U.S. Pat. No. 10,001,970
DIALOG SERVER FOR HANDLING CONVERSATION IN VIRTUAL SPACE METHOD AND COMPUTER PROGRAM FOR HAVING CONVERSATION IN VIRTUAL SPACE
AssigneeActivision Publishing, Inc.
Issue DateJanuary 12, 2017
Illustrative Figure
Abstract
A dialog server which provides dialogs made by at least one user through their respective avatars in a virtual space. A method and a computer readable article of manufacture tangibly embodying computer readable instructions for executing the steps of the method are also provided. The dialog server includes: a position storage unit which stores positional information on the avatars; an utterance receiver which receives at least one utterance of avatars and utterance strength representing an importance or attention level of the utterance; an interest level calculator which calculates interest levels between avatars based on their positional information; a message processor which generates a message based on the utterance in accordance with a value calculated from the interest levels and the utterance strength; and a message transmitter which transmits the message to the avatars.
Description
DETAILED DESCRIPTION OF THE PREFERRED EMBODIMENTS A description of preferred embodiments of the present invention follows with reference to the drawings. The term “virtual space” in the context of the present invention means a collection of data in which background scenery and objects each having a position and a direction are arranged. The term “avatar” means an object associated with a user as a character representing the user in a virtual space. “Utterance strength” is a value indicating deliverability of an utterance, and represents, for example, a voice volume of the utterance. It is also an importance level of the utterance for an avatar making the utterance, and further, it is an attention level of the utterance for an avatar receiving the utterance. The utterance strength is attached to an utterance by an avatar making the utterance. “Interest level” is defined herein as being a value indicating utterance deliverability between two avatars, and automatically calculated in accordance with a positional relationship including each direction from one avatar to the other and a distance between the avatars. If a certain avatar makes an utterance, the dialog server can transmit a content of the utterance to each of other avatars as a message in accordance with a value calculated from the utterance strength and the interest levels of the certain avatar to the each of other avatars and of the each of other avatars to the certain avatar. As a result, an utterance of an avatar is delivered to another avatar in accordance with a value which is calculated from interest levels automatically calculated from positions of the avatars and utterance strength of the utterance. Thus, the dialog server can provide a smooth communication using a conversation in a virtual space where a large number of users participate. If a certain avatar ...
DETAILED DESCRIPTION OF THE PREFERRED EMBODIMENTS
A description of preferred embodiments of the present invention follows with reference to the drawings.
The term “virtual space” in the context of the present invention means a collection of data in which background scenery and objects each having a position and a direction are arranged. The term “avatar” means an object associated with a user as a character representing the user in a virtual space.
“Utterance strength” is a value indicating deliverability of an utterance, and represents, for example, a voice volume of the utterance. It is also an importance level of the utterance for an avatar making the utterance, and further, it is an attention level of the utterance for an avatar receiving the utterance. The utterance strength is attached to an utterance by an avatar making the utterance.
“Interest level” is defined herein as being a value indicating utterance deliverability between two avatars, and automatically calculated in accordance with a positional relationship including each direction from one avatar to the other and a distance between the avatars.
If a certain avatar makes an utterance, the dialog server can transmit a content of the utterance to each of other avatars as a message in accordance with a value calculated from the utterance strength and the interest levels of the certain avatar to the each of other avatars and of the each of other avatars to the certain avatar. As a result, an utterance of an avatar is delivered to another avatar in accordance with a value which is calculated from interest levels automatically calculated from positions of the avatars and utterance strength of the utterance. Thus, the dialog server can provide a smooth communication using a conversation in a virtual space where a large number of users participate.
If a certain avatar makes an utterance, the dialog server can transmit the utterance to each of other avatars when a value calculated from the utterance strength and the interest levels of the certain avatar to the each of other avatars and of the each of other avatars to the certain avatar is not less than a predetermined value. As a result, an utterance of an avatar is delivered to another avatar when a value which is calculated from interest levels automatically calculated from positions of the avatars and utterance strength of the utterance is not less than a predetermined value. Thus, the dialog server can provide a smooth communication using a conversation in a virtual space where a large number of users participate.
Referring toFIG. 1, a functional block diagram showing a configuration of a dialog server as an example of an embodiment of the present invention is provided. A dialog server10receives utterance data and utterance strength data transmitted by a speaker-user terminal21via an utterance receiver11. The utterance data can be either text data or sound data. The utterance strength data indicates deliverability of an utterance of a speaker to a listener. For example, the utterance strength data can indicate a value designated by a speaker, as data separate from the utterance data, or can indicate voice volume of the utterance of sound data.
Dialog server10also receives positional information data transmitted by the speaker-user terminal21or the listener-user terminal22, through a position receiver12. The positional information data indicates the positions of avatars respectively representing one or more speakers and one or more listeners in a virtual space. For example, the positional information data includes an avatars' coordinate information in the virtual space and an avatars' facing directions.
A position storage unit13stores the received positional information on the avatars of the speakers and listeners. If the position storage unit13has already stored any positional information, it updates the stored positional information, and stores the updated positional information. The interest level calculator15reads the positional information stored in the position storage unit13, and calculates the interest levels of the speakers to the listeners and interest levels of the listeners to the speakers from the positional relationships between the avatars of the speakers and listeners.
