watching the gameplay from an end-zone terrace206. As shown, the spectator avatars102d′-102g′ may have a corresponding FOV110d-110gwhich includes text images118within its FOV representing the walla produced by their corresponding spectators102. For example, spectator avatar102d′ is illustrated verbally expressing the word, “NO!,” which is represented by text image118d. Spectator avatar102e′ is illustrated verbally expressing the word, “Yes!,” which is represented by text image118e. Spectator avatar102f′ is illustrated verbally expressing the word, “WIN!,” which is represented by text image118f. Spectator avatar102g′ is illustrated verbally expressing the word, “Defense,” which is represented by text image118g.
FIG. 3Aillustrates an embodiment of a scene of a video game with a camera point of view (POV) that captures a side-view of the gameplay which includes a portion of the terrace201and a portion of the soccer field203. The scene shown inFIG. 3Aprovides an example illustrating that the camera POV can be dynamically adjusted to any position so that it provides each spectator with a unique viewpoint into the gameplay. As illustrated inFIG. 3A, the figure illustrates a viewpoint that is perceived by the spectator102nwhich includes the spectator avatar102′ and the player characters106a′-106n′. The figure illustrates the spectator avatar102n′ in the terrace201watching the player characters106a′-106n′ compete in the soccer match. In this example, the spectator102nis not producing any walla. Accordingly, the spectator avatar102n′ is shown silently viewing the gameplay. In this embodiment, it is noted that the viewpoint of the spectator102and the POV of the spectator avatar102′ are different. Accordingly, the viewpoint of the spectator102may be different than the POV of the spectator avatar102n′, or in other cases can be aligned with one another.
FIG. 3Billustrates an embodiment of the scene shown inFIG. 3Aillustrating a plurality of spectator avatars102a′-102n′ verbally expressing the walla produced by the spectators and the corresponding text images118a-118nrepresenting the walla. As shown, each spectator avatar102a′-102n′ may have a corresponding FOV110a-110nwhich includes text images representing the walla produced by its corresponding spectator102. For example, spectator avatar102a′ is shown verbally expressing the word, “Sanga,” which is represented by text image118a. Spectator avatar102b′ is shown verbally expressing the words, “Go Team,” which is represented by text image118b. Spectator avatar102c′ is shown verbally expressing the word, “Defense,” which is represented by text image118c. Spectator avatar102n′ is shown verbally expressing the word, “RUN!,” which is represented by text image118n.
FIG. 4illustrates an embodiment of a scene of a video game illustrating text images118directed along a gaze direction402of the spectator avatars. In some embodiments, while viewing a gameplay of a video game, a camera that includes gaze tracking may be configured to capture images of the eyes of the spectator102to determine the gaze direction of the spectator102and the specific game content that the spectator102is focused on. In some embodiments, the gaze direction and the movements of the spectator102can be translated to the corresponding spectator avatar102′ of the spectator102. Since the spectator avatar102′ represents the spectator102in the video game, the spectator avatar102′ mimics the same actions as the spectator, e.g., walla, gaze direction, movements, etc. For example, during the gameplay, the spectator102may have their gaze direction focused on their favorite players throughout the progression of the gameplay. Accordingly, as the spectator102makes various movements and focuses their attention on specific players in the game, the spectator avatar102′ associated with spectator102may also make the same movements and focus on the same players. In one example, as illustrated inFIG. 4, since the spectator102nis looking toward the player character106a′, the spectator avatar102n′ is also looking toward the player character106a′ which is illustrated by the gaze direction402n.
In some embodiments when a spectator102speaks and produces walla, the text images118representing the walla in the scene of the gameplay are directed along the gaze direction402of the corresponding spectator avatar102′. For example, as shown inFIG. 4, when the spectator102nverbally express the word, “YES!,” the text image118nrepresenting the walla is shown within the FOV110nof the spectator avatar102n′ and is directed along the gaze direction402n. As further illustrated inFIG. 4, spectator avatar102a′ has a gaze direction402athat is directed toward the player character106n′. Accordingly, when the spectator102averbally express the word, “NO!,” the text image118arepresenting the walla is shown within the FOV110aof the spectator avatar102a′ and is directed along the gaze direction402a.
In some embodiments, the text images118representing the walla and each glyph204of the text images118may be assigned a physics parameter such as a weighting parameter. For example, each glyph204may be assigned to have a specified weighting parameter such as a mass and be subjected to the force of gravity. Referring toFIG. 4, the text image118n(e.g., YES!) is shown projecting from the spectator avatar102n′. The text image118nis projected toward the soccer field at a specified distance and floats for a period of time before falling under the influence of gravity. As shown inFIG. 4, glyph204aof the text image118ncontacts the surface406at collision point404. In some embodiments, if a glyph204collides with an object in the game, the glyph may affect the gameplay. For example, when the glyph204acollides with the surface406at collision point404, the glyph204aand the surface406may be damaged because of the collision. In another example, if the glyph204acollides with a soccer ball in the gameplay, the soccer ball may be deflected a certain distance from the point of impact with the glyph204a. In other embodiments, if weighting parameters are not be assigned to the glyphs204and the text images118, the glyphs204and the text images118will not affect the gameplay when it collides with objects in the gameplay.
FIGS. 5A-5Fillustrate a plurality of video game scenes at various points in time and the text images representing the walla of the spectator102. As illustrated inFIGS. 5A-5F, the spectator avatar102′ is shown verbally expressing the words, “YES SANGA,” which is represented by text images directed in the field of view of the spectator avatar102′. As illustrated in the figures, the text images are represented by glyphs204a-204hwhich appear in the game scenes at various points in time. For example, as illustrated inFIG. 5A, at time t1, glyph204a(e.g., Y) is shown in the FOV of the spectator avatar102′. As illustrated inFIG. 5B, at time t2, glyphs204a-204b(e.g., YE) are shown in the FOV of the spectator avatar102′. As illustrated inFIG. 5C, at time t3, glyphs204a-204c(e.g., YES) are shown in the FOV of the spectator avatar102′. As illustrated inFIG. 5D, at time t4, glyphs204a-204c(e.g., YES) are shown in the FOV of the spectator avatar102′ and are at a position more proximate to the soccer field. As illustrated inFIG. 5E, at time t5, glyphs204c-204h(e.g., S SANGA) are shown in the FOV of the spectator avatar102′. As illustrated inFIG. 5F, at time tn, glyphs204f-204h(e.g., NGA) are shown in the FOV of the spectator avatar102′. In some embodiments, each of the glyphs204a-204hmay be configured to have a specific shape, size, font, color, thickness, etc. In some embodiments, each glyph204may have a weighting parameter or material properties associated with the glyph. For example, if the glyphs are assigned a weighting value and are made out of polymer, when the glyphs204a-204hcollide with the surface of the field, the glyphs204f-204hmay react in a manner that is consistent with the laws of physics, e.g., bounce, roll, slide, or interact with other game assets or objects in a scene, etc.