An utterance strength calculator14calculates the utterance strength from either the utterance data or the utterance strength data received from the utterance receiver11. For example, in the case where the utterance strength data indicates a value designated and inputted by a speaker, as data separate from the utterance data, the value can be normalized to be made into the utterance strength. In the case where the utterance strength data indicates voice volume of the utterance of sound data, the voice volume can be normalized to be made into the utterance strength.
Message processor16processes the utterance in accordance with the interest levels calculated by the interest level calculator15and the utterance strength calculated by the utterance strength calculator14, and thereby generates a message. For example, in generating the message, the message processor16can change the font size or the sound volume of the utterance in accordance with the interest levels and the utterance strength. Alternatively, message processor16can generate a message from the utterance only when a value calculated from the interest levels and the content of the utterance exceeds a certain threshold value.
Message transmitter17transmits the generated message to the listener-user terminal22. The position transmitter18reads the positional information on the avatars of both the speakers and listeners stored in the position storage unit13, and transmits the information to the speaker-user terminal21and the listener-user terminal22, as positional information data.
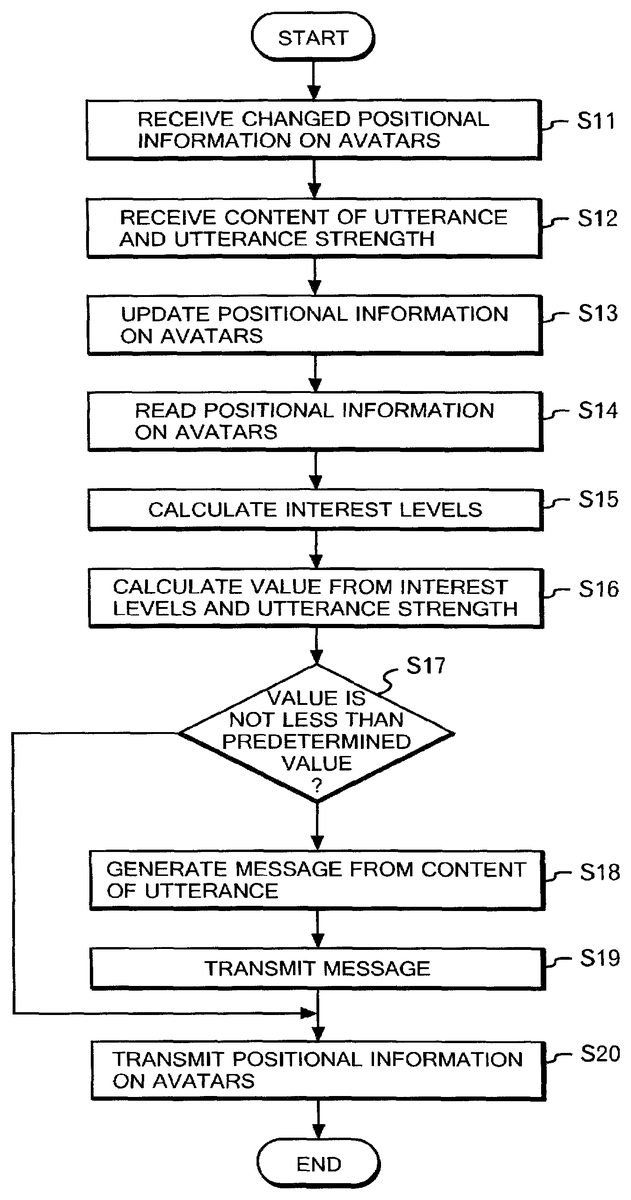
FIG. 2is a flowchart showing a processing flow of the dialog server10according to an embodiment of the present invention. The dialog server10receives positional information data on avatars of one or more speakers and one or more listeners in a virtual space (step S11), as well as utterance data and utterance strength data of each speaker (step S12).
In step S13, the dialog server10updates positional information on the avatars of speakers and listeners based on the positional information data received in step S11. Thereafter, the dialog server10reads the updated positional information on the avatars of the speakers and listeners (step S14), and calculates the interest levels based on the updated positional information on the avatars of the speakers and listeners (step S15).
In step S16, dialog server10calculates a value from both the interest levels of the avatars of the speakers and listeners and the utterance strength calculated from the utterance strength data received in step S12. Thereafter, dialog server10determines whether or not the calculated value is not less than a predetermined value (step S17). If the calculated value is not less than the predetermined value, the processing proceeds to step S18. If the calculated value is less than the predetermined value, the processing proceeds to step S20.
In step S18, dialog server10generates a message from the content of the utterance received in step S12. Thereafter, the dialog server10transmits the generated message (step S19). In step S20, the dialog server10transmits, as positional information data, positional information on the avatars which is updated in step S13.
FIG. 3is a perspective view showing a positional relationship between avatars of a speaker and a listener used for calculating an interest level in an embodiment of the present invention. An interest level Ijof an avatar Aito an avatar Ajin a virtual space is defined as shown in the following expression (1):
Iij=dcosθL[Expression1]
where θ is an angle made by a facing direction of the avatar Aiand a straight line connecting positions of the respective avatars Aiand Aj, and L is a distance between the avatars Aiand Aj. Here, d is a term for normalizing an interest level of a speaker or a listener to satisfy the following expression (2):
∑j=lnIi,j=1[Expression2]
where n is the number of avatars who exist in a circular region whose center is the position of the avatar Aiand whose radius riis a predetermined distance.
FIGS. 4-1 to 7-5illustrate Example 1 of the present invention.FIG. 4-1is a perspective view showing three avatars A, B and Ch sitting around a circular table in a virtual space. A, B and Ch sit in the positions located at the same distance from the center of the table while facing the center of the table. More specifically, straight lines connecting the center of the table and the respective positions of A, B and Ch are 120.degree. of each other.
FIG. 4-2shows A's view. A faces the midpoint between B and Ch.FIG. 4-3shows B's view. B faces the midpoint between A and Ch.FIG. 4-4shows Ch's view. Ch faces the midpoint between A and B.
FIG. 4-5is a table summarizing interest levels between A, B and Ch. A, B and Ch sit at respective vertices of an equilateral triangle, so that the distances between A, B and Ch are the same. Since each of the avatars A, B and Ch face the midpoint of the opposite side of this equilateral triangle, the facing direction of each avatar and the directions from the avatar to the other respective avatars are at the same angle, in this case, 30.degree. From above expressions (1) and (2), the interest levels between A, B and Ch are set to the same value. It is assumed that an utterance of one avatar is delivered to another as a message, if an interest level from the latter avatar to the former avatar is not less than 0.5. Accordingly, in the situation shown inFIG. 4-5, an utterance of any of the avatars is delivered to the other avatars as messages.
FIG. 5-1is a perspective view showing a situation subsequent toFIG. 4-1. Ch speaks while A and B look at Ch.FIG. 5-2shows A's view. A looks at Ch.FIG. 5-3shows B's view. B looks at Ch.FIG. 5-4shows Ch's view. Ch faces the midpoint between A and B.
FIG. 5-5is a table summarizing interest levels between A, B and Ch. A and B look at Ch. Accordingly, the interest levels of A to Ch and B to Ch has increased, while the interest levels of A to B and B to A has decreased. The facing direction of Ch remains unchanged from the situation shown inFIG. 4, so that the interest levels of Ch to A and Ch to B also remain unchanged from that situation.
In the situation shown inFIG. 5-5, A's utterances are delivered to Ch as messages, but not to B. Similarly, B's utterances are delivered to Ch as messages, but are not to A. On the other hand, Ch's utterances are delivered to both A and B as messages. These conditions allow only Ch's utterances to be delivered to A and B as messages. Accordingly, A and B can hear only the Ch's utterances as messages.
FIG. 6-1is a perspective view showing a situation subsequent toFIG. 5-1. B speaks to Ch, and Ch faces a point closer to B than the midpoint between A and B. A and B look at Ch.FIG. 6-2shows A's view. A looks at Ch.FIG. 6-3shows B's view. B looks at Ch.FIG. 6-4shows Ch's view. Ch faces the point closer to B than the midpoint between A and B.
FIG. 6-5is a table summarizing interest levels between A, B and Ch. A and B look at Ch as similar to the situation shown inFIG. 5. Accordingly, the interest levels of A to Ch, B to Ch, A to B and B to A remain unchanged from the situation shown inFIG. 5. Ch faces the point closer to B than the midpoint between A and B, so that the interest level of Ch to B has increased over the situation shown inFIG. 5, while the interest level of Ch to A has decreased as compared to the situation shown inFIG. 5.
In the situation shown inFIG. 6-5, A's utterances are not delivered to Ch or B. B's utterances are delivered to Ch as messages, but not to A. Similarly, Ch's utterances are delivered to B as messages, but not to A. These conditions allow Ch and B to have a conversation without being interrupted by any A's utterance, while preventing A from being disturbed by any of B's personal questions.
FIG. 7-1is a perspective view showing a situation subsequent toFIG. 6-1. Ch speaks to A, while facing a point closer to A than the midpoint between A and B. A and B look at Ch.FIG. 7-2shows A's view. A looks at Ch.FIG. 7-3shows B's view. B looks at Ch.FIG. 7-4shows Ch's view. Ch faces the point closer to A than the midpoint between A and B.
FIG. 7-5is a table summarizing interest levels between A, B and Ch. A and B look at Ch similar to the situation shown inFIG. 6. Accordingly, the interest levels of A to Ch, B to Ch, A to B and B to A remain unchanged from the situation shown inFIG. 6. Ch faces the point closer to A than the midpoint between A and B, so that the interest level of Ch to A has increased over the situation shown inFIG. 6, while the interest level of Ch to B has decreased as compared to the situation shown inFIG. 6.