FIG. 6illustrates a text image representing the walla produced by a spectator which is represented by glyphs204a-204cindependently floating toward a game scene. As noted above, when a spectator102speaks and produces walla, a text image representing the walla is directed in the FOV of the spectator avatar102′. In the illustrated example,FIG. 6illustrates the spectator avatar102′ verbally expressing the word, “Yes,” which is represented by the text image118. The text image118is represented by glyphs204a-204cwhich can independently appear in the game scene and float toward the game scene at various points in time. For example, at time t1, the glyph204aappears in the game scene and is represented by the letter “Y” and is in a 3-dimensional shape. At time t2, the glyph204bappears in the game scene and is represented by the letter “E” and is in a 3-dimensional shape. At time t3, the glyph204cappears in the game scene and is represented by the letter “S” and is in a 3-dimensional shape. As time progresses, the glyphs204a-204ccan independently float a specified distance before fading away or colliding with the ground under the influence of gravity. At time t4, the glyphs204a-204cbegin to fall in a direction toward the ground and impacts the floor at time tn.
In some embodiments, as the glyphs204independently floating toward a game scene, each glyph can independently rotate, spin, glide at a certain speed, or make any movements independently. In some embodiments, the glyphs204can be animated to represent the mood or emotion of the spectator102producing the walla. For example, if the spectator is feeling cold and anxious about the video game that they are viewing, the glyphs204may be animated to look like icicles to represent the spectator feeling cold. In some embodiments, as noted above, the glyphs204may be assigned material properties to represent the emotion of the spectator. Accordingly, when the glyphs204interact with objects in the gameplay, the glyphs204may react in a manner that is consistent with their material properties. For example, if a spectator is feeling irritable and weak, a glyph may be associated with a glass material to represent the emotion of the spectator. Accordingly, when the glyph collides with other objects in the game or impacts the floor, the glyph may shatter.
FIG. 7illustrates an embodiment of a server receiving walla data from a plurality of spectators102and processing the walla data to provide the spectators102and the players106with video streams that include text images representing the walla produced by the spectators102. As shown inFIG. 7, the system includes a server701that is configured to receive walla (e.g., voice input) from a plurality of spectators102a-102n. In one embodiment, the spectators102a-102nmay be viewing the gameplay of players106a-106nplaying a multiplayer online game. While viewing the gameplay, the spectators102a-102nmay support their team by verbally cheering and reacting to the actions occurring in the gameplay. In some embodiments, each spectator102may have a microphone104that is configured to capture the walla (e.g., voice input) of the spectators while the spectators view and verbally comment on the gameplay. In one embodiment, as each spectator is viewing the gameplay and producing walla, the walla can be received by server701which is configured to examine and process the walla of the spectators102.
In one embodiment, the system includes a voice input processor702which can include a speech-to-text analyzer704and a sentiment analyzer706. After processing the voice input of the spectators, the system may include a walla processor708that is configured to receive the voice input with its corresponding speech characteristics as inputs. After the walla processor708processes the voice input and the corresponding speech characteristics, a game server710may be configured to receive the output from the walla processor708and be configured to execute the gameplay which may include walla video and walla audio. Using the output of the game server710, the system may provide each of the spectators102a-102nand the players106a-106nwith a unique viewpoint of the gameplay which may include the walla video and the walla audio.
In one embodiment, while the spectators are viewing the gameplay of the players106, the voice input processor702can be configured to receive the voice input data (e.g., walla) from the spectators102a-102n. For example, the spectators102a-102nmay be watching the players106a-106ncompete in a live gaming event such as an E-sports event. While viewing the event, the spectators102a-102nmay support their favorite players and team by verbally expressing words of encouragement (e.g., Yes!, You can do it, Whoa nice move, etc.). The voice input of the spectators102can be captured by microphones104and sent to the voice input processor702to be examined.
In some embodiments, the voice input processor702may include a speech-to-text analyzer704and a sentiment analyzer706. In one embodiment, the speech-to-text analyzer704is configured to convert the voice input of the spectator to text. In some embodiments, the conversion of speech to text is optional, and the voice input can be processed without conversion. In some embodiments, the sentiment analyzer706can be configured to examine the voice input of the spectator102using a machine learning model to identify various speech characteristics associated with the voice input. For example, the sentiment analyzer706can determine a sound intensity level, an emotion, and a mood associated with the voice input. In one embodiment, the sentiment analyzer706can be configured to identify, measure, or assign a sound intensity level for the voice input. In some embodiments, the sound intensity level associated with the voice input of the spectator can be based on the context of scene of the gameplay and the meaning of the words expressed by the spectator. In other embodiments, the machine learning model can be used to distinguish between the voice inputs of the various spectators.
In other embodiments, the sentiment analyzer706can be used to determine the emotion or mood associated with the voice input of the spectator. These emotions can include, without limitation, excitement, fear, sadness, happiness, anger, etc. For example, a spectator102may be watching a video game scene that involves their favorite player fighting against a “boss character” in order to advance onto the next level of the game. When the “boss character” is on the verge of winning, the spectator102yells out loud in support of the player, “Please don't give up.” The sentiment analyzer706can process the voice input of the spectator and determine that the sound intensity level associated with the voice input has a value of ‘8’ and that the spectator is emotionally nervous and anxious while viewing the fight scene.