In the situation shown inFIG. 7-5, A's utterances are delivered to Ch as messages, but not to B. B's utterances are not delivered to Ch or A. In addition, Ch's utterances are delivered to A as messages, but not to B. InFIG. 7-2, dialog between Ch and B is exchanged. This dialog is sequentially reproduced to be delivered to A as messages. This allows A to trace the content of the conversation between Ch and B, and accordingly allows Ch to deliver B's valuable remarks to A while preventing B from hearing what has already been said to B. This sequential reproduction can be deactivated by either A or Ch.
In the above Example 1, an interest level of each avatar calculated from the positional information of avatars is a value that becomes larger as (1) the direction from one avatar becomes closer to the direction of another avatar or (2) as the avatar stands closer to another avatar. Afterwards, it is determined whether or not to deliver an utterance of the avatar to the certain avatar as a message based on the calculated interest level. Accordingly, whether or not to deliver an utterance as a message can be automatically chosen in accordance with positions of the avatars.
As mentioned in Example 1, when the avatar acquires only a low interest level, certain dialogs are not delivered to an avatar as messages. Even in this case, if the message delivery is resumed in response to the fact that the avatar acquires a high interest level, the undelivered messages can be sequentially delivered to the avatar. In that event, the user of the avatar can choose whether or not to hear the undelivered messages.
FIGS. 8-1 to 8-3are perspective views each showing a positional relationship between avatars of a speaker and a listener used for determining whether or not to deliver an utterance as a message in another embodiment of the present invention. Specifically, such determination is made based on a scale value calculated from interest levels and a voice volume of the utterance.FIG. 8-1is a perspective view showing a positional relationship between avatars Aiand Aiin a virtual space. A condition under which an As utterance is delivered to A1as a message is defined on the basis of a preset threshold level TH as shown in the following expression (3):
Ii,j=dicosθiLIj,i=djcosθjLIi,j×pi+Ij,i>TH[Expression3]
where θiis an angle made by the facing direction of Aiand a straight line connecting positions of Aiand Aj. θjis an angle made by a facing direction of Ajand a straight line connecting positions of Aiand Aj. L is a distance between the avatars Aiand Aj, and piis a voice volume of the Ai's utterance. Here, diand djare terms used for the normalization mentioned previously.
FIG. 8-2is a perspective view showing a situation where the avatar Aispeaks to the avatar A2at a voice volume level p1. In this case, the following result is obtained instead of the expression (3):
l1,2=d1cosθ1Ll2,1=d2cosθ2Ll1,2×pi+l2,1≦TH[Expression4]
This means that this situation does not satisfy the condition defined in the expression (3), and thus A1's utterances are not delivered to A2as messages. Accordingly, the displayed image of A2is darkened to indicate that A1's messages are not delivered to A2.
li,j=dicosθiLlj,i=djcosθjLli,j×pi+lj,i>TH
FIG. 8-3is a perspective view showing a situation where the avatar A1speaks to the avatar A2at a voice volume level p2. In this case, the following result is obtained instead of the expression (3):
l1,2=dicosθ1Ll2,1=d2cosθ2Ll1,2×p2+l2,1>TH[Expression5]
This means that this situation satisfies the condition defined in Expression 3, and thus A1's utterances are delivered to A2as messages. Accordingly, the displayed image of A2returns to normal indicating that A1's messages are delivered to A2.
FIGS. 9-1 to 16-4illustrate Example 2, which is another embodiment of the present invention.FIG. 9-1is a perspective view showing seven avatars A to F and Ch sitting around a rectangular table in a virtual space. Among A to F, three avatars sit at one longer side of the table and the remaining three avatars sit at the other longer side of the table. More specifically, the avatars at each side sit at regular intervals while facing the avatars at the other side. Ch sits at a shorter side of the table while facing in a direction perpendicular to the facing directions of A to F.
FIG. 9-2shows Ch's view. A to F sit at the longer sides of the tables while A, and E face B, D and F, respectively. Ch sits at the midpoint of the shorter side which is closer to A and B facing each other while facing the midpoint of the opposite side.FIG. 9-3shows C's view. D who faces C is seen in front of C, B who faces A is seen at a position closer to Ch, and F who faces E is seen at a position more distant from Ch.FIG. 9-4shows F's view. E who faces F is seen in front of F, and C who faces D is seen at a position closer to Ch.
FIG. 10-1is a perspective view showing a situation subsequent toFIG. 9-1. A to F and Ch face the same direction as in the situation shown inFIG. 9-1, and speak with a normal voice volume.FIG. 10-2shows Ch's view. Since A and B sit closer to Ch, their utterances with a normal voice volume satisfy the condition defined in the expression (3), and thus are delivered to Ch as messages. On the other hand, since C to F sit farther from Ch, their utterances with a normal voice volume do not satisfy the condition defined in the expression (3), and thus are not delivered to Ch as messages. Similarly, since C to F sit farther from Ch, Ch's utterances with a normal voice volume do not satisfy the condition defined in the expression (3), and thus are not delivered to Ch as messages. Accordingly, the display images of C to F are darkened in the Ch's view as shown inFIG. 10-2.