In another embodiment, the walla processor708is configured to receive the output data from the voice input processor702as an input. In one embodiment, the walla processor708can be configured to use the noted inputs to determine the visual appearance of the text images118in the scene of the video game. For example, since the voice input of the spectator is converted to text, the walla processor708can use the letters from the text as a baseline to determine the appearance of the text images. In some embodiments, the voice input data may include various speech characteristics associated with the voice input of the spectator such as sound intensity levels and emotions. Accordingly, the walla processor708can organize the speech characteristics associated with the voice input for each spectator for further processing by game server710.
In some embodiments, the game server710is configured to receive the output data from the walla processor708. The output data from the walla processor708may include data that is used to determine the visual appearance of the text images118and other parameters associated with the dynamics of the text images118and how it may interact in the gameplay, e.g., distance projected, fade-away time, speed, etc. In one embodiment, the game server710may be configured to execute the active gameplay of the one or more players106. In some embodiments, the game server710may include a walla engine712and a game engine714that are configured to work together to generate video streams (e.g., spectator video and a player video) that includes the text images118. In one embodiment, the game server710is configured to provide the spectators and the players with access to the video streams in a distributed and seamless fashion. In one embodiment, the spectator video and the player video can be unique for each spectator and player. In particular, the spectator video and the player video may include a unique camera POV that is dynamically adjusted based on the preferences of each spectator and player.
In some embodiments, the walla engine712may use the known speech characteristics of the voice input to determine or assign additional speech characteristics to the corresponding voice input. In one example, these speech characteristics can include, without limitation, weight, size, thickness, distance projected, fade-away time, etc. In one example, when a spectator102yells out loud in support if a player, “Please don't give up,” the sound intensity level of the voice input has a value of ‘8’ and the spectator is emotionally nervous and anxious. Based on the sound intensity level and the emotional state of the spectator, the walla engine712may determine that the voice input (e.g., Please don't give up) may have a weighting value of ‘5,’ a size value of ‘6,’ a thickness value of ‘7,’ and be projected a distance of 90 feet before fading away in 9 seconds.
In some embodiments, the game engine714can be configured to perform an array of functionalities and operations. In one embodiment, the game engine714can be configured to generate a spectator video and player video that includes the text images118. In some embodiments, the game engine714may adjust the appearance of the text images based on the speech characteristics of the voice input. In other embodiments, using the speech characteristics of the voice input, the game engine714may be configured to perform game calculations and implement physics to determine how the text images118interacts and affects the gameplay, e.g., the directionality, distance projected, fade-time, etc.
In some embodiments, a walla noise processor718is configured to receive walla audio from the game server710for processing to determine an audio playback724to include in the game scenes of the spectator video stream. In one embodiment, the walla noise processor718may be configured to combine the existing walla noise720in the game scenes with the walla audio to generate the audio playback724. In one embodiment, the walla noise720may be the noise from the gameplay and depend on what is occurring in the game scenes, e.g., background noise, crowd noise, noise from other characters in the game, etc. In some embodiments, the walla noise processor718may include a modulator722that is used to modulate the walla noise720and the walla audio to adjust the audio for a particular spectator102. For example, a spectator that is viewing the gameplay of a soccer match that is seated on an upper terrace portion of the soccer stadium may have an audio playback724that is different than a spectator that is seated close to the soccer field. Accordingly, the modulator722can be configured to modulate the walla noise720and the walla audio to generate the generate the audio playback724so that it sounds realistic to the spectator and reflects the position and location of the spectator in the game scene.
In some embodiments, spectator game scenes716a-716nmay be presented to the spectators102a-102non a display of the spectator or on a separate device such as a monitor, or television or head mounted display, or portable device. In some embodiments, the spectator game scenes716a-716nmay include the audio playback generated by the walla noise processor718and the walla video from the game server710. In some embodiments, the spectator game scenes716a-716nmay be unique for each spectator102. For example, each spectator102may have a view of the gameplay based on the FOV of their corresponding avatar. In other embodiments, each spectator102may have a view that is based on the preferences of spectator or camera point of view that is dynamically adjusted to provide the spectator with the most optimal view of the gameplay and the text images appearing in the gameplay.
In some embodiments, walla noise processor728is configured to receive walla audio (e.g., voice input of spectators) from the game server710for processing to determine an audio playback734to include in the game scenes of the player video stream. In one embodiment, the walla noise processor728may be configured to combine the existing walla noise728in the game scenes with the walla audio to generate the audio playback734. In some embodiments, the walla noise processor728may include a modulator722that is used to modulate the walla noise728and the walla audio to adjust the audio for a particular player106. In some embodiments, the player game scenes726may be presented to the players106a-106non a display of the players106on a separate device such as a monitor, or television, or head mounted display, or portable device. In some embodiments, the player game scenes726may include the audio playback generated by the walla noise processor728and the walla video generated by the game server710. In some embodiments, the player game scenes726may be unique for each player106which provides each player with a unique view of the gameplay.
FIG. 8illustrates an embodiment of a streaming game server801receiving spectator walla data (e.g. spectator voice input) captured from a plurality of spectators102a-102nand processing the walla data to provide the spectators102and players106with video streams that include text images representing the walla. In some embodiments, the streaming game server801is configured to examine and process the spectator walla data to provide the spectators102a-102nand the players106a-106nwith video streams that includes text images118representing the walla of the spectators. In one embodiment, the spectators102may be viewing and verbally reacting to the gameplay of players106playing a multiplayer online game. In some embodiments, as the spectators102produce walla in response to the gameplay, the walla can be received by server801in real-time which is examined and processed by various processors and operations of the system.
In some embodiments, the system may include a spectator input processor802that is configured to receive the voice input of the spectators102and examine the voice input. After examining the voice input of the spectators, the system may include a walla engine712that is configured to process the voice input of the spectators to generate a walla video stream (e.g., WS-1, WS-2, WS-n) for each of the spectators102. After the walla engine712generates the walla video streams, a walla combiner logic808is configured to combine the walla video streams and determine the respective camera point of views for each spectator102. Using the output of the walla combiner logic808, a game engine714can be configured to execute the gameplay and generate spectator and player video streams which can be provided to the spectators102and the players106in real-time.