FIG. 10-3shows C's view. Utterances with a normal voice volume of B, D and F are delivered to C as messages. Since each of B, D and F is regarded as sitting at a distance and in a direction from C which allow C's utterances with a normal voice volume to be delivered to the each of B, D and F as messages, the display images of B, D and F are normal in C's view.FIG. 10-4shows F's view. Utterances of E and C are delivered to F as messages. Since both E and C are regarded as sitting at a distance and in a direction from F which allow F's utterances with a normal voice volume to be delivered to the each of E and C as messages, the display images of E and C are normal in the F's view.
FIG. 11-1is a perspective view showing a situation subsequent toFIG. 10-1. Ch faces the same direction as in the situation shown inFIG. 10-1, and speaks with a voice louder than normal.FIG. 11-2shows Ch's view. Ch speaks with the louder voice, and thus Ch's message is even delivered to C to F. Accordingly, the display images of C to F which are darkened in the situation shown inFIG. 10now become normal in Ch's view.
FIG. 11-3shows C's view. Ch speaks with the louder voice, and thus Ch's message is delivered to C even though Ch is out of the C's view.FIG. 11-4shows F's view. Ch speaks with the louder voice, and thus Ch's message is delivered to F even though Ch is out of the F's view.
FIG. 12-1is a perspective view showing a situation subsequent toFIG. 11-1. Since Ch's utterance with the louder voice in the situation shown inFIG. 11-1is delivered to A to F as a message, all the avatars look at Ch now. Ch faces the same direction as in the situation shown inFIG. 11-1, and speaks with a normal voice volume.
FIG. 12-2shows Ch's view. Ch speaks with a normal voice volume. A to F are looking directly at Ch. Accordingly, even though C to F are regarded as sitting at a distance and in a direction from Ch which normally can not allow Ch's utterances with a normal voice volume to be delivered to C to F as messages, C to F are regarded as sitting at a distance and in a direction from Ch which allow Ch's utterances with a normal voice volume to be delivered to C to F as messages. Therefore the display images of C to F are normal inFIG. 10-2.
FIG. 12-3shows C's view. C looks at Ch. Accordingly, C is regarded to sit at a distance and in a direction from Ch which allow Ch's utterances with a normal voice volume to be delivered to C as messages, and thus the display image of Ch is normal in the C's view. Ch's utterances with a normal voice volume are delivered to C as messages. A looks at Ch and the direction from C to A is some degrees away from the facing direction of C. Accordingly, A is regarded to sit at a distance and in a direction from C which allow none of C's utterances with a normal voice volume to be delivered to A as messages. Thus, the display image of A is darkened in the C's view as shown inFIG. 12-3.
FIG. 12-4shows F's view. F looks at Ch. Accordingly, F is regarded to sit at a distance and in a direction from Ch which allow Ch's utterances with a normal voice volume to be delivered to F as messages, and thus the display image of Ch is normal in the F's view. Ch's utterances with a normal voice volume are delivered to F as messages. A and B look at Ch and the directions from F to A and to B are some degrees away from the facing direction of F. Accordingly, A and B are regarded as sitting at a distance and in a direction from F which allow none of F's utterances with a normal voice volume to be delivered to A or B as messages. Thus, the display images of A and B are darkened in the F's view as shown inFIG. 12-4.
FIG. 13-1is a perspective view showing a situation subsequent toFIG. 12-1. Ch faces the same direction as in the situation shown inFIG. 12-1, and speaks with a normal voice volume. A to E look at Ch while F looks at C. F speaks to C with a normal voice volume.
FIG. 13-2shows Ch's view. Ch speaks with a normal voice volume, and A to E look at Ch. Accordingly, A to E are regarded as sitting at a distance and in a direction from Ch which allow Ch's utterances with a normal voice volume to be delivered to A to E as messages, and thus the display images of A to E are normal in the Ch's view. F looks at C. Accordingly, F is regarded as sitting at a distance and in a direction from Ch which allow none of Ch's utterances with a normal voice volume to be delivered to F as messages, and thus the display image of F is darkened in the Ch's view.
FIG. 13-3shows C's view. C looks at Ch. Accordingly, C is regarded to sit at a distance and in a direction from Ch which allow Ch's utterances with a normal voice volume to be delivered to C as messages, and thus Ch's utterances with a normal voice volume are delivered to C as messages. F looks at C. Accordingly, C is regarded as sitting at a distance and in a direction from F which allow F's utterances with a normal voice volume to be delivered to C as messages, and thus F's utterance with a normal voice volume is delivered to C as a message.
A looks at Ch and the direction from C to A is some degrees away from the facing direction of C. Accordingly, A is regarded as sitting at a distance and in a direction from C which allow none of C's utterances with a normal voice volume to be delivered to A as messages. Thus, the display image of A is darkened in the C's view.
FIG. 13-4shows F's view. Since F looks at C, F is regarded as sitting at a distance and in a direction from C which allow C's utterances with a normal voice volume, if they were, to be delivered to F as messages. Thus, the display image of C is normal in the F's view. A and E look at Ch and the directions from F to A and to E are some degrees away from the facing direction of F. Accordingly, A and E are regarded as sitting at a distance and in a direction from F which allow none of F's utterances with a normal voice volume to be delivered to A or E as messages. Thus, the display images of A and E are darkened in the F's view. These conditions allow F's utterances referring to earlier discussion to be delivered only to C selected by F as one to whom these utterances should be delivered as messages, while preventing A, B, D, E and Ch from hearing the utterances. This allows F to express opinions without interrupting the discussion on the table.
FIG. 14-1is a perspective view showing a situation subsequent to that ofFIG. 13-1. Ch faces the same direction as in the situation shown inFIG. 13-1, and speaks with a normal voice volume. A, B, D and E look at Ch, while F looks at C and speaks to C with a normal voice volume. Since F's utterance in the situation shown inFIG. 13is delivered to C as a message, C looks at F now.
FIG. 14-2shows Ch's view. Ch speaks with a normal voice volume while A, B, D and E look at Ch. Accordingly, A, B, D and E are regarded as sitting at a distance and in a direction from Ch which allow Ch's utterances with a normal voice volume to be delivered to A, B, D and E as messages, and thus the display images of A, B, D and E are normal in the Ch's view. F and C look at each other. Accordingly, C and F are regarded to sit at a distance and in a direction from Ch which allow none of Ch's utterances with a normal voice volume to be delivered to the C or F as messages, and thus the display images of C and F are darkened in the Ch's view.
FIG. 14-3shows C's view. Since C and F look at each other, F is regarded as sitting at a distance and in a direction from C which allow C's utterances with a normal voice volume to be delivered to F as messages. Accordingly, the display image of F is normal in the C's view. F's utterances with a normal voice volume are delivered to C as messages. On the other hand, D looks at Ch and the direction from C to D is some degrees away from the facing direction of C. Accordingly, D is regarded as sitting at a distance and in a direction from C which allow none of C's utterances with a normal voice volume to be delivered to D as messages. Thus, the display image of D is darkened in the C's view.
FIG. 14-4shows F's view. Since C and F look at each other, C is regarded as sitting at a distance and in a direction from F which allow F's utterances with a normal voice volume, if they were, to be delivered to C as messages. Thus, the display image of C is normal in the F's view. A and E look at Ch and the directions from F to A and F to E are some degrees away from the facing direction of F. Accordingly, A and E are regarded as sitting at a distance and in a direction from F which allow none of F's utterances with a normal voice volume to be delivered to the A or E as messages. Thus, the display images of A and E are darkened in the F's view.
C and F who face each other can see no other normal display images of avatars. Accordingly, C's utterances and F's utterances with a normal voice volume are not delivered to the avatars other than C and F, as messages. This allows C and F to discuss a topic different from one being discussed by all the avatars on the table without interrupting the discussion on the table.
FIG. 15-1is a perspective view showing a situation subsequent to that ofFIG. 14-1. Ch faces the same direction as in the situation shown inFIG. 14-1, and speaks with a normal voice volume. A to E look at Ch. Among the avatars, C speaks with a normal voice volume while looking at Ch. F looks at C.
FIG. 15-2shows Ch's view. C speaks to Ch with a normal voice volume, and A to E look at Ch. Accordingly, A to E are regarded as sitting at a distance and in a direction from Ch which allow Ch's utterances with a normal voice volume to be delivered to A to E as messages, and thus the display images of A to E are normal in the Ch's view. Since F looks at C, none of Ch's utterances with a normal voice volume is delivered to F as messages. Accordingly, the display image of F is darkened in the Ch's view. In this event, as in Example 1, dialogs between C and F can be sequentially reproduced. C and Ch can be allowed to choose whether or not to reproduce these dialogs.
FIG. 15-3shows C's view. Since C looks at Ch, Ch is regarded as sitting at a distance and in a direction from C which allow C's utterances with a normal voice volume to be delivered to Ch as messages. Accordingly, the display image of Ch is normal in the C's view. Ch's utterance with a normal voice volume is delivered to C as a message. On the other hand, A looks at Ch and the direction from C to A is some degrees away from the facing direction of C. Accordingly, A is regarded as sitting at a distance and in a direction from C which allow none of C's utterances with a normal voice volume to be delivered to A as messages. Thus, the display image of A is darkened in the C's view.
FIG. 15-4shows F's view. Since F looks at C, F is regarded as sitting at a distance and in a direction from C which allow F's utterances with a normal voice volume to be delivered to C as messages. Thus, the display image of C is normal in the F's view. Even though C speaks while looking at Ch, the distance between F and C is small enough and F looks at C. Accordingly, C is regarded as sitting at a distance and in a direction from F which allow C's utterances with a normal voice volume, if they were, to be delivered to F as messages.
C's utterance with a normal voice volume is delivered to F as a message. On the other hand, A and E look at Ch and the directions from F to A and F to E are some degrees away from the facing direction of F. Accordingly, A and E are regarded as sitting at a distance and in a direction from F which allow none of F's utterances with a normal voice volume to be delivered to the each of A and E as messages. Thus, the display images of A and E are darkened in the F's view.
FIG. 16-1is a perspective view showing a situation subsequent to that ofFIG. 15-1. Ch, who has received C's utterance as a message, faces the same direction as in the situation shown inFIG. 15-1, and speaks on the message delivered from C with a normal voice volume. A to F look at Ch.