In some embodiments, the spectator input processor802may include a speech processor803, a sentiment analyzer706, a walla processor708, and an operation804that is configured to determine the camera POV and FOV of the spectator102. In one embodiment, the speech processor803can be configured to analyze the voice input of each spectator and convert the voice input to text. Accordingly, the converted text can be used as a baseline to determine the visual appearance of the text images that represent the voice input. As noted above, in some embodiments, the sentiment analyzer706can be configured to examine the voice input of the spectator using a machine learning model to identify speech characteristics associated with the voice input, e.g., sound intensity level, weighting, emotion and mood associated with the voice input, etc.
In some embodiments, operation804can be configured to determine the camera POV and of the spectator102. In one embodiment, the camera POV may be dynamically adjusted throughout the progression of the gameplay to provide each of the spectators102with the most optimal view into the video game. In some embodiments, the camera POV may be based on the preferences of the spectator102or be adjusted to focus on certain aspects of the gameplay. For example, a spectator may have a preference to have a camera POV from a bird's-eye-view so that the spectator can see the gameplay of all the players competing in the video game. In other embodiments, operation804can be configured to determine the FOV of the spectator102and the spectator avatar102′. While watching the gameplay, the spectator102may focus their attention specific aspects of the gameplay which is continuously monitored by operation804. As a result, the gaze direction and the FOV of the spectator avatar102′ is continuously tracked and monitored throughout the progression of the gameplay by operation804.
In some embodiments, the walla processor708can receive as inputs the results from the speech processor803, operation804, and the sentiment analyzer706to determine the visual appearance of text images118representing the walla produced by the spectators102. In some embodiments, the walla processor708may organize the speech characteristics associated with the voice input for each spectator and distribute the data to the walla engine712.
In some embodiments, the walla engine712may include walla video stream generators806a-806nthat are configured to receive data from the walla processor708and generate spectator video streams (e.g., WS-1, WS-2, WS-n) for the spectators102. In one embodiment, each spectator video stream may include text images118representing the voice input produced by the respective spectator102. In some embodiments, each walla video stream generator806may include one or more operations that may work together generate the spectator video streams. In one embodiment, each walla video stream generator806may include an intensity operation814, an emotion processor816, a physics operation818, a directionality operation820, an audio mixing operation822, and an overlay video operation824.
In some embodiments, the intensity operation814is configured to process the sound intensity level associated with the voice input of the spectator which can be used to determine the visual appearance of the text images118. In one embodiment, based on the sound intensity level of the voice input, the intensity operation814can determine the specific shape, size, font, color, thickness, or any other physical feature that can contribute to the overall visual appearance of the text image. In some embodiments, based on the sound intensity level of the voice input, the intensity operation814can determine various ways to animate the text images, e.g., flames, lightning bolts, icicles, etc. In other embodiments, the intensity operation814may be configured to adjust the sound intensity level based on context of the gameplay. For example, during a penalty shoot-out in FIFA World Cup finals game, a spectator yells, “I believe in you Japan.” In this example, the intensity operation814may take into consideration the context of the gameplay (e.g., penalty shoot-out, finals game) and increase the sound intensity level since it is a climactic point in the gameplay.
In some embodiments, the emotion processor816is configured to process the emotion associated with the voice input of the spectator to determine the visual appearance of the text images118. In one embodiment, using the emotion associated with the voice input, the emotion processor816can determine the colors of the text images118. For example, if the voice input of the spectator is associated with an emotion of happiness, the emotion processor816may determine that the corresponding text image is the color green. In another example, if the voice input of the spectator is associated with an angry emotion, the emotion processor816may determine that the corresponding text image is the color red.
In some embodiments, the physics operation818may implement physics to determine how the text images118interacts and affects the gameplay. In one embodiment, the physics operation818may use the weighting associated with the voice input of the spectator to determine how the text images118interacts with the gameplay, e.g., distance projected, fade-time, speed, bounce, twist, deform, slide, etc. Since the text images can be associated with a physics parameter, this enables the text images to graphically impact an object in the game scene. For example, a first text image associated with a first spectator may have a larger weighting than a second text image associated with a second spectator. When the first text image and the second text image collide against one another, the first text image may cause the second image to deflect a specified distance away from the point of collision because the weighting of the first text image is larger than the weighting of second text image. In another example, based on the sound intensity level and emotion of the voice input, the physics operation818can determine the speed and adjustments in speed of the corresponding text images118when it graphically moves in toward a game scene. In general, a voice input having a sound intensity level that is greater than other voice inputs may have corresponding text images that move at greater speeds.
In some embodiments, the directionality operation820may determine the path and direction the text image118floats within the scene of the gameplay. In one embodiment, the directionality operation820may determine that the text image118travels toward a direction that the spectator avatar is facing. In one example, the text image118may float along the path of the gaze direction of the spectator avatar and would stay within range of the POV of the spectator avatar.
In some embodiments, the audio mixing operation822can incorporate the voice input produced by the spectator with the existing audio from the gameplay to produce an audio playback which can be included in the spectator video stream (e.g., WS-1, WS-2, WS-n). In some embodiments, the audio mixing operation822can adjust the audio playback so that it corresponds to where the spectator avatar is positioned in the scene of the gameplay. For example, a spectator avatar that is seated in a section of a soccer stadium that has a higher concentration of spectators may have an audio playback that is different than a spectator avatar that is seated in a luxurious section of the stadium where the spectators are more spread out and less concentrated.
In some embodiments, the overlay video operation824may be configured to combine the results of the noted operations (e.g.,814,816,818,820,822) to produce a spectator video that includes text images representing the voice input of the spectator. In one embodiment, the overlay video operation824can combine a video game video with the spectator video produce an overlay of the text images graphically moving in toward a game scene provided by the video game video.