FIG. 16-2shows Ch's view. Ch speaks with a normal voice volume, and A to F look at Ch. Accordingly, A to F are regarded as sitting at a distance and in a direction from Ch which allow Ch's utterances with a normal voice volume to be delivered to the each of A to F as messages, so that the display images of A to F are normal in the Ch's view. Ch's utterances with a normal voice volume are delivered to C as messages. In this event, as mentioned previously in Example 1, the dialog between C and F can be delivered to A to F as messages and be sequentially reproduced. A to F and Ch can be allowed to stop reproducing these messages.
FIG. 16-3shows C's view. Ch speaks with a normal voice volume while C looks at Ch. Accordingly, C is regarded as sitting at a distance and in a direction from Ch which allow Ch's utterances with a normal voice volume to be delivered to C as messages, so that Ch's messages are delivered to C. A looks at Ch and the direction from C to A is some degrees away from the facing direction of C. Accordingly, A is regarded as sitting at a distance and in a direction from C which allow none of C's utterances with a normal voice volume to be delivered to A as messages. Thus, the display image of A is darkened in the C's view.
FIG. 16-4shows F's view. Ch speaks with a normal voice volume while F looks at Ch. Accordingly, F is regarded as sitting at a distance and in a direction from Ch which allow Ch's utterances with a normal voice volume to be delivered to F as messages, so that Ch's messages are delivered to F. A and B look at Ch and the directions from F to A and to B are some degrees away from the facing direction of F. Accordingly, A and B are regarded as sitting at a distance and in a direction from F which allow none of F's utterances with a normal voice volume to be delivered to the each of A and B as messages. Thus, the display images of A and B are darkened in the F's view.
As mentioned previously in Example 1, whether or not to deliver an utterance as a message is determined according to the interest levels of speaker's avatar and listener's avatar, each of which is automatically determined on the basis of each direction from one to the other and a distance between the avatars. By contrast, as mentioned previously in Example 2, a voice volume of an utterance is set as utterance strength in addition to such interest levels. Thus, if a value obtained from the utterance strength and the interest levels exceeds a predetermined threshold value, the corresponding utterance is delivered to the listener's avatar as a message. Accordingly, whether or not to deliver an utterance as a message can be determined by a method similar to that in real-world conversation. This allows a user of an avatar representing himself/herself to automatically select to which avatar to deliver an utterance as a message, only by causing the user's avatar to behave in a virtual space as if it were in the real world, more specifically, to appropriately move and to speak with an appropriate voice volume.
FIG. 17shows an example of a hardware configuration of an information processor100as a typical example of a hardware configuration of the dialog server10, the speaker-user terminal21and the listener-user terminal22described in theFIG. 1. The information processor100includes a central processing unit (CPU)1010, a bus line1005, a communication I/F1040, a main memory1050, a basic input output system (BIOS)1060, a parallel port1080, an USB port1090, graphics controller1020, a VRAM1024, an audio processor1030, an I/O controller1070, and input means including a keyboard and a mouse adapter and the like1100. To the I/O controller1070, the storage means including a flexible disk (FD) drive1072, a hard disk1074, an optical disk drive1076and a semiconductor memory1078can be connected. An amplification circuit1032and a speaker1034are connected to the audio processor1030. A display1022is connected to the graphics controller1020.
The BIOS1060stores a boot program that the CPU1010executes at the time of the boot-lip of the information processor100, a program dependent on the hardware of the information processor100. The FD drive1072reads a program or data from the flexible disk1071, to provide it to the main memory1050or the hard disk1074through the I/O controller1070.
As the optical disk drive1076, for example, a DVD-ROM drive, a CD-ROM drive, a DVD-RAM drive and a CD-RAM drive can be employed. Note that an optical disk1077supported in the employed drive needs to be used. The optical disk drive1076can read a program or data from the optical disk1077to provide it to the main memory1050or the hard disk1074through the I/O controller1070.
Each computer program to be provided to the information processor100is provided by a user in the form of being stored in a recording medium, such as the flexible disk1071, the optical disk1077or a memory card. The provided computer program is read out from the recording medium through the I/O controller1070, or is downloaded through the communication I/F1040, and thereby is installed in and executed by the information processor100. The operations that the computer program causes the information processor100to perform are the same as those in the aforementioned devices, and accordingly the description thereof will be omitted.
The above computer programs can be stored in an external recording medium. The recording medium used here can be the flexible disk1071, the optical disk1077or a memory card, or can alternatively be a magneto-optical recording medium such as an MD or a tape medium. Furthermore, the recording medium used here can be a storage device, such as a hard disk or an optical disk library, which is provided in a server system connected to a dedicated communication network or the Internet. In this case, the computer program can be provided to the information processor100through a communication network.
The above description has been given mainly of the hardware configuration example of the information processor100. However, it is possible to implement the functionality similar to that of the aforementioned information processor by installing, onto a computer, a program providing the functionality described as that of the information processor, and thus causing the computer to operate as the information processor. Accordingly, the information processor described as an embodiment of the present invention can alternatively be implemented by a method or a computer program thereof.