In some embodiments, a walla combiner logic808can receive the one or more spectator video streams (e.g., WS-1, WS-2, WS-n) as inputs. Since multiple spectator video streams are generated and each spectator video stream corresponds to a particular spectator, the walla combiner logic808is configured to combine all of the spectator video steams so that all of text images can be combined into a single spectator video stream. This will allow the spectators to have a combined view of all of the text images that represent the voice input of all of the spectators. In some embodiments, using a camera POV associated with a spectator, the walla combiner logic808can provide a spectator with a view of the gameplay based on the camera POV. In some embodiments, the walla combiner logic808can be configured to provide the spectators with a unique view into the gameplay that is based on their personal preferences.
In some embodiments, the game engine714can receive the combined spectator video stream from the walla combiner logic808as an input. As noted above, the game engine714can be configured to perform an array of functionalities and operations. In one embodiment, the game engine714can be configured to make any additional adjustments to the appearance of the text images to produce spectator game scenes (e.g.,810) that can be viewed by the spectators102. In another embodiment, using the spectator video stream, the game engine714can generate players game scenes (e.g.,812) that can be viewed by the players playing the video game.
FIG. 9Aillustrates an embodiment of a speech intensity table902illustrating various walla (e.g. voice input) produced by a plurality of spectators while viewing the gameplay of the players106. As shown, the speech intensity table902includes a spectator identification904and the walla906produced by the spectators at a specific point in time, e.g., t1-tn. In some embodiments, after the system examines the respective walla of a spectator, each walla906may include various speech characteristics905such as a sound intensity level908, a weighting910, a size912, a thickness914, a distance projected916, and a fade-time918.
As illustrated inFIG. 9A, each walla906may have a corresponding sound intensity level908that can range from 0-10. In general, the sound intensity level is associated with the loudness of the sound that can be perceived by a person. In other embodiments, the sound intensity level908may be based on the mood or emotion of the spectator102and the context of the gameplay. In some embodiments, the sound intensity level908can cause changes in size of the text images118. In one embodiment, walla with a sound intensity level of ‘10’ may affect the visual appearance of the corresponding text image such that the text images corresponding to the walla significantly stands out in the scene of the video game. For example, a walla with a sound intensity level of ‘10’ may result in the corresponding text image having bright colors, and larger in size relative to the other text images. Conversely, a walla with a sound intensity level of ‘1’ may have a corresponding text image that is unnoticeable in the scene of the game scene, e.g., transparent, small size, faint, etc.
In some embodiments, the sound intensity level908may be used to determine the weighting910associated with the walla and its corresponding text image. In some embodiments, the weighting910can range from 0-10. Generally, the greater the weighting that is associated with the walla, the greater the impact and affect the corresponding text image of the walla may have on the gameplay. For example, if a text image with a weighting value of ‘10’ collides with an object in game scene that has a weighting value of ‘3,’ the object may be deflected a certain distance away from the text image or may be damaged by the text image. Conversely, a text image having a weight value of ‘1’ may have an insignificant effect on the game scene and may not deflect or damage objects in the game scene when colliding with objects in the game.
In some embodiments, the size912associated with the walla and its corresponding text image may be based on the sound intensity level908of the walla. In one embodiment, the size912of the text image can range from 0-10. Generally, the greater the size that is associated with the walla and its corresponding text image, the larger the stature the text image may appear in the game scene. In some embodiments, the sound intensity level908associated with a walla may be used to determine the thickness914associated with the walla and its corresponding text image. In one embodiment, the thickness914can range from 0-10 and may provide depth and allow the text image to appear in 3-dimensional.
In some embodiments, the distance that a text image is projected (e.g., distance projected916) and the time it takes the text image to fade away (e.g., fade-time918) may be based on the sound intensity level908of the walla. For example, as illustrated inFIG. 9A, at time tn, spectator 3 verbally expresses “I believe in you Antlers.” The system may determine that the that spectator 3 is feeling nervous and that the sound intensity level of the walla has a value of ‘2.’ Accordingly, based on the sound intensity level and emotion associated with the walla produced by spectator 3, the system may determine that the walla has a weighting value of ‘1,’ a size value of ‘2,’ a thickness value of ‘1,’ and be projected a distance of 5 feet before fading away in 4 seconds. In other embodiments, a developer or designer of the video game may assign specific values to the speech characteristics associated with the walla, assign specific colors to the text images, or determine other features that may impact the visual appearance of the corresponding text images.
FIG. 9Billustrates an embodiment of an emotion to color mapping table920which can be used to determine the color of the text images118representing the walla. In some embodiments, the color of the text images118may be based on various factors such as the mood, emotion, and the sound intensity of the walla. As illustrated inFIG. 9B, the emotion to color mapping table920includes an emotion category922, emotion type924, and a recommended color926. For example, when a spectator verbally yells, “Horrible call,” the system may determine that the spectator is upset with a bad decision made by a referee in the soccer match. Accordingly, based on the emotion to color mapping table920, the system may determine that the color of the text image corresponding to the walla (e.g. Horrible call) is red. Hence, in some embodiments, the mood in the voice input of the spectator can be processed to set color changes in the text images118. In some embodiments, the speech intensity table902ofFIG. 9Aand the emotion to color mapping table920ofFIG. 9Bcan be used on conjunction to determine the visual appearance of the text images118.
FIG. 10illustrates a method for displaying voice input of a spectator in a video game. In one embodiment, the method includes an operation1002that is configured to receive, by a server, voice input (e.g., walla) produced by a spectator102while viewing video game video of the video game. For example, while viewing the gameplay of the players106, the spectators102may verbally react to the gameplay which may include the spectators talking, signing, laughing, crying, screaming, shouting, yelling, etc. In some embodiments, operation1002can simultaneously capture the voice input from a plurality of spectators102and be able to distinguish the voice input of each spectator. In other embodiments, in lieu of providing voice input, the spectators102can provide their comments to the gameplay by typing it via a keyboard or any other type of device which can be received and processed by operation1002.
The method shown inFIG. 10then flows to operation1004where the operation is configured to examine, by the server, the voice input to identify speech characteristics associated with the voice input of the spectator102. As noted above, the voice input may include various speech characteristics such as a sound intensity level, a weighting, a size, a thickness, a distance projected, and a fade-time. In some embodiments, operation1004can be configured to determine the emotion and mood associated with the voice input that is produced by the spectator. In one example, operation1004may be configured to determine whether the spectator is happy, excited, scared, angry, etc. when the spectator speaks and produces walla.
The method flows to operation1006where the operation is configured to process, by the server, the voice input to generate a spectator video that includes text images representing the voice input of the spectator. In some embodiments, the speech characteristics associated with the voice input of the spectator can be used to determine the visual appearance of the text images. In other embodiments, the text images representing the voice input of the spectator may include various letters, symbols, marks, emoticons, etc. that are used to collectively represent the text images.
The method shown inFIG. 10then flows to operation1008where the operation is configured to combine, by the server, video game video with the spectator video to produce an overlay of the text images graphically moving in toward a game scene provided by the video game video. For example, the video game video may include scenes of a soccer match where a goalkeeper prevented the opposing team from scoring. The spectator video may include text images representing the voice input (e.g., good job, yes, great defense, etc.) of various spectators being projected from the avatars of the spectators to depict the spectator's avatars celebrating the blocked shot by the goalkeeper. Operation1008can combine the video game video and the spectator video to produce an overlay showing the spectator avatars celebrating the blocked shot with the respective text images floating and moving in the game scene.
In another embodiment, operation1008is configured to associate, by the server, the video game video with the spectator video to enable generation of an overlay of the text images graphically moving in toward a game scene provided by the video game video. For example, associating the video game video with the spectator video can allow spectators102or the players106to reproduce the game scenes and the overlay of the text images locally at their respective client devices.
The method shown inFIG. 10then flows to operation1010where the operation is configured to send, to a client device, a spectator video stream that includes the overlay of the text images. In some embodiments, the spectator video stream can be adjusted to provide each spectator or player with a unique viewpoint of the gameplay. In one embodiment, the spectator video stream can be viewed by the spectators on a display of the spectator or on a separate device such as a monitor, or television, or head mounted display, or portable device.
In another embodiment, instead of sending to a client device a spectator video stream that includes the overlay of the text images, operation1010is configured to enable a client device of the spectator102or the player106to render the spectator video stream at their respective client devices. In one embodiment, the client device of the spectator102or the player106can receive, by the server, the association of the video game video and the spectator video so that the spectator video stream can be produced by the client device of the spectator102or the player106. For example, in a massively multiplayer online (MMO) game, each spectator102and player106can receive or access the associated video game video and the spectator video so that the spectator video stream can be rendered locally at their respective client devices. In one embodiment, the client device of the spectator102may receive the video game video and then subsequently receive the overlay of the text images to enable locally rendering of the spectator video stream at the client device.
FIG. 11illustrates components of an example device1100that can be used to perform aspects of the various embodiments of the present disclosure. This block diagram illustrates a device1100that can incorporate or can be a personal computer, video game console, personal digital assistant, a server or other digital device, suitable for practicing an embodiment of the disclosure. Device1100includes a central processing unit (CPU)1102for running software applications and optionally an operating system. CPU1102may be comprised of one or more homogeneous or heterogeneous processing cores. For example, CPU1102is one or more general-purpose microprocessors having one or more processing cores. Further embodiments can be implemented using one or more CPUs with microprocessor architectures specifically adapted for highly parallel and computationally intensive applications, such as processing operations of interpreting a query, identifying contextually relevant resources, and implementing and rendering the contextually relevant resources in a video game immediately. Device1100may be a localized to a player playing a game segment (e.g., game console), or remote from the player (e.g., back-end server processor), or one of many servers using virtualization in a game cloud system for remote streaming of gameplay to clients.
Memory1104stores applications and data for use by the CPU1102. Storage1106provides non-volatile storage and other computer readable media for applications and data and may include fixed disk drives, removable disk drives, flash memory devices, and CD-ROM, DVD-ROM, Blu-ray, HD-DVD, or other optical storage devices, as well as signal transmission and storage media. User input devices1108communicate user inputs from one or more users to device1100, examples of which may include keyboards, mice, joysticks, touch pads, touch screens, still or video recorders/cameras, tracking devices for recognizing gestures, and/or microphones. Network interface1114allows device1100to communicate with other computer systems via an electronic communications network, and may include wired or wireless communication over local area networks and wide area networks such as the internet. An audio processor1112is adapted to generate analog or digital audio output from instructions and/or data provided by the CPU1102, memory1104, and/or storage1106. The components of device1100, including CPU1102, memory1104, data storage1106, user input devices1108, network interface1110, and audio processor1112are connected via one or more data buses1122.
A graphics subsystem1120is further connected with data bus1122and the components of the device1100. The graphics subsystem1120includes a graphics processing unit (GPU)1116and graphics memory1118. Graphics memory1118includes a display memory (e.g., a frame buffer) used for storing pixel data for each pixel of an output image. Graphics memory1118can be integrated in the same device as GPU1108, connected as a separate device with GPU1116, and/or implemented within memory1104. Pixel data can be provided to graphics memory1118directly from the CPU1102. Alternatively, CPU1102provides the GPU1116with data and/or instructions defining the desired output images, from which the GPU1116generates the pixel data of one or more output images. The data and/or instructions defining the desired output images can be stored in memory1104and/or graphics memory1118. In an embodiment, the GPU1116includes 3D rendering capabilities for generating pixel data for output images from instructions and data defining the geometry, lighting, shading, texturing, motion, and/or camera parameters for a scene. The GPU1116can further include one or more programmable execution units capable of executing shader programs.
The graphics subsystem1114periodically outputs pixel data for an image from graphics memory1118to be displayed on display device1110. Display device1110can be any device capable of displaying visual information in response to a signal from the device1100, including CRT, LCD, plasma, and OLED displays. Device1100can provide the display device1110with an analog or digital signal, for example.
It should be noted, that access services, such as providing access to games of the current embodiments, delivered over a wide geographical area often use cloud computing. Cloud computing is a style of computing in which dynamically scalable and often virtualized resources are provided as a service over the Internet. Users do not need to be an expert in the technology infrastructure in the “cloud” that supports them. Cloud computing can be divided into different services, such as Infrastructure as a Service (IaaS), Platform as a Service (PaaS), and Software as a Service (SaaS). Cloud computing services often provide common applications, such as video games, online that are accessed from a web browser, while the software and data are stored on the servers in the cloud. The term cloud is used as a metaphor for the Internet, based on how the Internet is depicted in computer network diagrams and is an abstraction for the complex infrastructure it conceals.