Each device of the present invention can be implemented as hardware, software, or a combination of hardware and software. A typical example of such implementation as a combination of hardware and software is a computer system including a predetermined program. In such a case, by being loaded and executed on the computer system, the predetermined program causes the computer system to perform processing according an embodiment of the present invention.
The program is composed of a group of instructions which can be written in any language, codes, or notations. Such a group of instructions allow the system to directly execute specific functions, or to execute the specific functions after (1) the instructions are converted into different language, codes or notations, and/or (2) the instructions are copied to a different medium.
The scope of the present invention includes not only such a program itself, but also program products, such as a medium storing the program therein. The program for executing the functions of the present invention can be stored in any computer readable medium, such as a flexible disk, an MO, a CD-ROM, a DVD, a hard disk device, a ROM, an MRAM, and a RAM. Specifically, this program can be stored in the computer readable medium by being downloaded to the medium in a computer system from another computer system connected thereto through a communication line, or by being copied from a different medium.
The program can either be compressed and, thereafter stored in a single recording medium or be divided into pieces and stored in multiple recording media.
Although the present invention has been described by use of the embodiment, the invention is not limited to these embodiments. The effects described in the embodiment of the present invention are merely a list of the most preferable effects provided by the present invention, and the effects of the present invention are not limited to those described in the embodiment or the examples of the present invention.
Claims
- A method comprising the steps of: storing positional information on at least a first avatar and a second avatar;receiving (i) at least one utterance from said first avatar and (ii) at least one utterance strength representing an importance or attention level of said at least one utterance;calculating at least one interest level between said first avatar and said second avatar based on said positional information;when a value calculated from said at least one interest level and said at least one utterance strength is not less than a predetermined threshold value, generating at least one message from said at least one utterance in accordance with the value and transmitting said at least one message to said second avatar;and when the value is less than a predetermined threshold value, generating the at least one message from the at least one utterance in accordance with the value, not delivering the at least one message to the second avatar while the value is less than the predetermined threshold value, and delivering the at least one message to the second avatar once the value is at least equal to the predetermined threshold value, wherein the at least one interest level of the first avatar and the second avatar are normalized relative to a plurality of interest levels associated with avatars present within a predetermined radius from at least one of the first avatar and the second avatar.
- The method of claim 1 wherein the positional information is data that becomes larger as the direction from the first avatar becomes closer to the direction of the second avatar or as the first avatar stands closer to the second avatar.
- The method of claim 1 further comprising delivering the at least one message to the second avatar once the value is at least equal to the predetermined threshold value only if a user of the second avatar chooses to receive the at least one message.
- The method of claim 1 wherein an appearance of the at least one message is based on at least one of the utterance strength level and the interest level.
- The method of claim 1 wherein the utterance strength is a value indicating deliverability of the at least one utterance.
- The method of claim 5 wherein the utterance strength is a voice volume of the at least one utterance.
- The method of claim 1 , wherein text data of the at least one message is generated from the at least one utterance such that the text data is displayed in a form varying in accordance with at least one of the interest level and the utterance strength.
- The method of claim 7 wherein the varying of said form comprises increasing a font size of the text data in a first case, as compared to a second case, when at least one of the interest level and the utterance strength is greater in said first case than in said second case.
- The method of claim 1 wherein the at least one interest level is a function of an angle made by a facing direction of the first avatar relative to a straight line connecting position of the first avatar and second avatar.
- The method of claim 9 wherein the at least one interest level is a function of said angle divided by a distance between the first avatar and the second avatar.
- The method of claim 9 further comprising normalizing the function relative to a plurality of interest levels associated with avatars present within a predetermined radius from the first avatar.
- The method of claim 1 wherein the at least one interest level is a function of an angle formed by a facing direction of the first avatar relative to a straight line connecting position of the first avatar and second avatar and a distance between the first avatar and the second avatar and wherein said function is normalized relative to a plurality of interest levels associated with avatars present within a predetermined radius from the first avatar.
- The method of claim 1 wherein the value is a function of an interest level of the first avatar, an interest level of the second avatar, and a volume of the at least one utterance.
- The method of claim 1 further comprising calculating the value by multiplying an interest level of the first avatar by a volume of the at least one utterance and adding an interest level of the second avatar.
- The method of claim 1 when the value calculated from said at least one interest level and said at least one utterance strength is not less than a predetermined threshold value, a display of the second avatar to the first avatar is not darkened.
- The method of claim 1 when the value calculated from said at least one interest level and said at least one utterance strength is less than a predetermined threshold value, a display of the second avatar to the first avatar is darkened.
- The method of claim 1 further comprising a third avatar, calculating a second interest level between the first avatar and the third avatar based on positional information, calculating a second value from the second interest level, and comparing said second value to the predetermined threshold value.
- The method of claim 17 wherein if said value is equal to or greater than the predetermined threshold value and said second value is less than the predetermined threshold value, delivering the at least one message to the second avatar and not the third avatar and wherein if said value is less than the predetermined threshold value and said second value is equal to or greater than the predetermined threshold value, delivering the at least one message to the third avatar and not the second avatar.
Disclaimer: Data collected from the USPTO and may be malformed, incomplete, and/or otherwise inaccurate.