A game server may be used to perform the operations of the durational information platform for video game players, in some embodiments. Most video games played over the Internet operate via a connection to the game server. Typically, games use a dedicated server application that collects data from players and distributes it to other players. In other embodiments, the video game may be executed by a distributed game engine. In these embodiments, the distributed game engine may be executed on a plurality of processing entities (PEs) such that each PE executes a functional segment of a given game engine that the video game runs on. Each processing entity is seen by the game engine as simply a compute node. Game engines typically perform an array of functionally diverse operations to execute a video game application along with additional services that a user experiences. For example, game engines implement game logic, perform game calculations, physics, geometry transformations, rendering, lighting, shading, audio, as well as additional in-game or game-related services. Additional services may include, for example, messaging, social utilities, audio communication, game play replay functions, help function, etc. While game engines may sometimes be executed on an operating system virtualized by a hypervisor of a particular server, in other embodiments, the game engine itself is distributed among a plurality of processing entities, each of which may reside on different server units of a data center.
According to this embodiment, the respective processing entities for performing the may be a server unit, a virtual machine, or a container, depending on the needs of each game engine segment. For example, if a game engine segment is responsible for camera transformations, that particular game engine segment may be provisioned with a virtual machine associated with a graphics processing unit (GPU) since it will be doing a large number of relatively simple mathematical operations (e.g., matrix transformations). Other game engine segments that require fewer but more complex operations may be provisioned with a processing entity associated with one or more higher power central processing units (CPUs).
By distributing the game engine, the game engine is provided with elastic computing properties that are not bound by the capabilities of a physical server unit. Instead, the game engine, when needed, is provisioned with more or fewer compute nodes to meet the demands of the video game. From the perspective of the video game and a video game player, the game engine being distributed across multiple compute nodes is indistinguishable from a non-distributed game engine executed on a single processing entity, because a game engine manager or supervisor distributes the workload and integrates the results seamlessly to provide video game output components for the end user.
Users access the remote services with client devices, which include at least a CPU, a display and I/O. The client device can be a PC, a mobile phone, a netbook, a PDA, etc. In one embodiment, the network executing on the game server recognizes the type of device used by the client and adjusts the communication method employed. In other cases, client devices use a standard communications method, such as html, to access the application on the game server over the internet.
It should be appreciated that a given video game or gaming application may be developed for a specific platform and a specific associated controller device. However, when such a game is made available via a game cloud system as presented herein, the user may be accessing the video game with a different controller device. For example, a game might have been developed for a game console and its associated controller, whereas the user might be accessing a cloud-based version of the game from a personal computer utilizing a keyboard and mouse. In such a scenario, the input parameter configuration can define a mapping from inputs which can be generated by the user's available controller device (in this case, a keyboard and mouse) to inputs which are acceptable for the execution of the video game.
In another example, a user may access the cloud gaming system via a tablet computing device, a touchscreen smartphone, or other touchscreen driven device. In this case, the client device and the controller device are integrated together in the same device, with inputs being provided by way of detected touchscreen inputs/gestures. For such a device, the input parameter configuration may define particular touchscreen inputs corresponding to game inputs for the video game. For example, buttons, a directional pad, or other types of input elements might be displayed or overlaid during running of the video game to indicate locations on the touchscreen that the user can touch to generate a game input. Gestures such as swipes in particular directions or specific touch motions may also be detected as game inputs. In one embodiment, a tutorial can be provided to the user indicating how to provide input via the touchscreen for gameplay, e.g. prior to beginning gameplay of the video game, so as to acclimate the user to the operation of the controls on the touchscreen.
In some embodiments, the client device serves as the connection point for a controller device. That is, the controller device communicates via a wireless or wired connection with the client device to transmit inputs from the controller device to the client device. The client device may in turn process these inputs and then transmit input data to the cloud game server via a network (e.g. accessed via a local networking device such as a router). However, in other embodiments, the controller can itself be a networked device, with the ability to communicate inputs directly via the network to the cloud game server, without being required to communicate such inputs through the client device first. For example, the controller might connect to a local networking device (such as the aforementioned router) to send to and receive data from the cloud game server. Thus, while the client device may still be required to receive video output from the cloud-based video game and render it on a local display, input latency can be reduced by allowing the controller to send inputs directly over the network to the cloud game server, bypassing the client device.
In one embodiment, a networked controller and client device can be configured to send certain types of inputs directly from the controller to the cloud game server, and other types of inputs via the client device. For example, inputs whose detection does not depend on any additional hardware or processing apart from the controller itself can be sent directly from the controller to the cloud game server via the network, bypassing the client device. Such inputs may include button inputs, joystick inputs, embedded motion detection inputs (e.g. accelerometer, magnetometer, gyroscope), etc. However, inputs that utilize additional hardware or require processing by the client device can be sent by the client device to the cloud game server. These might include captured video or audio from the game environment that may be processed by the client device before sending to the cloud game server. Additionally, inputs from motion detection hardware of the controller might be processed by the client device in conjunction with captured video to detect the position and motion of the controller, which would subsequently be communicated by the client device to the cloud game server. It should be appreciated that the controller device in accordance with various embodiments may also receive data (e.g. feedback data) from the client device or directly from the cloud gaming server.
It should be understood that the various embodiments defined herein may be combined or assembled into specific implementations using the various features disclosed herein. Thus, the examples provided are just some possible examples, without limitation to the various implementations that are possible by combining the various elements to define many more implementations. In some examples, some implementations may include fewer elements, without departing from the spirit of the disclosed or equivalent implementations.
Embodiments of the present disclosure may be practiced with various computer system configurations including hand-held devices, microprocessor systems, microprocessor-based or programmable consumer electronics, minicomputers, mainframe computers and the like. Embodiments of the present disclosure can also be practiced in distributed computing environments where tasks are performed by remote processing devices that are linked through a wire-based or wireless network.
Although the method operations were described in a specific order, it should be understood that other housekeeping operations may be performed in between operations, or operations may be adjusted so that they occur at slightly different times or may be distributed in a system which allows the occurrence of the processing operations at various intervals associated with the processing, as long as the processing of the telemetry and game state data for generating modified game states and are performed in the desired way.
One or more embodiments can also be fabricated as computer readable code on a computer readable medium. The computer readable medium is any data storage device that can store data, which can be thereafter be read by a computer system. Examples of the computer readable medium include hard drives, network attached storage (NAS), read-only memory, random-access memory, CD-ROMs, CD-Rs, CD-RWs, magnetic tapes and other optical and non-optical data storage devices. The computer readable medium can include computer readable tangible medium distributed over a network-coupled computer system so that the computer readable code is stored and executed in a distributed fashion.
Although the foregoing embodiments have been described in some detail for purposes of clarity of understanding, it will be apparent that certain changes and modifications can be practiced within the scope of the appended claims. Accordingly, the present embodiments are to be considered as illustrative and not restrictive, and the embodiments are not to be limited to the details given herein, but may be modified within the scope and equivalents of the appended claims.
Claims
- A method for displaying voice input of a spectator in a video game, comprising: receiving, by a server, the voice input produced by the spectator while viewing video game video of the video game;examining, by the server, the voice input to identify speech characteristics associated with the voice input of the spectator;processing, by the server, the voice input to generate a spectator video that includes text images representing the voice input of the spectator, the text images are configured to be adjusted in visual appearance based on the speech characteristics of the voice input, wherein the text images are directed in a field of view of an avatar of the spectator;combining, by the server, the video game video with the spectator video to produce an overlay of the text images graphically moving in toward a game scene provided by the video game video;and sending, to a client device, a spectator video stream that includes the overlay of the text images;wherein the speech characteristics identify intensity in the voice input and the intensity is configured to cause changes in weighting of the text images, wherein weighting sets an impact said text images have with objects in the game scene.
- The method of claim 1, wherein the intensity is configured to cause changes in size of the text images.
- The method of claim 1, wherein the speech characteristics further identify mood in the voice input.
- The method of claim 3, wherein the mood in the voice input is processed to set a color change in said text images.
- The method of claim 1, wherein the text images are additionally adjusted in speed when caused to graphically move in toward the game scene.
- The method of claim 1, wherein the text images are additionally adjusted in a fade-time when caused to graphically move in toward the game scene.
- The method of claim 1, wherein the spectator video stream includes a plurality of overlays that graphically illustrate a plurality of text images directed toward the game scene, the plurality of text images are processed to float toward the game scene from a plurality of locations associated with avatars viewing the game scene.
- The method of claim 7, wherein each of the text images represent words, and each word having one or more letters, and wherein each of the one or more letters are caused to independently float toward the game scene.
- The method of claim 8, wherein the one or more letters are associated with a physics parameter that enables said one or more letters to graphically impact an object of the game scene.
- The method of claim 9, wherein said impact of the object of the game scene by said one or more letters is adjustable based on a weighting parameter associated to respective ones of said text images.
- The method of claim 1, wherein in addition to the voice input from the spectator, further comprising: receiving, by the server, a plurality of voice inputs from a plurality of spectators;examining, by the server, the plurality of voice inputs to identify corresponding speech characteristics of the plurality of spectators;processing, by the server, the plurality of voice inputs to produce corresponding text images directed in a field of view of respective avatars of the plurality of spectators;combining, the video game video with spectator video from the plurality of spectators to produce overlays of the text images;and sending, to a plurality of clients, the spectator video stream that includes the overlays from the plurality of spectators.
- The method of claim 1, further comprising: generating, by the server, a player video that includes the text images representing the voice input of the spectator;combining, by the server, the video game video with the player video;and sending, to a device of a player, a player video stream that includes the video game video with the player video.
- A method for displaying a plurality of voice inputs of a plurality of spectators of a video game, comprising: receiving, by a server, the plurality of voice inputs produced by the plurality of spectators;examining, by the server, the plurality of voice inputs to identify corresponding speech characteristics of the plurality of spectators;processing, by the server, the plurality of voice inputs to generate a spectator video that includes corresponding text images directed a field of view of respective avatars of the plurality of spectators;combining, video game video with the spectator video to produce overlays of the corresponding text images;and sending, to a plurality of client devices, a spectator video stream that includes the overlays of the corresponding text images;wherein the corresponding text images represent words spoken by the plurality of spectators, each word having one or more letters, and wherein each letter caused to independently float toward a game scene provided by the video game video.
- The method of claim 13, wherein the speech characteristics identify intensity in the plurality of voice inputs, said intensity to cause changes in size of the corresponding text images.
- The method of claim 13, wherein the corresponding text images are configured to be adjusted in visual appearance based on the corresponding speech characteristics of the plurality of spectators.
- The method of claim 13, wherein the corresponding speech characteristics identify mood in the in the plurality of voice inputs, said mood is processed to set a color change in said corresponding text images.
- The method of claim 13, wherein each of the one or more letters is associated with a physics parameter that enables the one or more letters to graphically impact an object in the game scene.
- A method for displaying voice input of a spectator in a video game, comprising: receiving, by a server, the voice input produced by the spectator while viewing video game video of the video game;examining, by the server, the voice input to identify speech characteristics associated with the voice input of the spectator;processing, by the server, the voice input to generate a spectator video that includes text images representing the voice input of the spectator, the text images are configured to be adjusted in visual appearance based on the speech characteristics of the voice input, wherein the text images are directed in a field of view of an avatar of the spectator;associating, by the server, the video game video with the spectator video to enable generation of an overlay of the text images graphically moving in toward a game scene provided by the video game video;and enabling a client device of the spectator to render a spectator video stream that includes the video game video along with the overlay of the text images;wherein the video game video is received by the client device of the spectator and then receives the overlay of the text images to enable locally rendering of the spectator video stream at the client device.
- The method of claim 18, wherein the client device is sent by the server the association of the video game video and the spectator video to enable the client device to render the spectator video stream.
Disclaimer: Data collected from the USPTO and may be malformed, incomplete, and/or otherwise inaccurate.